Le but du Concurrent Pascal
Le but du Concurrent Pascal est de fournir un environnement de programmation conçu pour le développement de systèmes d'exploitation et d'applications en temps réel nécessitant une gestion efficace de la concurrence. Conçu par Per Brinch Hansen dans les années 1970, ce langage de programmation étend le lanage de programmation Pascal en introduisant des mécanismes de synchronisation et de communication entre processus, comme les monitors, les processus, et les ressources partagées.
Les principales motivations de Concurrent Pascal incluent :
- Sécurité de la concurrence : Le Concurrent Pascal vise à prévenir les erreurs courantes dans la programmation concurrente, telles que les conditions de course (race conditions) et les impasses (deadlocks), en encapsulant la gestion de la concurrence au sein de constructions du langage de programmation.
- Simplicité et clarté : En intégrant directement les concepts de synchronisation dans le langage de programmation, le Concurrent Pascal permet une gestion plus claire et plus structurée des interactions entre processus, réduisant ainsi la complexité du code.
- Support pour le développement de systèmes : Il a été conçu pour permettre aux programmeurs de développer des systèmes d'exploitation et d'autres logiciels critiques en temps réel avec des garanties de sûreté et de cohérence dans l'exécution concurrente.
L'arrière scène
En 1972, Per Brinch Hansen a travaillé sur un nouveau langage de programmation pour la programmation structurée des systèmes d'exploitation informatiques. Ce langage s'appelait Concurrent Pascal. Il étendait le langage de programmation séquentielle Pascal avec des outils de programmation simultanée appelés processus et moniteurs (Wirth 1971 ; Brinch Hansen 1973 ; Hoare 1974).
Il s'agit d'une description informelle de Concurrent Pascal. Elle utilisait des exemples, des images et des mots pour faire ressortir les aspects créatifs des nouveaux concepts de programmation sans entrer dans leurs détails les plus fins. Il prévoyait de définir ces concepts avec précision et d'introduire une notation pour eux dans des articles ultérieurs. Cette forme de présentation peut être imprécise d'un point de vue formel, mais est peut-être plus efficace d'un point de vue humain.
Processus
Nous allons étudier les processus concurrents au sein d'un système d'exploitation et nous pencherons sur un seul petit problème : comment de grandes quantités de données peuvent-elles être transmises d'un processus à un autre au moyen de tampons entreposés sur un disque ?
La figure suivante montre ce petit système et ses trois composantes : un processus produisant des données, un processus consommant des données et un tampon de disque les reliant :
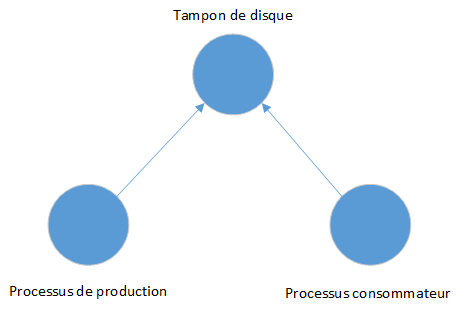
Les cercles représentent les composantes du système et les flèches les droits d'accès de ces composantes. Ils montrent que les deux processus peuvent utiliser le tampon (mais ils ne montrent pas que les données circulent du producteur au consommateur). Ce type d'image est un graphique d'accès.
L'image suivante montre une composante de processus plus en détail :

Un processus est constitué d'une structure de données privée et d'un programme séquentiel pouvant opérer sur les données. Un processus ne peut pas opérer sur les données privées d'un autre processus. Mais des processus concurrents peuvent partager certaines structures de données (comme un tampon de disque). Les droits d'accès d'un processus mentionnent les données partagées sur lesquelles il peut opérer :
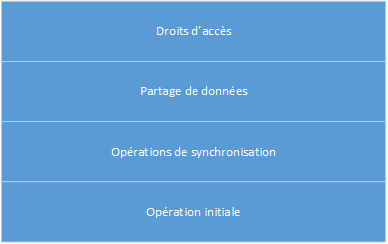
Un moniteur définit une structure de données partagée et toutes les opérations que les processus peuvent effectuer sur celle-ci. Ces opérations de synchronisation sont appelées procédures de surveillance. Un moniteur définit également une opération initiale étant exécutée lors de la création de sa structure de données.
Nous pouvons définir un tampon de disque comme un moniteur. Dans ce moniteur, il y aura des variables partagées définissant l'emplacement et la longueur du tampon sur le disque. Il y aura également deux procédures de surveillance, send et receive. L'opération initiale garantira que le tampon démarre comme vide.
Les processus ne peuvent pas fonctionner directement sur des données partagées. Ils ne peuvent appeler que des procédures de surveillance ayant accès aux données partagées. Une procédure de surveillance est exécutée dans le cadre d'un processus appelant (comme toute autre procédure).
Si des processus concurrents appellent simultanément des procédures de surveillance opérant sur les mêmes données partagées, ces procédures seront exécutées strictement une à la fois. Sinon, les résultats des appels de surveillance seraient imprévisibles. Cela signifie que la machine doit être capable de retarder les processus pendant de courtes périodes de temps jusqu'à ce que ce soit leur tour d'exécuter les procédures de surveillance. Nous ne nous intéresserons pas à la manière dont cela se fait, mais nous remarquerons simplement qu'une procédure de surveillance a un accès exclusif aux données partagées pendant son exécution.
Ainsi, la machine (virtuelle) sur laquelle s'exécutent les programmes concurrents gérera la planification à court terme des appels de surveillance simultanés. Mais le programmeur doit également être capable de retarder les processus pendant des périodes plus longues si leurs demandes de données et d'autres ressources ne peuvent pas être satisfaites immédiatement. Si, par exemple, un processus essaie de recevoir des données d'un tampon de disque vide, il doit être retardé jusqu'à ce qu'un autre processus envoie plus de données.
Le Concurrent Pascal comprend un type de données simple, appelé file d'attente, pouvant être utilisé par les procédures de surveillance pour contrôler la planification à moyen terme des processus. Un moniteur peut soit retarder un processus appelant dans une file d'attente, soit continuer un autre processus attendant dans une file d'attente. Il n'est pas important de comprendre ici le fonctionnement de ces files d'attente, à l'exception de la règle essentielle suivante : un processus n'a un accès exclusif aux données partagées que tant qu'il continue à exécuter des instructions dans une procédure de surveillance. Dès qu'un processus est retardé dans une file d'attente, il perd son accès exclusif jusqu'à ce qu'un autre processus appelle le même moniteur et le réveille à nouveau. (Sans cette règle, il serait impossible d'entrer dans un moniteur et de laisser les processus en attente continuer leur exécution.)
Bien que l'exemple du tampon de disque ne le montre pas encore, les procédures de moniteur devraient également pouvoir appeler des procédures définies dans d'autres moniteurs. Sinon, le langage ne sera pas très utile pour la conception hiérarchique. Dans le cas du tampon de disque, l'un de ces autres moniteurs pourrait peut-être définir des opérations d'entrée/sortie simples sur le disque. Ainsi, un moniteur peut également avoir des droits d'accès à d'autres composants du système (voir l'image précédente).
Conception du système
Un processus exécute un programme séquentiel : c'est un composant actif. Un moniteur est simplement un ensemble de procédures ne faisant rien tant qu'elles ne sont pas appelées par des processus : c'est une composante passif. Mais il existe de fortes similitudes entre un processus et un moniteur : tous deux définissent une structure de données (privée ou partagée) et les opérations significatives y étant effectuées. La principale différence entre les processus et les moniteurs réside dans la manière dont ils sont planifiés pour être exécutés.
Il semble donc naturel de considérer les processus et les moniteurs comme des types de données abstraits définis en termes d'opérations pouvant être effectuées sur eux. Si un compilateur peut vérifier que ces opérations sont les seules effectuées sur les structures de données, nous pourrons alors créer des programmes concurrents très fiables dans lesquels l'accès contrôlé aux données et aux ressources physiques est garanti avant que ces programmes ne soient mis en ouvre. Nous aurons ainsi résolu dans une certaine mesure le problème de la protection des ressources de la manière la plus économique possible (sans mécanismes matériels ni temps d'exécution supplémentaire).
Nous allons donc définir les processus et les moniteurs comme des types de données et permettre l'utilisation de plusieurs instances du même type de composante dans un système. Nous pouvons, par exemple, utiliser deux tampons de disque pour construire un système de mise en file d'attente avec un processus d'entrée, un processus de travail et un processus de sortie :
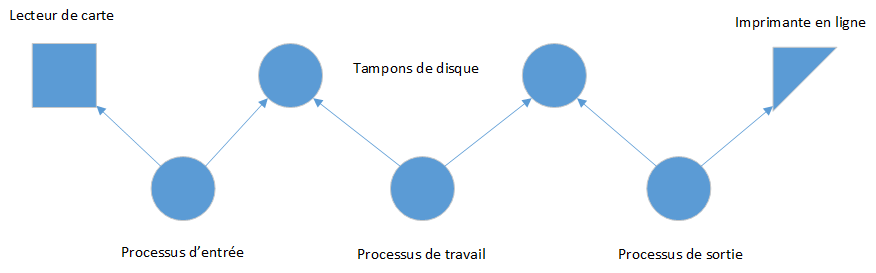
On distingue les définitions et les instances de composantes en les appelant types de système et composantes de système. Les graphiques d'accès (tels que l'image précédente) afficheront toujours les composantes du système (et non les types de système).
Les périphériques sont considérés comme des moniteurs implémentés dans le matériel. Ils ne sont accessibles que par une seule procédure d'entrée/sortie retardant le processus appelant jusqu'à ce qu'une opération d'entrée/sortie soit terminée. Les interruptions sont gérées par la machine virtuelle sur laquelle les processus s'exécutent.
Pour que le langage de programmation soit utile pour la conception de systèmes par étapes, il doit permettre la division d'un type de système, tel qu'un tampon de disque, en types de système plus petits. L'un de ces autres types de système doit donner à un tampon de disque l'accès au disque. Nous appellerons ce type de système un disque virtuel. Il donne à un tampon de disque l'illusion qu'il possède son propre disque privé. Un disque virtuel cache les détails de l'entrée/sortie du disque au reste du système et fait ressembler le disque à une structure de données (un tableau de pages de disque). Les seules opérations sur cette structure de données sont la lecture et l'écriture d'une page.
Chaque disque virtuel n'est utilisé que par un seul tampon de disque :
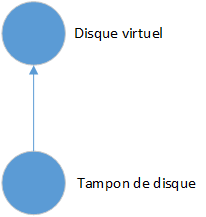
Une composante système ne pouvant pas être appelé simultanément par plusieurs autres composantes sera appelé une classe. Une classe définit une structure de données et les opérations possibles sur celle-ci (tout comme un moniteur). L'accès exclusif des procédures de classe aux variables de classe peut être entièrement garanti au moment de la compilation. La machine virtuelle n'a pas besoin de planifier des appels simultanés de procédures de classe au moment de l'exécution, car de tels appels ne peuvent pas se produire. Cela rend les appels de classe considérablement plus rapides que les appels de moniteur.
Le système de file d'attente comprend deux disques virtuels mais un seul disque réel. Nous avons donc besoin d'un seul moniteur de ressources de disque pour contrôler l'ordre dans lequel les processus concurrents utilisent le disque :
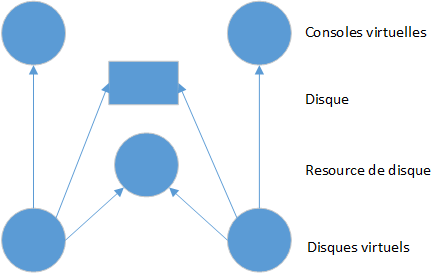
Ce moniteur définit deux procédures, demande et libération d'accès, devant être appelées par un disque virtuel avant et après chaque transfert de disque.
Il semblerait plus simple de remplacer les disques virtuels et la ressource disque par un seul moniteur ayant un accès exclusif au disque et effectuant les entrées/sorties. Cela garantirait certainement que les processus utilisent le disque un par un. Mais cela se ferait selon la politique de planification à court terme intégrée des appels de moniteur.
Pour rendre une machine virtuelle efficace, il faut utiliser une règle de planification à court terme très simple, comme le premier arrivé, premier servi (Brinch Hansen 1973). Si le disque a une tête d'accès mobile, c'est à peu près le pire algorithme possible que l'on puisse utiliser pour les transferts de disque. Il est essentiel que le langage de programmation permette au programmeur d'écrire un algorithme de planification à moyen terme minimisant le mouvement de la tête du disque (Hoare 1974). La file d'attente de types de données mentionnée précédemment permet d'implémenter des règles de planification arbitraires au sein d'un moniteur.
La difficulté est que, pendant qu'un moniteur exécute une opération d'entrée/sortie, il est impossible pour d'autres processus d'entrer dans le même moniteur et de rejoindre la file d'attente du disque. Ils seront automatiquement retardés par le planificateur à court terme et ne seront autorisés à entrer dans le moniteur qu'un par un après chaque transfert de disque. Cela rendra, bien sûr, illusoire la tentative de contrôler la planification du disque dans le moniteur. Pour donner au programmeur un contrôle complet de la planification du disque, les processus doivent pouvoir entrer dans la file d'attente du disque pendant les transferts de disque. Comme l'arrivée et le service dans le système de mise en file d'attente du disque sont potentiellement des opérations simultanées, elles doivent être traitées par des composantes système différents, comme le montre l'image précédente.
Si le disque tombe en panne de manière persistante pendant l'entrée/sortie, cela doit être signalé sur la console d'un opérateur. L'image précédente montre deux instances d'un type de classe, appelé console virtuelle. Elles donnent aux disques virtuels l'illusion qu'ils ont leurs propres consoles privées.
Les consoles virtuelles obtiennent un accès exclusif à une seule console réelle en appelant un moniteur de ressources de console :

Notez que nous disposons désormais d'une technique standard pour gérer les périphériques virtuels.
Si nous rassemblons tous ces composantes du système, nous obtenons une image complète d'un système de file d'attente simple :
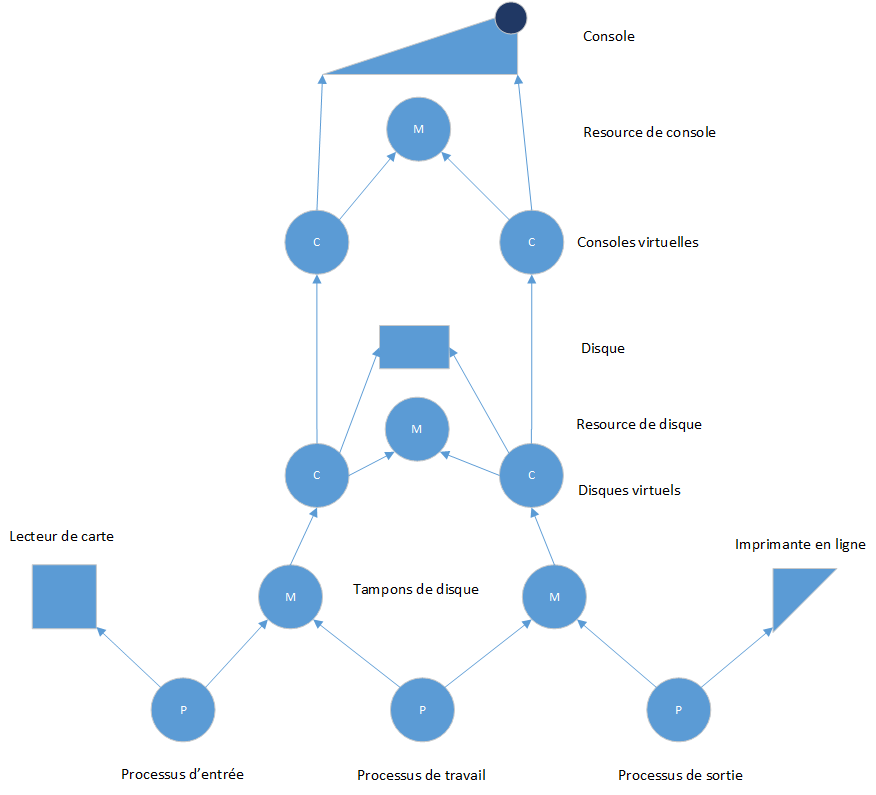
Les classes, les moniteurs et les processus sont marqués C, M et P.
Règles de portée
Au début des années 1970, Per Brinch Hansen faisais partie d'une équipe ayant construit un système multiprogrammation dans lequel les processus peuvent apparaître et disparaître dynamiquement (Brinch Hansen 1970). En pratique, ce système était principalement utilisé pour mettre en place une configuration fixe de processus. La suppression dynamique de processus compliquera certainement considérablement la sémantique et l'implémentation d'un langage de programmation. Et comme elle semble inutile pour une grande classe d'applications en temps réel, il semble judicieux de l'exclure complètement. Ainsi, un système d'exploitation écrit en Concurrent Pascal sera constitué d'un nombre fixe de processus, de moniteurs et de classes. Ces composantes et leurs structures de données existeront pour toujours après l'initialisation du système. Un système d'exploitation peut cependant être étendu par recompilation. Il reste à voir si cette restriction simplifiera ou compliquera la conception du système d'exploitation. Mais la mauvaise qualité de la plupart des systèmes d'exploitation existants dans les années 1970 démontre clairement un besoin urgent d'approches plus simples.
Dans les langages de programmation existants, les structures de données des processus, des moniteurs et des classes seraient appelées «données globales». Ce terme serait trompeur dans Concurrent Pascal où chaque structure de données n'est accessible que par une seule composante. Il semble plus approprié de les appeler structures de données permanentes.
Un compilateur peut détecter bon nombre d'erreurs si les processus et les moniteurs sont représentés par une notation structurée dans un langage de programmation de haut niveau. De plus, on devons exclure les fonctionnalités de machine de bas niveau (registres, adresses et interruptions) du langage et laisser une machine virtuelle les contrôler. Si nous voulons que les systèmes en temps réel soient très fiables, nous devons arrêter de les programmer en langage de programmation assembleur. (L'utilisation de mécanismes de protection matérielle n'est qu'un moyen coûteux et inadéquat de faire en sorte que des programmes en langage machine arbitraires se comportent presque aussi prévisiblement que des programmes compilés.)
Un compilateur Concurrent Pascal vérifiera que les données privées d'un processus sont uniquement accessibles par ce processus. Il vérifie également que la structure de données d'une classe ou d'un moniteur n'est accessible que par ses procédures. L'image précédente montre que les droits d'accès au sein d'un système d'exploitation ne sont normalement pas structurés en arbre. Ils forment plutôt un graphe orienté. Cela explique en partie pourquoi les règles de portée traditionnelles des langages de programmation structurés en blocs sont peu pratiques pour la programmation concurrente (et aussi pour la programmation séquentielle). En Concurrent Pascal, on peut indiquer les droits d'accès des composantes dans le texte du programme et les faire vérifier par un compilateur.
Étant donné que l'exécution d'une procédure de moniteur retarde l'exécution d'appels ultérieurs du même moniteur, nous devons empêcher un moniteur de s'appeler lui-même de manière récursive. Sinon, les processus peuvent se retrouver bloqués. Le compilateur vérifie donc que les droits d'accès des composantes du système sont ordonnés hiérarchiquement (ou, si vous préférez, qu'il n'y a pas de cycles dans le graphe d'accès). L'ordre hiérarchique des composantes du système a des conséquences vitales pour la conception et les tests du système (Brinch Hansen 1974).
Un système d'exploitation hiérarchique sera testé composante par composante, de bas en haut (mais pourrait bien sûr être conçu de haut en bas ou par itération). Lorsqu'un système d'exploitation incomplet a démontré qu'il fonctionne correctement (par preuve ou par test), un compilateur peut garantir que cette partie du système continuera à fonctionner correctement lorsque de nouvelles composantes de programme non testés seront ajoutés par-dessus. Les erreurs de programmation dans les nouvelles composantes ne peuvent pas entraîner l'échec des anciennes composantes car les anciens composantes n'appellent pas les nouvelles composantes, et les nouvelles composantes n'appellent les anciens composantes que par le biais de procédures bien définies ayant déjà été testées.
À proprement parler, un compilateur ne peut vérifier que les appels de moniteur simples sont effectués correctement; il ne peut pas vérifier les séquences d'appels de moniteur, par exemple si une ressource est toujours réservée avant d'être libérée. On ne peut donc espérer qu'une garantie de correction partielle au moment de la compilation. Plusieurs autres raisons, outre la correction du programme, rendent une structure hiérarchique attrayante :
- Un système d'exploitation hiérarchique peut être étudié de manière progressive comme une séquence de machines abstraites simulées par des programmes (Dijkstra 1971).
- Un ordre partiel des interactions des processus permet d'utiliser l'induction mathématique pour prouver certaines propriétés globales du système, telles que l'absence de blocages (Brinch Hansen 1973).
- Une utilisation efficace des ressources peut être obtenue en ordonnant les composants du programme en fonction de la vitesse des ressources physiques qu'ils contrôlent, les ressources les plus rapides étant contrôlées en bas du système (Dijkstra 1971).
- Un système hiérarchique conçu selon les critères précédents est souvent presque décomposable d'un point de vue analytique. Cela signifie que l'on peut développer des modèles stochastiques de son comportement dynamique de manière progressive (Simon 1962).