



Fonctionnalités liées au disque
Le DISK BASIC fournit un ensemble puissant de commandes, d'instructions et de fonctions relatives aux entrées/sorties disque sous TRSDOS. Ceux-ci se répartissent en deux catégories :
- Manipulation de fichiers : traiter les fichiers comme des unités, plutôt que les enregistrements distincts que contiennent les fichiers.
- Accès aux fichiers : préparation des fichiers de données pour les entrées/sorties ; lecture et écriture dans les fichiers.
Voici les commandes discutées sous «Manipulation de fichiers» :
| Nom | Description |
|---|---|
| KILL | Cette commande permet de supprimer un programme ou un fichier de données du disque |
| LOAD | Cette commande permet de charger un programme BASIC du disque. |
| MERGE | Cette commande permet de fusionner un programme BASIC au format ASCII sur disque avec un programme actuellement en RAM. |
| RUN"program" | Cette commande permet de charger et exécuter un BASIC. |
| SAVE | Cette commande permet d'enregistrer le programme BASIC résident sur le disque. |
Instruction et fonctions décrites sous «Accès aux fichiers»
Instructions
| Nom | Description |
|---|---|
| OPEN | Cette instruction permet d'ouvrir un dossier pour y accéder (créer puis dossier si nécessaire) |
| CLOSE | Cette instruction permet de fermer l'accès au dossier |
| INPUT # | Cette instruction permet de lire à partir du disque, mode séquentiel |
| LINE INPUT # | Cette instruction permet de lire une ligne a de données, mode séquentiel |
| PRINT # | Cette instruction permet d'écrire sur disque, mode séquentiel |
| GET | Cette instruction permet la lecture à partir du disque, mode d'accès aléatoire |
| PUT | Cette instruction permet d'écrire sur le disque, mode d'accès aléatoire |
| FIELD | Cette instruction permet d'attribuer des tailles et des noms de champ au mode d'accès aléatoire |
| LSET | Cette instruction permet de placer la valeur dans le champ tampon spécifié, ajouter des blancs à droite pour remplir le champ |
| RSET | Cette instruction permet de placer la valeur dans le champ tampon spécifié, ajouter des blancs à gauche pour remplir le champ |
Fonctions
| Nom | Description |
|---|---|
| CVD | Cette fonction permet de restaurer le nombre à double précision sous forme numérique après l'avoir obtenu à partir du disque. |
| CVI | Cette fonction permet de restaurer l'entier sous forme numérique après avoir obtenu le disque. |
| CVS | Cette fonction permet de restaurer le nombre simple précision sous forme numérique après l'avoir obtenu à partir du disque. |
| EOF | Cette fonction permet de vérifier si une fin de fichier a été rencontrée lors de la lecture. |
| LOF | Cette fonction permet de retourner le numéro du dernier enregistrement du fichier. |
| MKD$ | Cette fonction permet de convertir un nombre double précision en chaîne de caractères afin qu'il puisse être PUT sur le disque. |
| MKI$ | Cette fonction permet de convertir un entier en chaîne de caractères pour qu'il puisse être PUT sur le disque. |
| MKS$ | Convertit un nombre simple précision en chaîne afin qu'il puisse être PUT sur le disque. |
Manipulation de fichiers
KILL |
Supprimer un fichier du disque |
|---|---|
| DISK BASIC | |
Syntaxe
| KILL exp$ |
Paramètres
| Nom | Description |
|---|---|
| exp$ | Ce paramètre permet de définir une spécification de fichier pour un fichier existant. |
Description
Cette commande fonctionne comme la commande KILL du TRSDOS.
Exemple
KILL"OLDFILE/BAS.PSW1"
supprime le fichier spécifié du premier unité de disque le contenant.
Ne supprimer pas un fichier ouvert, ou vous risquez de détruire le contenu de la disquette. (Utilisé CLOSE d'abord sur le fichier ouvert.)
LOAD |
Charge un fichier du disque |
|---|---|
| DISK BASIC | |
Syntaxe
| LOAD exp$[,R] |
Paramètres
| Nom | Description |
|---|---|
| exp$ | Ce paramètre permet de définir une spécification de fichier pour un fichier de programme BASIC entreposé sur le disque. |
| R | Ce paramètre permet de dire à BASIC d'exécuter (RUN) le programme après son chargement. |
Description
La commande charge un fichier de programme BASIC dans la RAM ; si l'option R est utilisée, BASIC procédera à l'exécution automatique du programme ; sinon, BASIC reviendra au mode de commande.
Le LOAD sans l'option R efface tout programme BASIC résident, efface toutes les variables et ferme tous les fichiers ouverts. LOAD avec l'option R supprime le programme résident et efface toutes les variables, mais ne ferme pas les fichiers ouverts.
Le LOAD avec l'option R équivaut à la commande RUN exp$,R. L'une ou l'autre de ces commandes peut être utilisée à l'intérieur des programmes pour permettre l'enchaînement des programmes - un programme en appelant un autre,...
Si vous tentez de charger un fichier non BASIC, une instruction directe dans le fichier ou une erreur de format de chargement se produira.
Exemples
LOAD"PROG1/BAS:2"
Efface le programme BASIC résident et charge PROG1/BAS à partir de l'unité de disque 2 ; revient au mode de commande BASIC.
Exemple d'enchaînement de deux programmes :
10 REM...INSTRUCTIONS
Le premier peut être utilisé pour donner des instructions puis pour charger la partie travail du programme.
1000 LOAD"PROG2/BAS",R
(PROG2/BAS). Notez que la ligne 1000 est équivalente à 100 RUN "PROG2/BAS".
MERGE |
Fusionne le programme du disque avec le programme résident |
|---|---|
| DISK BASIC | |
Syntaxe
| MERGE exp$ |
Paramètres
| Nom | Description |
|---|---|
| exp$ | Ce paramètre permet de définir une spécification de fichier pour un fichier de disque BASIC au format ASCII, par exemple un programme enregistré avec l'option A. |
Description
MERGE est similaire à LOAD - sauf que le programme résident n'est pas effacé avant que le nouveau programme exp$ ne soit chargé. Au lieu de cela, exp$ est fusionné dans le programme résident.
C'est-à-dire que les lignes de programme dans exp$ seront simplement insérées dans le programme résident dans un ordre séquentiel. Si les numéros de ligne dans exp$ coïncident avec les numéros de ligne dans le programme résident, les lignes résidentes seront remplacées par celles de exp$.

MERGE offre un moyen pratique d'assembler des programmes modulaires. Par exemple, un ensemble souvent utilisé de sous-programmes BASIC peut être suivi sur une variété de programmes avec cette commande.
Par exemple, supposons que le programme suivant est en RAM :
10 REM... PROGRAMME PRINCIPAL
20 GOSUB 1000
30 REM... PLUS DE LIGNE DE PROGRAMMES ICI
999 END
1000 REM... BESOIN D'AJOUTER DES SOUS-ROUTINES ICI
1010 REM... ALORS, UTILISEZ LA COMMANDE DE FUSION
1020 PRINT"SOUS-ROUTINE NON-DISPONIBLE":RETURN
Et supposons que le programme suivant soit entreposé sur disque au format ASCII :
1000 REM... DEBUT DE SOUS-ROUTINE
1010 PRINT"EXECUTE UNE SOUS-ROUTINE..."
1020 REM... PLUS DE LIGNES DE PROGRAMME
1100 RETURN
En supposant que le programme de sous-programme est nommé SUB/TXT, alors nous pourrions le MERGE avec l'instruction :
MERGE"SUB/TXT"
et le programme résultant en RAM serait :
10 REM... PROGRAMME PRINCIPAL
20 GOSUB 1000
30 REM... PLUS DE LIGNE DE PROGRAMMES ICI
999 END
1000 REM... DEBUT DE SOUS-ROUTINE
1010 PRINT"EXECUTE UNE SOUS-ROUTINE..."
1020 REM... PLUS DE LIGNES DE PROGRAMME
1100 RETURN
Notez que MERGE ferme tous les fichiers et efface toutes les variables. À la fin, BASIC revient au mode de commande.
RUN"program" |
Charge et exécute un programme du disque |
|---|---|
| DISK BASIC | |
Syntaxe
| RUN exp$[,R] |
Paramètres
| Nom | Description |
|---|---|
| exp$ | Ce paramètre permet d'indiquer de définir la spécification de fichier pour un programme BASIC entreposé sur disque. |
| R | Ce paramètre permet de laisser les fichiers déjà ouvert encore ouvert. |
Description
Si l'option R n'est pas sélectionnée, tous les fichiers ouverts seront fermés.
Lorsque la commande est exécutée, tout programme BASIC résident sera remplacé par le programme contenu dans exp$.
Exemples
| RUN"DISKDUMP/BASENTER |
Charge et exécute le programme de vidage de secteur BASIC.
Supposons que vous sauvegardiez le programme suivant sur disque sous le nom "PROG1/BAS" :
10 PRINT"EXECUTION DU PROG1..."
20 RUN"PROG2/BAS"
Et enregistrez ce programme sur disque sous le nom "PROG2/BAS" :
10 PRINT"EXECUTION DU PROG2..."
20 RUN"PROG1/BAS"
Tapez maintenant :
| RUN"PROG1/BASENTER |
et vous verrez un exemple simple d'enchaînement de programmes. Maintenez la touche BREAK enfoncée pour interrompre la chaîne de caractères de programmes.
SAVE |
Enregistrer le programme sur le disque |
|---|---|
| DISK BASIC | |
Syntaxe
| SAVE exp$[,A] |
Paramètres
| Nom | Description |
|---|---|
| exp$ | Ce paramètre permet de définir le nom de fichier et l'extension facultative, le mot de passe et l'unité de disque à utiliser. Si le nom de fichier existe déjà, son contenu précédent sera perdu lors de la recréation du fichier. |
| A | Ce paramètre permet d'entraîner le tri du fichier en ASCII plutôt qu'en format compressé. |
Description
Cette commande vous permet de sauvegarder vos programmes BASIC sur disque. Vous pouvez enregistrer le programme au format compressé ou ASCII.
L'utilisation du format compressé occupe moins d'espace disque et est plus rapide lors de la sauvegarde et du chargement. C'est ainsi que les programmes BASIC sont entreposés dans la RAM.
L'utilisation de l'option ASCII permet de faire certaines choses ne pouvant pas être faites avec des fichiers BASIC au format compressé.
Exemples :
- La commande MERGE nécessite que le fichier disque soit au format ASCII.
- Vous pouvez utiliser les commandes LIST et PRINT du TRSDOS avec des fichiers au format ASCII.
- Les programmes lus dans d'autres programmes en tant que données nécessitent généralement que les programmes de données soient entreposés en ASCII.
Conventions utiles pour placer des extensions sur les programmes BASIC : Pour les programmes au format compressé, utilisez l'extension /BAS. Pour les programmes au format ASCII, utilisez l'extension /TXT.
Exemples
SAVE"FILE1/BAS.JOHNQDOE:3"
enregistrer le programme BASIC résident au format compressé avec le nom de fichier FILE1, extension /BAS, mot de passe. JOHNQDOE; le fichier est placé sur l'unité de disque :3.
SAVE"MATHPAK/TXT",A
enregistrer le programme résident sous forme ASCII, sous le nom MATHPAK/TXT, sur le premier unité de disque non protégé en écriture.
À la fin d'un SAVE, le BASIC revient en mode commande.
Accès du fichier
Cette section est divisée en quatre parties :
- Création de fichiers et affectation de tampons - OPEN et CLOSE.
- Déclarations et fonctions
- Techniques d'entrée/sortie séquentielles.
- Techniques d'entrée/sortie aléatoires.
Création de fichiers et affectation de tampons
Pendant la boîte de dialogue d'initialisation, vous tapez un nombre en réponse à HOW MANY FILES? Le nombre que vous tapez indique à BASIC combien de tampons créer pour gérer vos accès disque (lectures et écritures).
Chaque tampon reçoit un numéro de 1 à 15. Si vous tapez :
| HOW MANY FILES? 4ENTER |
puis BASIC met de côté quatre tampons, numérotés 1, 2, 3 et 4.
Vous pouvez considérer un tampon comme une zone d'attente que les données doivent traverser pour aller et revenir du fichier disque. Lorsque vous souhaitez accéder à un fichier particulier, vous devez indiquer à BASIC quel tampon utiliser pour accéder à ce fichier. Vous devez également indiquer à BASIC le type d'accès que vous souhaitez - sortie séquentielle, entrée séquentielle ou entrée/sortie aléatoire.
Tout cela est fait avec l'instruction OPEN et "défait" avec l'instruction CLOSE.
OPEN |
Affecter un tampon à un fichier et définir le mode |
|---|---|
| DISK BASIC | |
Syntaxe
| OPEN exp1$,nmexp,exp2$ |
Paramètres
| Nom | Description | |
|---|---|---|
| exp1$ | Ce paramètre permet d'indiquer une expression de chaîne de caractères ou une constante dont seul le premier caractère est significatif ; ce caractère spécifie le mode dans lequel le fichier doit être ouvert : | |
| Valeur | Description | |
| I | Entrée séquentielle | |
| O | Sortie séquentielle | |
| R | Entrée/sortie aléatoire | |
| nmexp | Ce paramètre permet d'indiquer une valeur de 1 à 15, et indique à BASIC quel tampon attribuer au fichier spécifié par exp2$. | |
| exp2$ | Ce paramètre permet de définir une spécification de fichier TRSDOS. | |
Description
Cette instruction permet d'accéder à un fichier. exp1$ détermine le type d'accès que vous aurez via le tampon spécifié ; nmexp détermine quel tampon sera affecté au fichier ; et exp2$ nomme le fichier auquel accéder. Si exp2$ n'existe pas, alors TRSDOS peut le créer ou non, selon le mode d'accès.
Remarque
- nmexp (numéro de tampon) ne peut pas dépasser le nombre que vous avez entré pour les questions «FILES?» lors de l'initialisation. Si vous avez entré :
| HOW MANY FILES? 2ENTER |
alors nmexp peut avoir la valeur 1 ou 2.
Exemples d'instructions OPEN :
100 OPEN "O",1,"CLIENTLS/TXT"
Ouvre le fichier "CLIENTLS/TXT" pour une sortie séquentielle. Le tampon 1 sera utilisé. Si le fichier n'existe pas, il sera créé. S'il existe déjà, son contenu précédent est perdu.
100 OPEN "I",1,"PROG1/TXT:1"
Ouvre le fichier "PROG1/TXT" sur l'unité de disque 1 pour une entrée séquentielle. Le tampon 1 est affecté au fichier. Si PROG1/TXT n'existe pas sur l'unité de disque 1, un message d'erreur est renvoyé - puisque vous ne pouvez pas entrer à partir d'un fichier inexistant !
100 INPUT"MODE (I,O,R)";MODE$
110 INPUT"NOMBRE DE TAMPON";BUFFER%
120 INPUT"SPECIFICATION DE FICHIER";FILESPEC$
130 OPEN MODE$,BUFFER%,FILESPEC$
Cette séquence d'instructions vous permet de fournir les paramètres de l'instruction OPEN pendant l'exécution du programme. Le premier caractère de MODE$ définit le mode d'accès, BUFFER% détermine quel tampon sera utilisé et FILESPEC$ donne la spécification du fichier.
OPEN"R",2,"DATA/BAS.SPECIAL"
Ouvre le fichier DATA/BAS avec le mot de passe SPECIAL, en mode d'entrée/sortie aléatoire, en utilisant le tampon numéro 2. Si DATA/BAS n'existe pas, il sera créé sur le premier unité de disque non protégé en écriture.
Lorsqu'un fichier est ouvert, il est référencé par le numéro de tampon lui ayant été attribué. Exemples :
|
GET buffer-number PUT buffer-number PRINT#buffer-number INPUT#buffer-number |
Toutes ces instructions feront référence au fichier ayant été OPEN via le numéro de tampon. Le mode doit être correct.
Une fois qu'un tampon a été affecté à un fichier avec l'instruction OPEN, ce tampon ne peut pas être utilisé dans une autre instruction OPEN. Vous devez d'abord le CLOSE.
En savoir plus sur les affectations de tampon
Deux tampons ou plus peuvent être affectés au même fichier pour une entrée séquentielle (mode I). Cependant, un seul tampon à la fois peut être affecté à un fichier pour une sortie séquentielle (mode O) ou un accès aléatoire en mode R.
Par exemple :
10 OPEN"I",1,"TEST/TXT:1"
20 OPEN"I",2,"TEST/TXT:1"
Maintenant, TEST/TXT est accessible via les tampons 1 et 2 pour une entrée séquentielle.
CLOSE |
Ferme l'accès vers le fichier |
|---|---|
| DISK BASIC | |
Syntaxe
| CLOSE [nmexp[,nmexp...]] |
Paramètres
| Nom | Description | |
|---|---|---|
| nmexp | Ce paramètre permet d'indiquer une valeur comprise entre 1 et 15, et fait référence au numéro de tampon du fichier (attribué lors de l'ouverture du fichier). Si nmexp est omis, tous les fichiers ouverts seront fermés. | |
Description
Cette commande met fin à l'accès à un fichier via le(s) tampon(s) spécifié(s). Si nmexp n'a pas été affecté dans une instruction OPEN précédente, alors :
| CLOSE nmexp |
n'a aucun effet.
Exemple d'énoncés de CLOSE :
CLOSE 1, 2, 8
Termine les affectations de fichiers aux tampons 1, 2 et 8. Ces tampons peuvent maintenant être affectés à d'autres fichiers avec des instructions OPEN.
CLOSE FIRST%+COUNT%
Termine l'affectation du fichier au tampon spécifié par la somme (FIRST% + COUNT%).
Ne retirez pas une disquette contenant un fichier ouvert - fermez d'abord le fichier. En effet, les 256 derniers octets de données n'ont peut-être pas encore été écrits sur le disque. La fermeture du fichier écrira les données, si elles n'ont pas déjà été écrites.
Les actions et conditions suivantes entraînent la fermeture automatique de tous les fichiers :
|
NEWENTER RUNENTER MERGE filespecENTER |
Soit l'édition d'un fichier, l'ajout ou suppression de lignes de programme, l'exécution de l'instruction CLEAR n et les erreurs disque.
INPUT# |
Lecture séquentielle à partir du disque |
|---|---|
| DISK BASIC | |
Syntaxe
| INPUT #nmexp, var[,var...] |
Paramètres
| Nom | Description |
|---|---|
| nmexp | Ce paramètre permet d'indiquer un tampon de fichier d'entrée séquentiel, nmexp=1, 2,..., 15. |
| var | Ce paramètre permet d'indiquer le nom de la variable devant contenir les données du fichier. |
Cette instruction entre les données d'un fichier disque. Les données sont saisies séquentiellement. Autrement dit, lorsque le fichier est ouvert pour la première fois, un pointeur est défini sur le début du fichier. Chaque fois que des données sont saisies, le pointeur avance. Pour recommencer la lecture depuis le début du fichier, vous devez fermer le file-buffer et le rouvrir.
INPUT# ne se soucie pas de la manière dont les données ont été placées sur le disque - qu'une seule instruction PRINT# les y ait placées ou qu'elles aient nécessité 10 instructions PRINT# différentes. Ce qui compte pour INPUT#, ce sont les positions des caractères de fin et le marqueur EOF.
Pour INPUT# les données avec succès à partir du disque, vous devez savoir à l'avance quel est le format des données. Voici une description de la façon dont INPUT# interprète les différents caractères qu'il rencontre lors de la lecture des données.
Lors de la saisie de données dans une variable, le BASIC ignore les blancs de tête ; lorsque le premier caractère non blanc est rencontré, BASIC suppose qu'il a rencontré le début de l'élément de données.
L'élément de données se termine lorsqu'un caractère de fin est rencontré ou lorsqu'une condition de fin se produit. Les caractères de fin particuliers varient selon que BASIC entre dans une variable numérique ou de chaîne de caractères.
Lorsque EN (un retour chariot) est précédé de LF (un saut de ligne), EN n'est pas considéré comme un terminateur. Au lieu de cela, il devient une partie de l'élément de données (variable de chaîne de caractères) ou est simplement ignoré (variable numérique). (Pour saisir le caractère LF à partir du clavier, appuyez sur la flèche vers le bas (↓). Pour saisir le caractère EN, appuyez sur ENTER.) L'exception s'applique à tous les cas notés ci-dessous où EN est considéré comme un terminateur.
Entrée numérique
Supposons que l'image de données sur le disque est :
| 1.234 -33 27 EN |
EN désigne un caractère de retour chariot (code ASCII décimal 13).
Puis l'instruction suivante :
INPUT #1,A,B,C
ou la séquence d'instructions suivantes :
INPUT #1,A:INPUT #1,B:INPUT #1,C
attribuera les valeurs comme suit :
A=1.2345B=-33
C=27
Cela fonctionne car les blancs et EN servent de terminateurs pour l'entrée des variables numériques. Le blanc avant 1,2345 est un «blanc de début», il est donc ignoré. Le blanc après 1,2345 est un terminateur ; par conséquent, BASIC commence à entrer la deuxième variable au caractère «-», entre le nombre -33 et prend les deux blancs suivants comme terminateurs. La troisième entrée commence au 2 et se termine au 7.
Entrée de chaîne de caractères
Lors de la lecture de données dans une variable de chaîne de caractères, INPUT ignore tous les blancs de début ; le premier caractère non blanc est considéré comme le début de l'élément de données.
Si le premier caractère est un guillemet double ("), alors INPUT évaluera les données comme une chaîne entre guillemets : il lira tous les caractères suivants jusqu'au prochain guillemet double. Les virgules, les espaces et les caractères EN - seront être inclus dans la chaîne de caractères. Les guillemets eux-mêmes ne font pas partie de la chaîne de caractères.
Par exemple, si les données sur disque sont :
| PECOS, TEXAS"BON MELONS" |
Alors l'instruction suivante :
INPUT #1,A$,B$,C$
attribuerait des valeurs comme suit :
|
A$=PECOS B$= TEXAS"BON MELONS" C$=Chaîne de caractères nulle |
Si une virgule est insérée dans l'image de données avant le premier guillemet double, C$ obtiendra la valeur, BON MELONS.
Ce sont des exemples très simples juste pour vous donner une idée de la façon dont INPUT fonctionne. Cependant, il existe de nombreuses autres façons d'entrer des données - différents terminateurs, différents types de variables cibles,...
Plutôt que d'adopter une approche de fusil de chasse et d'essayer de tous les couvrir, nous donnerons une description générale du fonctionnement de l'entrée et des caractères et conditions de terminaison, puis fournirons plusieurs exemples.
Lorsque BASIC rencontre un caractère de terminaison, il analyse en avant pour voir combien de caractères de terminaison supplémentaires il peut inclure avec le premier caractère de terminaison. Cela garantit que BASIC commencera à rechercher l'élément de données suivant au bon endroit.
La liste ci-dessous définit les différents ensembles de terminaison que INPUT# recherchera. Il essaiera toujours de prendre le plus grand ensemble possible.
Ensembles de terminaisons d'entrée numérique :
- Fin de fichier rencontrée
- 255e caractère de données rencontré
- , (virgule)
- EN
- EN LF
- [ ...] [ EN]
- [ ...] [ EN LF]
Ensembles de terminateurs de chaîne de caractères entre guillemets :
- Fin de fichier rencontrée
- 255e caractère de données rencontré
- " (double citation)
- " [ ...][,]
- " [ ...][ EN]
- " [ ...][ EN LF]
Ensembles de terminaisons de chaîne de caractères sans guillemets :
- Fin de fichier rencontrée
- 255e caractère de données rencontré
- ,
- EN [LF]
Voici un organigramme décrivant comment INPUT# affecte des données à une variable :
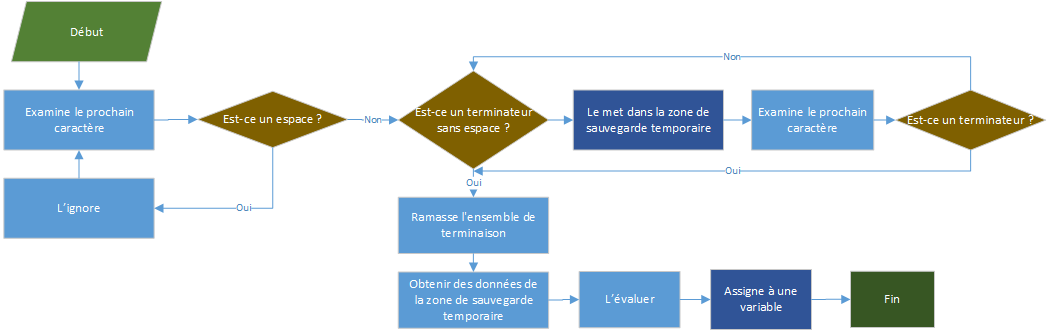
Le tableau suivant montre comment différentes images de données seront lues par l'instruction :
INPUT#1,A,B,C
Voici quelques exemples de résultats :
| Numéro d'exemple | Image sur le disque | Valeur assigné |
|---|---|---|
| 1 | 123.45 EN LF 8.2E4 7000 EN | A=123.45 B=82000 C=7000 |
| 2 | 3 LF EN 4 EN 5 EN A12 EOF | A=34 B=5 C=0 |
| 3 | 1,,2,3,4 EN | A=1 B=0 C=2 |
| 4 | 1,3,fin du fichier | A=1 B=2 C=0 erreur de fin de fichier |
Dans l'exemple 2 ci-dessus, pourquoi la variable C prend-elle la valeur 0 ? Lorsque l'entrée atteint la fin du fichier, elle termine la dernière donnée, contenant alors "A12". Ceci est évalué par une routine similaire à la fonction VAL du BASIC - renvoyant un zéro car le premier caractère de "A12" n'est pas numérique.
Dans l'exemple 3, lorsque INPUT# cherche le deuxième élément de données, il rencontre immédiatement un terminateur (la virgule) ; donc la variable B prend la valeur zéro.
Le tableau suivant montre comment diverses images de données sur disque seront lues par l'instruction :
INPUT#1,A$,B$
| Numéro d'exemple | Image sur le disque | Valeur assigné |
|---|---|---|
| 1 | "TREMBLAY,J."TREMBLAY,M.N. eof | A$=TREMBLAY,J. B$=TREMBLAY,M.N. |
| 2 | TREMBLAY,J. TREMBLAY,M.N. EN | A$=TREMBLAY,J. B$=J |
| 3 | LE MOT "QUI",12345.789 EN | A$=LE MOT "QUI" B$=12345.789 |
| 4 | OCTET LF UNITE DE MEMOIRE eof | A$=OCTET LF EN UNITE DE MEMOIRE B$=nulle (erreur eof) |
Dans l'exemple 3, le premier élément de données est une chaîne de caractères sans guillemets, donc les guillemets doubles ne sont pas des terminateurs et font partie de A$.
Dans l'exemple 4, le EN est précédé d'un LF, il ne termine donc pas la première chaîne de caractères ; LF et EN sont tous deux inclus dans A$.
Note technique : La discussion ci-dessus ignore le rôle du tampon d'entrée dans le processus d'entrée séquentielle. En fait, DISK BASIC lit toujours des enregistrements de données de 256 octets dans le tampon, puis trie ce qui se trouve dans le tampon pour "satisfaire" la liste de variables INPUT #. C'est pourquoi :
100 INPUT#1,A%
200 INPUT#1,B%
ne nécessitent pas nécessairement deux accès disque. L'enregistrement de 256 octets dans la mémoire tampon peut contenir suffisamment de données pour A%, B% et plus.
LINE INPUT# |
Lire une ligne de texte à partir du disque |
|---|---|
| DISK BASIC | |
Syntaxe
| LINE INPUT#nmexp,var$ |
Paramètres
| Nom | Description |
|---|---|
| nmexp | Ce paramètre permet d'indiquer un tampon de fichier de sortie séquentiel, nmexp=1,2,...,15. |
| var$ | Ce paramètre permet d'indiquer le nom de la variable devant contenir les données de la chaîne de caractères. |
Description
Semblable à LINE INPUT à partir du clavier, cette instruction lit une "ligne" de données de chaîne de caractères dans var$. Ceci est utile lorsque vous souhaitez lire un fichier de programme BASIC au format ASCII en tant que données, ou lorsque vous souhaitez lire des données sans suivre les restrictions habituelles concernant les caractères de début et les terminateurs.
LINE INPUT (ou LINEINPUT - l'espace est facultatif) lit tout depuis le premier caractère jusqu'à :
- un caractère EN non précédé de LF
- la fin de fichier
- le 255e caractère de données (ce 255 caractère est inclus dans la chaîne de caractères)
Les autres caractères rencontrés - guillemets, virgules, espaces de début, paires LF EN - sont inclus dans la chaîne de caractères.
Par exemple, si les données ressemblent à :
10 CLEAR 500 EN
20 OPEN"I",1,"PROG" EN
:
:
puis l'instruction :
LINEINPUT#1,A$
pourrait être utilisé de manière répétitive pour lire chaque ligne de programme, une ligne à la fois.
PRINT# |
Écriture séquentielle sur fichier disque |
|---|---|
| DISK BASIC | |
Syntaxe
| PRINT#nmexp,[USING format$;] exp[p exp...] |
Paramètres
| Nom | Description |
|---|---|
| nmexp | Ce paramètre permet d'indiquer un tampon de fichier de sortie séquentiel, nmexp=1,2,...,15 |
| format$ | Ce paramètre permet d'indiquer une séquence de spécificateurs de champs utilisés avec l'option USING. |
| p | Ce paramètre permet d'indiquer un délimiteur placé entre toutes les deux expressions à afficher sur le disque ; un point-virgule ou une virgule peut être utilisé (le point-virgule est préférable). |
| exp | Ce paramètre permet d'indiquer l'expression à évaluer et à écrire sur le disque. |
Description
L'instruction écrit les données séquentiellement dans le fichier spécifié. Lorsque vous ouvrez un fichier pour la première fois pour une sortie séquentielle, un pointeur est placé au début du fichier, donc votre premier PRINT# place les données au début du fichier. A la fin de chaque opération PRINT#, le pointeur avance, de sorte que les valeurs sont écrites en séquence.
Une instruction PRINT# crée une image disque similaire à ce qu'un PRINT pour afficher crée à l'écran. Souvenez-vous de cela et vous pourrez configurer correctement votre liste PRINT# pour un accès par une ou plusieurs instructions INPUT.
PRINT# ne compresse pas les données avant de les écrire sur le disque ; il écrit une image codée en ASCII des données.
Exemples
Par exemple, si A=123,45 :
PRINT#1,A
écrira une séquence de caractères de neuf octets sur le disque :
123.45 ENLa ponctuation dans la liste PRINT est très importante. Les virgules et les points-virgules sans guillemets ont le même effet que dans PRINT normal pour afficher les instructions.
Par exemple, si A=2300 et B=1,303, alors :
PRINT#1,A,B
place les données sur le disque comme :
2300 1.303 ENLa virgule entre A et B dans la liste PRINT# provoque 10 espaces supplémentaires dans le fichier disque. En règle générale, vous ne voudriez pas utiliser l'espace disque de cette façon, vous devez donc utiliser des points-virgules au lieu de virgules.
PRINT#1,A;B
écrivez les données comme suit :
| 2300 1.303 EN |
PRINT# avec des données numériques est assez simple - n'oubliez pas de séparer les éléments par des points-virgules.
PRINT# avec des données de chaîne de caractères nécessite plus de soin, principalement parce que vous devez insérer des délimiteurs pour que les données puissent être lues correctement. En particulier, vous devez séparer les éléments de chaîne de caractères avec des délimiteurs explicites si vous souhaitez les INPUT# en tant que chaînes de caractères distinctes.
Par exemple, supposons :
A$="JEAN TREMBLAY" et B$="100-01-001"Alors :
PRINT#1, A$;B$
produirait cette image sur le disque :
| JEAN TREMBLAY100-01-001 EN |
ne pouvant pas être INPUT dans deux variables.
L'instruction suivante :
PRINT#1,A$;",";B$
produirait :
| JEAN TREMBLAY,100-01-001 EN |
pouvant être INPUT# en deux variables.
Cette méthode est adéquate si les données de chaîne ne contiennent pas de délimiteurs - virgules ou EN - caractères. Mais si les données contiennent des délimiteurs ou des espaces de début que vous ne voulez pas ignorer, vous devez fournir des guillemets explicites à écrire avec les données. Par exemple, supposons A$="TREMBLAY, JEAN P." B$="100-01-001".
Si vous utilisez :
PRINT#1,A$;",";B$
produirait :
| TREMBLAY, JEAN P.,100-01-001 EN |
Lorsque vous essayez de saisir ceci avec une déclaration telle que :
INPUT#2,A$,B$
A$ obtiendra la valeur "TREMBLAY", et B$ obtiendra "JEAN P." - à cause de la virgule après TREMBLAY dans l'image disque.
Pour écrire ces données afin qu'elles puissent être saisies correctement, vous devez utiliser la fonction CHR$ pour insérer des guillemets doubles explicites dans l'image disque. Étant donné que 34 est le code ASCII décimal pour les guillemets doubles, utilisez CHR$ comme suit :
PRINT#1,CHR$(34);A$;CHR$(34);B$
cela produit l'image disque :
| "TREMBLAY, JEAN P.,"100-01-001 EN |
pouvant être lu avec un simple :
INPUT#2,A$,B$
Remarque : Vous pouvez également utiliser la fonction CHR$ pour insérer d'autres délimiteurs et codes de contrôle dans le fichier, par exemple :
| Caractère | Description |
|---|---|
| CHR$(10) | LF (Saut de ligne) |
| CHR$(13) | Retour de chariot (caractère EN) |
| CHR$(11) ou CHR$(12) | Haut de page de l'imprimante ligne |
Option USING
Cette option facilite l'écriture de fichiers dans un format soigneusement contrôlé. Vous pouvez créer un fichier de rapport de cette manière, pouvant alors être LIST ou PRINT (commandes TRSDOS).
Ou vous pouvez utiliser cette option pour contrôler le nombre de caractères d'une valeur étant écrits sur le disque.
Par exemple, supposons :
A$="LUDWIG"
B$="VAN"
C$="BEETHOVEN"
Puis l'instruction suivante :
PRINT#1,USING"!. !.% %";A$;B$;C$
écrirait les données sous forme de surnom :
| L.V.BEET EN |
(dans ce cas, nous ne voulions pas ajouter de délimiteurs explicites.)
Note technique : La discussion ci-dessus ignore le rôle du tampon de sortie dans le processus d'écriture séquentielle. En fait, les données sont d'abord placées dans la mémoire tampon, puis, au fur et à mesure que les enregistrements de 256 octets sont remplis, les données sont écrites sur le fichier disque. C'est pourquoi il n'y a pas toujours d'accès disque lors de l'exécution de chaque instruction PRINT#.
Instructions d'accès aléatoire
FIELD |
Organiser un fichier tampon aléatoire en champs |
|---|---|
| DISK BASIC | |
Syntaxe
| FIELD nmexp,nmexp1 AS var1$ [,nmexp2 AS var2$...] |
Paramètres
| Nom | Description |
|---|---|
| nmexp | Ce paramètre permet d'indiquer un tampon de fichier à accès aléatoire, nmexp=1, 2,...,15. |
| nmexp1 | Ce paramètre permet d'indiquer la longueur du premier champ. |
| var1$ | Ce paramètre permet de définir un nom de variable pour le premier champ. |
| nmexp2 | Ce paramètre permet d'indiquer la longueur du deuxième champ. |
| var2$ | Ce paramètre permet de définir un nom de variable pour le deuxième champ les paires nmexp AS var$ suivantes définissent d'autres champs dans le tampon. |
Avant d'appliquer FIELD sur un tampon, vous devez utiliser une instruction OPEN pour affecter ce tampon à un fichier disque particulier (vous devez utiliser le mode d'accès aléatoire). Utilisez ensuite l'instruction FIELD pour organiser un tampon de fichiers aléatoire afin de pouvoir transmettre des données de BASIC à l'entreposage sur disque et vice-versa.
Chaque tampon de fichier aléatoire a 255 octets pouvant entreposer des données pour le transfert de l'entreposage sur disque vers le BASIC ou du BASIC vers le disque. Cependant, vous avez besoin d'un moyen d'accéder à ce tampon à partir de BASIC afin de pouvoir soit lire les données qu'il contient, soit y placer de nouvelles données. L'instruction FIELD fournit les moyens d'accès.
Vous pouvez utiliser l'instruction FIELD un certain nombre de fois pour "réorganiser" un tampon de fichier. Le FIELD sur un tampon n'efface pas le contenu du tampon ; seuls les moyens d'accès au tampon (les noms des champs) sont modifiés. De plus, deux ou plusieurs noms de champ peuvent faire référence à la même zone du tampon.
Exemples
FIELD 1, 255 AS A$
Cette instruction indique à BASIC d'affecter la totalité du tampon de 255 octets à la variable de chaîne de caractères A$. Si vous affichez maintenant A$, vous verrez le contenu du tampon. Bien sûr, cette valeur n'aurait aucun sens à moins que vous n'ayez utilisé GET pour lire un enregistrement de 255 octets à partir du disque.
Remarque : Toutes les données - à la fois les chaînes de caractères et les nombres - doivent être placées dans le tampon sous forme de chaîne de caractères. Il existe trois paires de fonctions (MKI$/CVI,MKS$/CVS,MKD$/CVD) pour convertir des nombres en chaînes de caractères et vice-versa.
FIELD 3, 16 AS NM$,25 AS AD$,10 AS CY$,2 AS ST$,7 AS ZP$
Les 16 premiers octets du tampon 3 reçoivent le nom de tampon NM$ ; les 25 suivants, AD$ ; les 10 suivants, CY$ ; les 2 suivants, ST$ ; et les 7 suivants, ZP$. Les 195 octets restants du tampon ne sont pas du tout mis en champ.
En savoir plus sur les noms de champs
Les noms de champ, comme NM$, AD$, CY$, ST$ et ZP$, ne sont pas des variables de chaîne de caractères au sens ordinaire. Ils ne consomment pas l'espace de chaîne de caractères disponible pour BASIC.
Au lieu de cela, ils pointent vers le champ tampon que vous avez affecté avec l'instruction FIELD. C'est pourquoi vous pouvez utiliser :
100 FIELD 1,255 AS A$
sans se soucier de savoir si 255 octets d'espace de chaîne de caractères sont disponibles pour A$.
Si vous utilisez un nom de champ tampon sur le côté gauche d'une instruction d'affectation ordinaire, ce nom ne pointera plus vers le champ tampon ; par conséquent, vous ne pourrez pas accéder à ce champ en utilisant le nom de champ précédent.
Par exemple :
A$=B$
annule l'effet de l'instruction FIELD ci-dessus (ligne 100).
Lors d'une entrée aléatoire, l'instruction GET place les données dans le tampon de 255 octets, où elles sont accessibles à l'aide des noms de champ attribués à ce tampon. Pendant la sortie aléatoire, LSET et RSET placent les données dans le tampon, vous pouvez donc mettre (PUT) le contenu du tampon dans un fichier disque.
Souvent, vous ne voudrez pas utiliser une variable factice dans une instruction FIELD pour "passer" une partie du tampon et commencer à la remplir quelque part au milieu. Par exemple :
FIELD 1,15 AS CLIENT$(1),112 AS HIST$(1)
FIELD 1,128 AS DUMMY$,15 AS CLIENT$(2),112 AS HIST$(2)
Dans la deuxième instruction FIELD, DUMMY$ sert à déplacer la position de départ de CLIENT$(2) vers la position 129. De cette manière, deux "sous-enregistrements" identiques sont définis sur le tampon numéro 1. Nous n'utiliserons pas réellement DUMMY$ pour placer données dans la mémoire tampon ou les récupérer à partir de la mémoire tampon.
Le tampon ressemble maintenant à ceci :
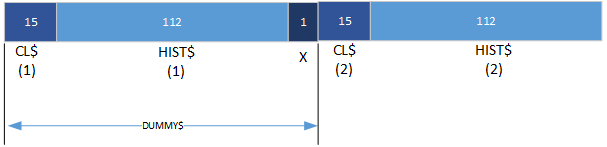
Notez qu'un seul octet (le 128e octet) reste inutilisé dans cette structure de champ.
GET |
Lire un enregistrement à partir du disque - accès aléatoire |
|---|---|
| DISK BASIC | |
Syntaxe
| GET nmexp1[,nmexp2] |
Paramètres
| Nom | Description |
|---|---|
| nmexp1 | Ce paramètre permet d'indiquer un tampon de fichier à accès aléatoire, nmexp1=1, 2,...,15 |
| nmexp2 | Ce paramètre permet d'indiquer quel enregistrement GET dans le fichier ; s'il est omis, l'enregistrement en cours sera lu. |
Cette instruction obtient un enregistrement de données à partir d'un fichier disque et le place dans le tampon spécifié. Avant d'obtenir des données GET à partir d'un fichier, vous devez ouvrir le fichier et lui attribuer un tampon. C'est-à-dire une déclaration du type :
| OPEN"R",nmexp1,filespec |
est requis avant l'instruction :
| GET nmexp1,nmexp5 |
Lorsque BASIC rencontre l'instruction GET, il examine le bloc de contrôle du tampon et obtient :
- les informations nécessaires pour accéder au dossier
- le mode dans lequel ce tampon a été configuré (doit être R)
- le numéro d'enregistrement en cours
- le numéro d'enregistrement EOF (fin de fichier), c'est-à-dire l'enregistrement ayant le numéro le plus élevé dans le fichier
- de nombreuses autres informations à usage interne
Le BASIC lit ensuite l'enregistrement nmexp2 du fichier et le place dans le tampon. Si vous omettez le numéro d'enregistrement, il lira l'enregistrement en cours.
L'enregistrement courant est l'enregistrement dont le numéro est supérieur d'une unité à celui du dernier enregistrement consulté. La première fois que vous accédez à un fichier via un tampon particulier, l'enregistrement courant est mis égal à 1.
Par exemple :
| Instruction de programme | Effet |
|---|---|
| 1000 OPEN"R",1,"NAME/BAS" | Ouvrir NAME/BAS pour un accès aléatoire en utilisant le tampon 1 |
| 1010 FIELD 1,... | Tampon de structure |
| 1020 GET 1 1025 REM ... TAMPON D'ACCES |
Obtenir l'enregistrement 1 dans le tampon 1 |
| 1030 GET 1,30 1035 REM ... TAMPON D'ACCES |
Obtenir l'enregistrement 30 dans le tampon 1 |
| 1040 GET 1,25 1046 REM ... TAMPON D'ACCES |
Obtenir l'enregistrement 25 dans le tampon 1 |
| 1050 GET 1 | Obtenir l'enregistrement 26 dans le tampon 1 |
Si vous tentez d'obtenir un enregistrement dont le numéro est supérieur à celui de l'enregistrement de fin de fichier, BASIC remplira le tampon avec des zéros hexadécimaux et aucune erreur ne se produira.
Pour éviter cela, vous pouvez utiliser la fonction LOF pour déterminer le numéro de l'enregistrement au numéro le plus élevé.
PUT |
Écrire un enregistrement sur le disque - accès aléatoire |
|---|---|
| DISK BASIC | |
Syntaxe
| PUT nmexp1[,nmexp2] |
Paramètres
| Nom | Description |
|---|---|
| nmexp1 | Ce paramètre permet d'indiquer un tampon de fichier à accès aléatoire, nmexp=1, 2,..., 15 |
| nmexp2 | Ce paramètre permet d'indiquer le numéro d'enregistrement dans le fichier, nmexp2=1, 2,..., jusqu'à 335, selon l'espace disponible sur le disque ; si nmexp2 est omis, le numéro d'enregistrement actuel est utilisé. |
Cette instruction déplace les données du tampon d'un fichier vers un emplacement spécifié dans le fichier. Avant de mettre des données dans un fichier, vous devez :
- Ouvrir le fichier (OPEN), affectant ainsi un tampon et définissant le mode d'accès (doit être R);
- Appliquer FIELD sur le tampon
- Placer les données dans la mémoire tampon avec les instructions LSET et RSET.
Lorsque BASIC rencontre l'instruction :
| PUT nmexp,nmexp2 |
il fait ce qui suit :
- Obtenez les informations nécessaires pour accéder au fichier disque
- Vérifie le mode d'accès pour ce tampon (doit par R)
- Acquiert plus d'espace disque pour le fichier est nécessaire pour accueillir l'enregistrement indiqué par nmexp2
- Copie le contenu du tampon dans l'enregistrement spécifié du fichier disque
- Mettre à jour le numéro d'enregistrement actuel pour qu'il soit égal à nmexp2 + 1
L'enregistrement courant est l'enregistrement dont le numéro est supérieur d'une unité au dernier enregistrement consulté. La première fois que vous accédez à un fichier via un tampon particulier, l'enregistrement courant est mis égal à 1.
Si le numéro d'enregistrement que vous mettez (PUT) est supérieur au numéro d'enregistrement de fin de fichier, alors nmexp2 devient le nouveau numéro d'enregistrement de fin de fichier.
Cela a une implication importante. Lorsque vous mettez un enregistrement dont le nombre dépasse le numéro d'enregistrement EOF, de l'espace est alloué sur le disque pour accueillir le nouveau numéro d'enregistrement le plus élevé plus tous les enregistrements de numéro inférieur. Par exemple :
PUT nmexp,336
produira toujours un message DISK FULL (disque plein), puisque TRSDOS essaie de trouver de l'espace pour tous les enregistrements de 1 à 336 - et 335 est le nombre maximum d'enregistrements disponibles sur une disquette.
Exemples (supposons qu'un fichier nommé SAMPLE/BAS existe et que vous y ayez précédemment écrit 10 enregistrements, de sorte que LOF=10) :
| Instruction de programme | Effet |
|---|---|
| 1000 OPEN"R",1,"SAMPLE/BAS" | Ouvrir SAMPLE/BAS pour une adresse aléatoire sous le tampon 1 |
| 1010 FIELD 1,... | Prépare le tampon |
| 1020 LSET... | Place les données dans le tampon |
| 1030 PUT 1 | Copie le contenu du tampon dans l'enregistrement courant (=#1) |
| 1035 LSET ... | Place les données dans le tampon |
| 1040 PUT 1,30 | Acquérir de l'espace disque pour les enregistrements 2 à 30 et copier le contenu du tampon dans l'enregistrement 30 ; régler LOF=30 |
| 1045 LSET ... | Place les données dans le tampon |
| 1050 PUT 1,25 | Copier le contenu du tampon dans l'enregistrement 25 |
| 1055 LSET... | Place les données dans le tampon |
| 1060 PUT 1 | Copier le contenu du tampon dans l'enregistrement en cours (=#26) |
LSET et RSET |
Placer les données dans un champ tampon aléatoire |
|---|---|
| DISK BASIC | |
Syntaxe
| LSET var$=exp$ |
| RSET var$=exp$ |
Paramètres
| Nom | Description |
|---|---|
| var$ | Ce paramètre permet d'indiquer un nom de champ. |
| exp$ | Ce paramètre contient les données à placer dans le champ de tampon nommé par var$ |
Ces deux instructions vous permettent de placer des données de chaîne de caractères dans des champs préalablement définis par une instruction FIELD.
Par exemple, supposons que NM$ et AD$ aient été définis comme noms de champ pour un tampon de fichier aléatoire. NM$ a une longueur de 18 caractères et AD$ a une longueur de 25 caractères.
Maintenant, nous voulons placer les informations suivantes dans le champ de tampon afin qu'elles puissent être écrites sur le disque :
| Champ | Valeur |
|---|---|
| Nom : | JEAN GAGNON, JR. |
| Adresse : | 2000 RUE DES FLEURS |
Ceci est accompli avec les deux instructions :
LSET NM$="JEAN GAGNON, JR."
LSET AD$="2000 RUE DES FLEURS"
Cela place les données dans le tampon comme suit :
| NM$ | AD$ |
|---|---|
| «JEAN GAGNON, JR. » | «2000 RUE DES FLEURS » |
Notez que les espaces de remplissage ont été placés à droite des chaînes de données dans les deux cas. Si nous avions utilisé RSET au lieu des instructions LSET, les espaces de remplissage auraient été placés à gauche. C'est la seule différence entre LSET et RSET.
Par exemple :
RSET NM$="JEAN GAGNON, JR."
RSET AD$="2000 RUE DES FLEURS"
place les données dans le champ comme suit :
| NM$ | AD$ |
|---|---|
| « JEAN GAGNON, JR.» | « 2000 RUE DES FLEURS» |
Si un élément de chaîne est trop grand pour tenir dans le champ tampon spécifié, il est toujours tronqué à droite. Autrement dit, les caractères supplémentaires à droite sont ignorés.
CVD, CVI et CVS |
Restaurer la chaîne de caractères sous forme numérique |
|---|---|
| DISK BASIC | |
Syntaxe
| CVD(exp$) |
Paramètres
| Nom | Description |
|---|---|
| exp$ | Ce paramètre permet de définir une chaîne de caractères de huit caractères ; exp$ est généralement le nom d'un champ tampon contenant une chaîne numérique. Si LEN(exp$)<8, une erreur ILLEGAL FUNCTION CALL se produit ; si LEN(exp$)>8, seuls les huit premiers caractères sont utilisés. |
Syntaxe
| CVI(exp$) |
Paramètres
| Nom | Description |
|---|---|
| exp$ | Ce paramètre permet de définir une chaîne de caractères de deux caractères ; exp$ est généralement le nom d'un champ tampon contenant une chaîne numérique. Si LEN(exp$)<2, une erreur ILLEGAL FUNCTION CALL se produit ; si LEN(exp$)>2, seuls les deux premiers caractères sont utilisés. |
Syntaxe
| CVS(exp$) |
Paramètres
| Nom | Description |
|---|---|
| exp$ | Ce paramètre permet de définir une chaîne de caractères de quatre caractères ; exp$ est généralement le nom d'un champ tampon contenant une chaîne de caractères numérique. Si LEN(exp$)<4, une erreur ILLEGAL FUNCTION CALL se produit ; si LEN(exp$)>4, seuls les quatre premiers caractères sont utilisés. |
Ces fonctions vous permettent de restaurer les données sous forme numérique après leur lecture à partir du disque. Généralement, les données ont été lues par une instruction GET et sont entreposées dans un tampon de fichier à accès aléatoire.
Les fonctions CVD, CVI, CVS sont respectivement les inverses de MKD$, MKI$ et MKS$.
Par exemple, supposons que le nom GROSSPAY$ fasse référence à un champ de huit octets dans un tampon de fichier à accès aléatoire et qu'après avoir obtenu un enregistrement, GROSSPAY$ contienne une représentation MKD$ du nombre 13123.38.
Puis l'instruction suivante :
PRINT CVD(GROSSPAY$)-TAXES
affiche le résultat de la différence, 13123.38-TAXES. Alors que l'instruction suivante :
PRINT GROSSPAY$-TAXES
produira une erreur TYPE MISMATCH, car les valeurs de chaîne de caractères ne peuvent pas être utilisées dans les expressions arithmétiques.
En utilisant le même exemple, l'instruction :
A#=CVD(GROSSPAY$)
attribue la valeur numérique 13123,38 à la variable double précision A#.
EOF |
Détecteur de fin de fichier |
|---|---|
| DISK BASIC | |
Syntaxe
| EOF(nmexp) |
Paramètres
| Nom | Description |
|---|---|
| nmexp | Ce paramètre permet d'indiquer un tampon de fichier, nmexp=1, 2,..., 15. |
Cette fonction vérifie si tous les caractères jusqu'au marqueur de fin de fichier ont été accédés, de sorte que vous pouvez éviter les erreurs INPUT PAST END lors de la saisie séquentielle.
En supposant que nmexp spécifie un fichier ouvert, alors EOF(nmexp) renvoie 0 (faux) lorsque l'enregistrement EOF n'a pas encore été lu, et -1 (vrai) lorsqu'il a été lu.
Exemples :
IF EOF(5)THEN PRINT"FIN DU FICHIER"FILENM$
IF EOF(NM%)THEN CLOSE NM%
La séquence de lignes suivante lit les données numériques de DATA/TXT dans le tableau A(). Lorsque le dernier caractère de données du fichier est lu, le test EOF de la ligne 30 "réussit", de sorte que le programme sort de la boucle d'accès au disque, empêchant une erreur INPUT PAST END de se produire. Notez également que la variable I contient le nombre d'éléments entrés dans le tableau A().
5 DIM A(100) 'EN SUPPOSANT QUE C'EST UNE VALEUR SURE
10 OPEN"I",1,"DATA/TXT"
20 I%=0
30 IF EOF(1)THEN 70
40 INPUT#1,A(I%)
50 I%=I%+1
60 GOTO 30
70 REM LE PROGRAMME CONTINUE ICI APRES L'ENTREE DU DISQUE
À la ligne 30, LOF(1) spécifie le numéro d'enregistrement le plus élevé auquel accéder.
Remarque : Si vous tentez d'obtenir des numéros d'enregistrement au-delà de l'enregistrement de fin de fichier, BASIC remplit simplement le tampon avec des zéros hexadécimaux et aucune erreur n'est générée.
Lorsque vous souhaitez ajouter à la fin d'un fichier, LOF vous indique par où commencer :
100 I%=LOF(1)+1 'ENREGISTREMENT EXISTANT LE PLUS ELEVE
110 PUT 1,I% 'AJOUTER LE PROCHAIN ENREGISTREMENT
MKD$, MKI$, MKS$ |
Conversion de données, numérique à chaîne de caractères |
|---|---|
| DISK BASIC | |
Syntaxe
| MKD$(nmexp) |
Paramètres
| Nom | Description |
|---|---|
| nmexp | Ce paramètre permet d'évaluer comme un nombre à double précision. |
Syntaxe
| MKI$(nmexp) |
Paramètres
| Nom | Description |
|---|---|
| nmexp | Ce paramètre permet d'évaluer comme un entier, -32768<=nmexp<32768 ; si nmexp dépasse cette intervalle, une erreur ILLEGAL FUNCTION CALL se produit ; tout composant fractionnaire dans nmexp est tronqué. |
Syntaxe
| MKS$(nmexp) |
Paramètres
| Nom | Description |
|---|---|
| nmexp | Ce paramètre permet d'évaluer comme un nombre de simple précision. |
Description
Ces fonctions changent un nombre en chaîne de caractères. En fait, les valeurs d'octet composant le nombre ne sont pas modifiées ; un seul octet, le spécificateur de type de données interne, est modifié, de sorte que les données numériques peuvent être placées dans une variable de chaîne de caractères.
C'est-à-dire :
- MKD$ renvoie une chaîne de caractères de huit octets
- MKI$ renvoie une chaîne de caractères de deux octets
- MKS$ renvoie une chaîne de caractères de quatre octets
Exemples
ASC(MKI$(I%)) ' EGALE LE LSB DE I%, EXEMPLE: (I% AND 255)
ASC(RIGHT$(MKI$(I),1)) '= LE MSB DE I%, EXEMPLE: INT(I%/256)
LSET AVG$=MKS$(0.123)
AVG$ fait généralement référence à un champ de tampon aléatoire de quatre octets. Maintenant, il contient une représentation du nombre simple précision 0,123.
LSET TALLY$=MKI$(I%)
Le nom des champs TALLY$ contiendrait désormais une représentation sur deux octets de l'entier I%.
A$=MKI$(8/I)
A$ devient une représentation sur deux octets de la partie entière de 8/I. Toute partie fractionnaire est ignorée. Notez que A$ dans ce cas est une variable de chaîne normale, pas un nom de champ tampon.
Supposons que BASEBALL/BAT (une extension de fichier non standard) a été ouvert pour un accès aléatoire à l'aide du tampon 2 et que le tampon a été FIELD comme suit :
| Champ | NM$ | YRS$ | AVG$ | HR$ | AB$ | ERNING$ |
|---|---|---|---|---|---|---|
| Longueur | 16 | 2 | 4 | 2 | 4 | 4 |
NM$ est destiné à contenir une chaîne de caractères ; AVG$, AB$ et ERNING$, valeurs converties en simple précision ; YR$ et HR$, entiers convertis.
Supposons que nous souhaitions écrire l'enregistrement de données suivant :
SLOW LEARNER a joue 38 ans; moyenne au baton à vie .123; coups de circuit en carrière, 11 ; aux batons, 32768 ; ..., gagnant -13,75.Ensuite, nous utiliserions les fonction de fabrication de chaîne de caractères comme suit :
1000 LSET NM$="SLOW LEARNER"
1010 LSET YRS$=MKI$(38)
1020 LSET AVG$=MKS$(.123)
1030 LSET HR$=MKI$(11)
1040 LSET AB$=MKS$(32768)
1050 LSET ERNING$=MKS$(-13.75)
Après cette séquence, vous pouvez écrire les informations de SLOW LEARNER sur le disque avec l'instruction PUT. Lorsque vous le relirez à partir du disque avec GET, vous devrez restaurer les données numériques de la chaîne de caractères à la forme numérique, en utilisant les fonctions CVI et CVS.
Techniques d'accès séquentiel
L'entrée/sortie séquentielle est le moyen le plus simple de stocker des données dans des fichiers disque et de les récupérer dans des variables BASIC.
Pour écrire sur le disque, vous ouvrez un fichier pour une sortie séquentielle, PRINT# les données et fermez le fichier. Pour relire les données, il vous suffit d'ouvrir le fichier pour un accès séquentiel et d'utiliser l'instruction INPUT# pour mettre les données directement dans les variables BASIC - dans le même ordre que les données ont été écrites sur le disque.
Sortie séquentielle - Un exemple
Supposons que nous souhaitions entreposer une table de constantes de conversion anglais-métrique :
| Unité anglaise | Équivalent métrique |
|---|---|
| 1 pouces | 2,54001 centimètres |
| 1 mille | 1,60935 kilomètres |
| 1 acre | 4046,86 mètre carré |
| 1 pouce cube | 0,01638716 litres |
| 1 gallon américain | 3,785 litres |
| 1 litre de liquide | 0,9463 litre |
| 1 lb (avoir) | 0,45359 kilogramme |
Nous décidons d'abord de ce que sera l'image de données. Disons que nous voulons qu'il ressemble à ceci :
| unité anglaise->unité métrique,facteur EN |
Par exemple, les données entreposées commenceraient :
| IN->CM, 2.54001 EN |
Le programme suivant créera un tel fichier de données.
Remarque : EN représente un retour de chariot, hexadécimal 0D.
10 OPEN"O",1,"METRIC/TXT"
20 FORI%=1 TO 7
30 READ UNIT$,FACTR
40 PRINT#1,UNIT$;",";FACTR
50 NEXT
60 CLOSE
70 DATA IN->CM,2.54001,MI->KM,1,60935,ACR->SQ. M,4046,86
80 DATA CU.IN->LTR,1.638716E-2,GAL->LTR,3.785
90 DATA LIQ QT->LTR,0.9463,LB->KG,0.45359
La ligne 10 crée un fichier disque nommé METRIC/TXT et affecte le tampon 1 pour la sortie séquentielle à ce fichier. L'extension /TXT est utilisée car la sortie séquentielle entrepose toujours les données sous forme de texte codé ASCII.
Remarque : Si METRIC/TXT existe déjà, la ligne 10 entraînera la perte de toutes ses données. Voici pourquoi : chaque fois qu'un fichier est ouvert pour une sortie séquentielle, le marqueur EOF est défini au début du fichier. En effet, TRSDOS "oublie" que quoi que ce soit ait jamais été écrit au-delà de ce point.
La ligne 40 affiche le contenu actuel de UNIT$ et FACTR dans le tampon du fichier. L'écriture sur le disque n'aura pas lieu tant que le tampon n'est pas rempli ou que vous ne fermez pas le fichier, selon la première éventualité. Étant donné que les éléments de chaîne ne contiennent pas de délimiteurs, il n'est pas nécessaire d'imprimer des guillemets explicites autour d'eux. La virgule explicite suffit.
La ligne 60 ferme le fichier. Le marqueur EOF pointe vers la fin du dernier élément de données, c'est-à-dire 0,45359, de sorte que plus tard, lors de la saisie, DISK BASIC saura quand il aura lu toutes les données.
Entrée séquentielle - un exemple
Le programme suivant lit les données de METRIC/TXT dans deux tableaux "parallèles", puis vous demande d'entrer un problème de conversion.
5 CLEAR 500
10 DIM UNITS$(9),FACTR(9) 'PERMET JUSQU'A 10 PAIRES DE DONNEES
20 OPEN"I",1,"METRIC/TXT
25 I%=0
30 IF EOF(1)THEN 70
40 INPUT#1,UNIT$(I%),FACTR(I%)
50 I%=I%+1
60 GOTO 30
70 REM ... LES FACTEURS DE CONVERSION ONT ÉTÉ LUS DANS
100 CLS: PRINT TAB(5)"*** CONVERSIONS ANGLAIS VERS MÉTRIQUE ****"
110 FOR ITEM%=0TOI%-1
120 PRINT USING"(## ) % %";ITEM%,UNIT$(ITEM%)
130 NEXT
140 PRINT@704,"QUELLE CONVERSION ";
150 INPUT CHOICE%
155 PRINT@768,"ENTRER LA QUANTITE EN ANGLAIS";
160 INPUT V
170 PRINT"L'EQUIVALENT METRIQUE EST"V*FACTR(CHOICE%)
180 INPUT"APPUYEZ SUR ENTREE POUR CONTINUER";X
190 PRINT@704,CHR$(31); 'EFFACE LA FIN DU CADRE
200 GOTO 140
La ligne 20 ouvre le fichier pour une entrée séquentielle. Le pointeur de lecture est automatiquement placé au début du fichier.
La ligne 30 vérifie que l'enregistrement de fin de fichier n'a pas été lu. Si c'est le cas, le contrôle passe de la boucle d'entrée du disque à la partie du programme utilisant les données nouvellement acquises.
La ligne 40 lit une valeur dans le tableau d'agitation UNIT$() et un nombre dans le tableau simple précision FACTR(). Notez que cette liste INPUT est parallèle à la liste PRINT# ayant créé le fichier de données. Ce parallélisme n'est cependant pas obligatoire. Nous aurions tout aussi bien pu utiliser :
40 INPUT#1,UNIT$(I%):INPUT#1,FACTR(I%)
Comment mettre à jour le fichier
Supposons que vous vouliez ajouter plus d'entrées dans le fichier de conversion Anglais-Métrique. Vous ne pouvez pas simplement rouvrir le fichier pour une sortie séquentielle et PRINT# les données supplémentaires - cela placerait immédiatement le marqueur de fin de fichier au début du fichier, détruisant ainsi le contenu précédent du fichier. Faites ceci à la place :
- Ouvrir le fichier pour une saisie séquentielle
- Entrez le fichier entier et entreposez-le (généralement dans un ou plusieurs tableaux)
- Fermer le fichier
- Ajoutez vos nouvelles entrées au tableau de données ou corrigez les entrées existantes
- Rouvrir le fichier pour une sortie séquentielle
- Sortie du tableau de données mis à jour dans le fichier
- Fermer le fichier
Si le fichier est trop volumineux pour tenir en mémoire, mettez-le à jour de la manière suivante :
- Ouvrir le fichier pour une saisie séquentielle
- Ouvrir un autre nouveau fichier de données pour une sortie séquentielle
- Saisir un bloc de données et mettre à jour les données si nécessaire
- Exporter les données vers le nouveau fichier
- Répétez les étapes 3 et 4 jusqu'à ce que toutes les données aient été lues, mises à jour et sorties dans le nouveau fichier ; puis passez à l'étape 6
- Fermez les deux fichiers
- Tuez l'ancien fichier de données
- Renommer le nouveau fichier (commande RENAME de TRSDOS) avec le nom de l'ancien fichier.
LINE INPUT séquentielle : Un exemple
En utilisant l'entrée orientée ligne, vous pouvez écrire des programmes éditant d'autres fichiers de programme BASIC : les renuméroter, changer LPRINT en PRINT,... - tant que ces programmes "cibles" sont entreposés au format ASCII.
Le programme suivant compte le nombre de lignes dans n'importe quel fichier de disque avec l'extension "/TXT".
10 CLEAR 300
20 INPUT "QUEL EST LE NOM DU PROGRAMME";PROG$
30 IF INSTR(PROG$,"/TXT")=0 THEN 110 ' REQUERE L'EXTENSION /TXT
40 OPEN"I",1,PROG$
50 I%=0
60 IF EOF(1)THEN 90
70 I%=I%+1:LINE INPUT#1,TEMP$
80 GOTO60
90 PRINT"LE PROGRAMME EST "I%" DE LIGNES DE LONG."
100 CLOSE:GOTO20
110 PRINT"FILESPEC DOIT INCLURE L'EXTENSION '/TXT'"
120 GOTO20
Pour les programmes BASIC entreposés en ASCII, chaque ligne de programme se termine par un caractère EN non précédé d'un saut de ligne LF. Ainsi, LINE INPUT à la ligne 70 lit automatiquement une ligne entière à la fois, dans la variable TEMP$. La variable I% fait le comptage.
Pour essayer le programme, enregistrez DISKDUMP/BAS en tant que fichier texte :
|
LOAD"DISKDUMP/BAS"ENTER SAVE"DISKDUMP/TXT",AENTER |
Cela vous donne une deuxième version au format ASCII de DISKDUMP. Tapez maintenant le programme du compteur de lignes et dites-lui d'examiner le programme DISKDUMP/TXT.
Entreposage sur disque lors d'un accès séquentiel
Une chose rendant l'accès séquentiel si simple est que vous pouvez généralement ignorer les détails de l'entreposage sur disque. Vous écrivez simplement vos données et relisez-les.
Vous trouverez ci-dessous quelques-uns des détails techniques et des conseils que vous devez garder à l'esprit. Dans certaines situations, ils deviendront importants.
- Les instructions PRINT# n'écrivent pas de données directement sur le disque ; à la place, les données sont placées dans le tampon de sortie de 256 octets. Lorsque ce tampon est rempli, le contenu est automatiquement écrit sur le disque. (La fermeture du fichier écrit également le tampon sur le disque.)
- Si un erreur DISK FULL ERROR se produit lors de l'exécution d'une instruction PRINT#, vous devez réaliser que le contenu actuel du tampon de sortie n'a pas été écrit dans le fichier. Les données du fichier disque sont intactes, mais elles ne contiennent pas les dernières valeurs de votre PRINT. Si vos variables contiennent encore les données, vous pouvez les récupérer directement.
Techniques d'accès aléatoire
L'accès aléatoire offre plusieurs avantages par rapport à l'accès séquentiel :
- Au lieu d'avoir à commencer la lecture au début d'un fichier, vous pouvez lire n'importe quel enregistrement que vous spécifiez.
- Pour mettre à jour un fichier, vous n'avez pas besoin de lire l'intégralité du fichier, de mettre à jour les données et de les réécrire. Vous pouvez réécrire ou ajouter à n'importe quel enregistrement de votre choix, sans avoir à parcourir les autres enregistrements.
- L'accès aléatoire est plus efficace - les données occupent moins d'espace et sont lues et écrites plus rapidement.
- L'ouverture d'un fichier pour un accès aléatoire vous permet d'écrire et de lire dans le fichier via le même tampon.
- L'accès aléatoire fournit de nombreuses instructions et fonctions puissantes pour structurer vos données. Une fois que vous avez mis en place la structure, l'entrée/sortie aléatoire devient assez simple.
Le dernier avantage listé ci-dessus est aussi la "partie difficile" de l'accès aléatoire. Il faut quand même un peu plus.
Aux fins de l'accès aléatoire, vous pouvez considérer un fichier disque comme un ensemble de boîtes - comme un mur de boîtes postales. Tout comme les réceptacles des bureaux de poste, les boîtes à dossiers sont numérotées.
Le nombre de cases dans un fichier varie, mais il s'agit toujours d'un multiple de 5.
Le plus petit fichier non vide contient 5 cases, numérotées de 1 à 5. Lorsque le fichier a besoin de plus d'espace pour contenir plus de données, TRSDOS le fournit par incréments de 5.
Ces boîtes de taille fixe sont appelées enregistrements. Chaque enregistrement contient 256 octets, dont 255 sont disponibles pour entreposer vos données.
Vous pouvez placer des données dans n'importe quel enregistrement ou lire le contenu de n'importe quel enregistrement, avec des instructions telles que :
PUT 1,5
écrit le contenu du tampon 1 dans l'enregistrement 5.
GET 1,5
lit le contenu de l'enregistrement 5 dans le tampon 1.
Le tampon est une zone d'attente pour les données. Avant d'écrire des données dans un fichier, vous devez les placer dans la mémoire tampon affectée au fichier. Après avoir lu les données d'un fichier, vous devez les récupérer dans la mémoire tampon.
Comme vous pouvez le voir dans les exemples d'instructions PUT et GET ci-dessus, les données sont transmises vers et depuis l e disque en blocs de 256 octets.
"C'est beaucoup de données." Mais la plupart des valeurs n'occupent que quelques octets :
| Type de données | Taille |
|---|---|
| Entiers | 2 |
| Nombres de simple précision | 4 |
| Nombres de double précision | 8 |
| Chaîne de caractères | Monte jusqu'à 255 |
Par conséquent, vous souhaiterez placer plusieurs valeurs dans le tampon avant de placer son contenu dans le fichier disque, pour éviter de gaspiller de l'espace disque.
Ceci est accompli en 1) divisant le tampon en champs et en les nommant, puis 2) en plaçant des données numériques dans les champs.
Par exemple, supposons que nous voulions entreposer un glossaire sur disque. Chaque enregistrement sera composé d'un mot suivi de sa définition. On commence par :
100 OPEN"R",1,"GLOSSARY/BAS"
110 FIELD 1,15 AS WD$,240 AS MEANING$
La ligne 100 ouvre un fichier nommé GLOSSAIRE/BAS (le crée s'il n'existe pas déjà) ; et donne au tampon 1 un accès aléatoire au fichier.
La ligne 110 définit deux champs sur le tampon 1 : WD$ se compose des 15 premiers octets du tampon ; MEANING$ comprend les 240 derniers octets. WD$ et MEANING$ sont maintenant des noms de champs.
Qu'est-ce qui différencie les noms de champs ? La plupart des variables de chaîne de caractères pointent vers une zone en mémoire appelée l'espace de chaîne de caractères. C'est là que la valeur de la chaîne est entreposée.
Les noms de champs, quant à eux, pointent vers la zone tampon affectée dans l'instruction FIELD. Ainsi, par exemple, l'énoncé :
10 PRINT WD$": " MEANING$
affiche le contenu des deux champs tampon définis ci-dessus.
Ces valeurs n'ont de sens que si nous plaçons d'abord les données dans le tampon. LSET, RSET et GET peuvent tous être utilisés pour accomplir cette fonction. Nous commencerons par LSET et RSET, étant utilisés en préparation de la sortie sur disque.
Notre première entrée est le mot "justifier à gauche" suivi de sa définition :
100 OPEN"R",1,"GLOSSARY/BAS"
110 FIELD 1,15 AS WD$,240 AS MEANING$
120 LSET WD$="JUSTIFIER A GAUCHE"
130 LSET MEANING$="POUR PLACER UNE VALEUR DANS UN CHAMP DE GAUCHE À DROITE ; SI LES DONNEES NE REMPLISSENT PAS LE CHAMP, DES BLANCS SONT AJOUTES À DROITE ; SI LES DONNEES SONT TROP LONGUES, LES CARACTERES SUPPLEMENTAIRES A DROITE SONT IGNORES. LSET EST UNE FONCTION DE JUSTIFICATION A GAUCHE."
La ligne 120 justifie à gauche la valeur entre guillemets dans le premier champ du tampon 1. La ligne 130 fait la même chose avec sa chaîne de caractères de guillemets. Lors de la saisie à la ligne 130, vous devez insérer des caractères de saut de ligne LF (appuyez sur la touche ↓) pour forcer les sauts de ligne comme ci-dessus. Cela facilite l'affichage des données après les avoir lues dans une variable de chaîne de caractères.
Remarque : RSET placerait des blancs de remplissage à gauche de l'élément. La troncature serait toujours à droite.
Maintenant que les données sont dans le tampon, nous pouvons les écrire sur le disque avec une simple instruction PUT :
140 PUT 1,1
150 CLOSE
Cela écrit le premier enregistrement dans le fichier GLOSSARY/BAS.
Pour lire et afficher le premier enregistrement dans GLOSSARY/BAS, utilisez la séquence suivante :
160 OPEN"R",1,"GLOSSARY/BAS"
170 FIELD 1,15 AS WD$,240 AS MEANING$
180 GET 1,1
190 PRINT WD$ ": " MEANING$
200 CLOSE
Les lignes 160 et 170 sont nécessaires uniquement parce que nous avons fermé le dossier à la ligne 150. Si nous ne l'avions pas fermé, nous pourrions passer directement à la ligne 180.
Accès aléatoire : une procédure générale
L'exemple ci-dessus montre les séquences nécessaires pour lire et écrire en utilisant un accès aléatoire. Mais il ne démontre pas les principaux avantages de cette forme d'accès - en particulier, il ne montre pas comment mettre à jour les fichiers existants en accédant directement à l'enregistrement souhaité.
Le programme ci-dessous, GLOSSACC/BAS, développe l'exemple de glossaire pour montrer certaines des techniques d'accès aléatoire pour la maintenance des fichiers. Mais avant de regarder le programme, étudiez cette procédure générale de création et de maintenance de fichiers via un accès aléatoire.
| Numéro de saut | Voir GLOSSACC/BAS, numéro de ligne |
|---|---|
| 1. OPEN le fichier | 110 |
| 2. FIELD le tampon | 120 |
| 3. GET l'enregistrement devant être mise à jour | 140 |
| 4. Afficher le contenu actuel de l'enregistrement (CVD, CVI, CVS avant d'afficher les données numériques) | 145-170 |
| 5. LSET et RSET nouvelles valeurs dans les champs (utilisez MKD$, MKI$, MKS$ avec des données numériques avant de les mettre dans la mémoire tampon). | 210-230 |
| 6. PUT l'enregistrement mis à jour | 240 |
| 7. Pour mettre à jour un autre enregistrement, passez à l'étape 3. Sinon, passez à l'étape 8. | 250-260 |
| 8. Ferme le fichier | 270 |
10 REM... GLOSSACC/BAS...
100 CLS:CLEAR 300
110 OPEN"R",1,"GLOSSARY/BAS"
120 FIELD 1,25 AS WD$,228 AS MEANING$,2 AS NX$
130 INPUT"A QUELLE DOSSIER VOULEZ-VOUS ACCEDER";R%
140 GET 1,R%
145 NX%=CVI(NX$) ' ENREGISTRER LE LIEN VERS L'ENTREE ALPHABETIQUE SUIVANTE
150 PRINT"MOT: "WD$
160 PRINT"DEF'N":PRINT MEANING$
170 PRINT"ENTREE ALPHABETIQUE SUIVANTE : ENREGISTREMENT#"NX%:PRINT
180 W$="":INPUT"TAPEZ NOUVEAU MOT <EN> OU <EN> SI OK";W$
190 D$="":PRINT"SAISIR NOUVEAU DEF'N<EN> OU <EN> SI OK ?";LINEINPUTD$
200 INPUT"SAISIR LE NOUVEAU NUMERO DE SEQUENCE OU <EN> SI OK";NX%
210 IF W$<>""THEN LSET WD$=W$
220 IF D$<>""THEN LSET MEANING$=D$
230 LSET NX$=MKI$(NX%)
240 PUT 1,R%
245 R%=NX% ' UTILISEZ LA PROCHAINE ALPHA. LIEN PAR DEFAUT POUR L'ENREGISTREMENT SUIVANT
250 CLS:INPUT" TYPE<EN> POUR LIRE L'ALPHA SUIVANT. ENTREE OU ENREGISTREMENT # <EN> POUR UNE ENTREE SPECIFIQUE, OU 0 <EN> POUR QUITTER"
260 IF 0<R% THEN 140
270 CLOSE
END
Notez que nous avons ajouté un champ, NX$, à l'enregistrement (ligne 120). NX$ contiendra le numéro de l'enregistrement venant ensuite dans l'ordre alphabétique. Cela nous permet de parcourir le glossaire par ordre alphabétique, à condition de savoir quelle avertissement contient l'entrée devant apparaître en premier.
Par exemple, supposons que le glossaire contienne :
| # enregistrement | Mot (WD$) | defn. | Pointeur la prochaine entrée (NX$) |
|---|---|---|---|
| 1 | JUSTIFIER-A-GAUCHE | ... | 3 |
| 2 | OCTET | ... | 4 |
| 3 | JUSTIFIER-A-DROITE | ... | 0 |
| 4 | HEXADECIMAL | ... | 1 |
Lorsque nous lisons l'enregistrement 2 (OCTET), il nous indique que l'enregistrement 4 (HEXADECIMAL) est le suivant, ce qui indique ensuite que l'enregistrement 1 (JUSTIFIER-A-GAUCHE) est le suivant, etc. La dernière entrée, l'enregistrement 3 (JUSTIFIER-A-DROITE), pointe à zéro, ce que nous prenons pour signifier "LA FIN".
Puisque NX$ contiendra un entier, nous devons d'abord convertir ce nombre en une représentation de chaîne à deux octets, en utilisant MKI$ (ligne 230 ci-dessus).
| RUN"GLOSSACC/BAS"ENTER |
on obtiendra le résultat suivant :
A QUEL DOCUMENT SOUHAITEZ-VOUS ACCEDER? 4ENTERMOT: HEXADECIMAL
DEF'N
CAPABLE DE SORTIR DANS N'IMPORTE QUEL DES 16 ETATS, PAR EXEMPLE, LES CHIFFRES HEXADECIMAUX 0,1,2,...,9,A,B,C,D,E,F. LES NOMBRES HEXADECIMAUX SONT DES CHAINES DE CHIFFRES HEXADECIMAUX.
ENTREE ALPHABETIQUE SUIVANTE : ENREGISTREMENT# 1
TAPEZ NOUVEAU MOT <EN> OU <EN> SI OK ? HEXADECIMALENTER
SAISIR NOUVEAU DEF'N<EN> OU <EN> SI OK ? ENTER
SAISIR LE NOUVEAU NUMERO DE SEQUENCE OU <EN> SI OK ? ENTER
ensuite :
TYPE<EN> POUR LIRE L'ALPHA SUIVANT. ENTREEOU ENREGISTREMENT # <EN> POUR UNE ENTREE SPECIFIQUE,
OU 0 <EN> POUR QUITTER ? ENTER MOT: JUSTIFIER-A-GAUCHE DEF'N: POUR PLACER DES DONNEES DANS UN CHAMP DE GAUCHE A DROITE, EN AJOUTANT DES BLANCS
SI NECESSAIRE SUR LA DROITE POUR REMPLIR LE CHAMP. TOUS LES CARACTERES SUPPLEMENTAIRES
A DROITE SONT IGNORES.
PROCHAIN ENTREE ALPHABETIQUE: ENREGISTREMENT# 3
TAPEZ NOUVEAU MOT <EN> OU <EN> SI OK ? ENTER
SAISIR NOUVEAU DEF'N<EN> OU <EN> SI OK ? ENTER
SAISIR LE NOUVEAU NUMERO DE SEQUENCE OU <EN> SI OK ? 2ENTER
Le programme suivant affiche le glossaire dans l'ordre alphabétique :
300 REM... GLOSSOUT/BAS...
310 CLS: CLEAR 300
320 OPEN"R",1,"GLOSSARY/BAS"
330 FIELD 1,15 AS WD$,238 AS MEANING$,2 AS NX$
340 INPUT"QUEL ENREGISTREMENT EST LE PREMIER ALPHABETIQUE";N%
350 GET 1,N%
360 PRINT:PRINT WD$
370 PRINT MEANING$
380 N%=CVI(NX$)
390 INPUT"PRESSE ENTER POUR CONTINUER";X
400 IF N%<>0 THEN 350
410 CLOSE
420 END
Sous-enregistrements
Dans l'exemple du glossaire, chaque entrée nécessitait la totalité des 255 octets disponibles dans la mémoire tampon. Ce n'est souvent pas le cas. Lorsque chaque unité d'information ne remplit qu'une partie du tampon, il est judicieux de définir plusieurs sous-enregistrements identiques sur le tampon. De cette façon, vous ne gaspillez pas d'espace disque en mettant des enregistrements ne contenant que quelques octets d'informations utiles.
Par exemple, supposons que nous voulions entreposer une liste de diffusion, et chaque entrée consistera en :
| Champ | Longueur du champ |
|---|---|
| Nom | 18 |
| Adresse | 25 |
| Ville | 14 |
| Etat | 2 |
| Montant du dernier achat | 4 |
| Longueur totale de l'entrée : 63 | |
Remarque : Le montant du dernier achat sera un nombre simple précision. De telles valeurs nécessitent 4 octets, donc la longueur du champ est de 4.
Si nous ne nous soucions pas de gaspiller de l'espace sur le disque, nous pourrions utiliser l'instruction suivante :
FIELD 1, 18 AS NM$,25 AS AD$,14 AS CTY$,2 AS ST$,4 AS LP$
La mise en place d'un tel tampon créerait un enregistrement composé de 63 octets d'informations suivis de 255-63 = 192 octets inutilisés.
Une approche plus efficace divise le tampon en sous-enregistrements identiques. Dans ce cas, nous pouvons créer 255/63=4 sous-enregistrements plus seulement 3 octets perdus à la fin.
Au lieu d'utiliser une très longue instruction FIELD pour affecter explicitement chaque champ, nous rechampons le tampon une fois pour chaque sous-enregistrement, en utilisant une chaîne de caractères factice, STARTHERE$, pour démarrer chaque sous-enregistrement à la position appropriée dans le tampon.
FOR I%=0 TO 3
FIELD 1,(I%*63) AS STARTHERE$,18 AS NM$(I%),25 AS AD$(I%),14 AS CTY$(I%),2 AS ST$(I%),4 AS LP$(I%)
NEXT
La première fois dans la boucle, STARTHERE$ aura une longueur de zéro. Par conséquent, NM$(0) commencera au premier octet ; AD$(0), au 19ème octet,... LP$(0) se terminera au 63ème octet.
La deuxième fois dans la boucle, STARTHERE$ aura une longueur de 63. Par conséquent, NM$(1) commencera au 64e octet ; AD$(1), au 92e octet,... ; LPS$(1) se terminera au 126ème octet.
Et ainsi de suite, jusqu'à ce que le tampon soit complètement défini.
Pour placer des valeurs dans les sous-enregistrements du tampon : supposez que nos entrées de liste de diffusion sont entreposées dans quatre tableaux, N$(), A$(), C$(), S$(), LP().
Ensuite, nous pouvons remplir le tampon avec quatre entrées comme suit :
FOR I%=0 TO 3
LSET NM$(I%)=N$(I%)
LSET AD$(I%)=A$(I%)
LSET CT$(I%)=C$(I%)
LSET ST$(I%)=S$(I%)
LSET LP$(I%)=MKS$(LP(I%))
NEXT
Comment accéder aux sous-enregistrements
Étant donné que chaque enregistrement d'un tel fichier contiendra quatre sous-enregistrements, nous avons besoin d'un moyen d'extraire le sous-enregistrement souhaité. Cela nécessite que chaque sous-enregistrement ait un numéro unique pouvant être lié à l'enregistrement qui le contient.
Pour cet exemple, supposons que nous ayons une affichage de toute la liste de diffusion, en commençant par le premier sous-enregistrement de l'enregistrement 1 et en passant par le dernier sous-enregistrement du dernier enregistrement. Nous les numérotons ensuite séquentiellement, en commençant par 1.
Les formules suivantes utilisent ce numéro (nous l'appellerons un numéro-clef) pour déterminer exactement où se trouve le sous-enregistrement dans le fichier :
Si le numéro-clef du sous-enregistrement est KEY%, alors :
PR%=INT((KEY%-1)/4)+1
où PR% est l'enregistrement physique contenant le sous-enregistrement, et :
SR%=KEY%-4*(PR%-1)
où SR% est le numéro de sous-enregistrement à l'intérieur de l'enregistrement physique. Par exemple, supposons que nous voulions accéder à l'entrée avec le numéro de clef = 37 (c'est-à-dire, le 37e entrée). Alors l'enregistrement physique la contenant est :
| INT((37-1)/4)+1 → enregistrement 10 |
et sa position dans l'enregistrement 10 est :
| 37-4*(10-1)+1 → numéro du sous-enregistrement 1 |
Un programme de travail complet pour créer et manipuler une liste de diffusion suit :
100 CLEAR 1000
110 OPEN"R",1,"MAIL/BAS"
120 CLS:INPUT"TAPEZ 1<EN> POUR ECRIRE, 2<EN> POUR LIRE, 0,<EN> POUR QUITTER";N%
130 IF N%=0 THEN CLOSE:END
140 INPUT"TYPE NUMERO DE TOUCHE<EN> OU 0<EN>";KEY%
150 IF KEY%=0 THEN 120
160 PR%=INT((KEY%-1)/4)+1
170 SR%=KEY%-4*(PR%-1)
180 FIELD 1,((SR%-1)*63) AS STARTHERE$,18 AS NM$,25 AS AD$,14 AS CTY$,2 AS ST$,4 AS LP$
190 GET 1,PR%
200 IF N%=2 THEN 300
210 PRINT"ECRIRE UN SOUS-ENREGISTREMENT #"SR%" DANS UN ENREGISTREMENT PHYSIQUE #"PR%
220 PRINT:PRINT"NOM?"TAB(20);:LINEINPUT N$:LSET NM$=N$
230 PRINT"ADRESSE?"TAB(20);:LINEINPUT A$:LSET AD$=A$
240 PRINT"VILLE?"TAB(20);:LINEINPUT A$:LSET CTY$=C$
250 PRINT"ETAT?"TAB(20);:LINEINPUT S$:LSET ST$=S$
260 PRINT"DERNIERE ACHAT"TAB(20);:INPUTLP:LSET LP$=MKK$(LP)
270 PUT 1,PR%:PRINT:INPUT"PRESSE <EN> POUR ALLER DANS";X:GOTO 120
300 PRINT"LECTURE DE SOUS-ENREGISTREMENT #"SR%" DANS UN ENREGISTREMENT PHYSIQUE #"PR%
310 PRINT:PRINT"NOM"TAB(20)NM$
320 PRINT"ADRESSE"TAB(20)AD$
330 PRINT"VILLE"TAB(20)CTY$
340 PRINT"ETAT"TAB(20)ST$
350 PRINT USING"DERNIER ACHAT $####.##";CVS(LP$)
360 PRINT:INPUT"PRESSE <EN> POUR ALLER DANS";X:GOTO 120
Ce programme ne vous demande en fait pas de remplir le tampon avec quatre sous-enregistrements significatifs. Dès que vous avez placé un sous-enregistrement dans le bon champ, le tampon entier est écrit sur le disque. Cependant, l'espace supplémentaire n'est pas perdu ; il est toujours disponible pour l'ajout de sous-enregistrements ultérieurs.
Notez que ce ne serait pas le moyen le plus efficace de créer une liste en une seule "séance". Dans un tel cas, vous voudriez probablement remplir le tampon avec quatre sous-enregistrements avant d'écrire sur le disque. Le programme ci-dessus vous montre cependant comment mettre à jour un fichier en utilisant un accès aléatoire.
| RUN"MAILACC/BAS"ENTER |
on obtiendra un résultat ressemblant à ceci :
TAPEZ 1<EN> POUR ECRIRE, 2<EN> POUR LIRE, 0,<EN> POUR QUITTER? 1ENTERTYPE NUMERO DE TOUCHE<EN> OU 0<EN>? 3ENTER
ECRIRE UN SOUS-ENREGISTREMENT # 3 DANS UN ENREGISTREMENT PHYSIQUE # 1
NOM? JEAN TREMBLAY
ADRESSE? 2222 RUE DES VENTS
VILLE? VIEUX PORT
ETAT? QC
DERNIER ACHAT ? 12.81
PRESSE <EN> POUR ALLER DANS?ENTER
ensuite :
TAPEZ 1<EN> POUR ECRIRE, 2<EN> POUR LIRE, 0,<EN> POUR QUITTER? 2ENTERTYPE NUMERO DE TOUCHE<EN> OU 0<EN>? 1ENTER
ECRIRE UN SOUS-ENREGISTREMENT # 1 DANS UN ENREGISTREMENT PHYSIQUE # 1
NOM? CLAUDE GAGNON
ADRESSE? 1222 RUE DES POMMES
VILLE? NOUVEAU PORT
ETAT? ON
DERNIER ACHAT ? 188.75
PRESSE <EN> POUR ALLER DANS?ENTER
enfin :
TAPEZ 1<EN> POUR ECRIRE, 2<EN> POUR LIRE, 0,<EN> POUR QUITTER? 2ENTERTYPE NUMERO DE TOUCHE<EN> OU 0<EN>? 0ENTER
READY >_
Champs se chevauchant
Supposons que vous vouliez accéder à un champ de deux manières - en totalité et en partie. Ensuite, vous pouvez attribuer deux noms de champ à la même zone du tampon.
Par exemple, si les deux premiers chiffres d'un numéro d'entreposage à six chiffres spécifient une catégorie, vous pouvez utiliser la structure de champ suivante :
FIELD 1,6 AS STOCK$,...
FIELD 1,2 AS CTG$,...
Désormais, STOCK$ référencera l'intégralité du champ du numéro d'entreposage, tandis que CTG$ référencera uniquement les deux premiers chiffres du numéro.