
Gérer les données avec Transact-SQL
Le Transact-SQL (T-SQL) est le langage principal utilisé pour gérer et manipuler les données dans SQL Server et Azure SQL Database. Si vous travaillez avec l'un des produits SQL de Microsoft - en tant que développeur, DBA, professionnel de la BI, analyste de données, scientifique des données ou à tout autre titre - vous devez connaître votre T-SQL.
Créer des requêtes Transact-SQL SELECT
Pour écrire du code T-SQL correct et robuste, il est important de comprendre d'abord les racines du langage, ainsi qu'un concept appelé traitement de requête logique. Vous devez également comprendre la structure de l'instruction SELECT et comment utiliser ses clauses pour effectuer des tâches de manipulation de données telles que le filtrage et le tri. Vous devez souvent combiner des sources différentes, et l'un des moyens d'y parvenir dans T-SQL consiste à utiliser des opérateurs ensemblistes.
Comprendre les fondements de T-SQL
De nombreux aspects de l'informatique, comme les langages de programmation, évoluent en fonction de l'intuition et de la tendance actuelle. Sans fondements solides, leur durée de vie peut être très courte, et s'ils survivent, les changements sont souvent très rapides en raison des changements de tendances. Le T-SQL est différent, principalement parce qu'il repose sur des bases solides - les mathématiques. Vous n'avez pas besoin d'être mathématicien pour bien écrire du SQL, mais tant que vous comprenez ce que sont ces fondements et certains de leurs principes clefs, vous comprendrez mieux le langage que vous utilisez.
Évolution de T-SQL
Comme mentionné, contrairement à de nombreux autres aspects de l'informatique, le T-SQL est basé sur de solides bases mathématiques. Comprendre certains des principaux principes de ces fondations peut vous aider à mieux comprendre la langue avec laquelle vous traitez. Ensuite, vous penserez en termes T-SQL lors du codage de T-SQL, par opposition au codage avec T-SQL tout en pensant en termes procéduraux.
Le T-SQL est le langage principal utilisé pour gérer et manipuler les données dans les systèmes de gestion de base de données relationnelle (SGBDR) SQL Server (le produit de la boîte) et Azure SQL Database (la plate-forme infonuagique). La base de code pour la plate-forme infonuagique et le produit en boîte est une base de code unifiée. Pour plus de simplicité, le terme SQL Server en référence aux deux, en ce qui concerne T-SQL. Le SQL Server prend également en charge d'autres langages, tels que Visual C# et Visual Basic .NET, mais T-SQL est généralement le langage préféré pour la gestion et la manipulation des données.
Le T-SQL est un dialecte du SQL standard. Le SQL est une norme de l'Organisation internationale de normalisation (ISO) et de l'American National Standard Institute (ANSI). Les deux normes pour SQL sont fondamentalement les mêmes. La norme SQL ne cesse d'évoluer avec le temps. Voici une liste des principales révisions de la norme à ce jour :
- SQL-86
- SQL-89
- SQL-92
- SQL:1999
- SQL:2003
- SQL:2006
- SQL:2008
- SQL:2011
Tous les principaux fournisseurs de bases de données, y compris Microsoft, mettre ne oeuvre un dialecte de SQL comme langage de programmation principal pour gérer et manipuler les données dans leurs plateformes de bases de données. Par conséquent, les éléments de base du langage se ressemblent. Cependant, chaque fournisseur décide quelles fonctionnalités implémenter et quelles fonctionnalités ne pas implémenter. De plus, la norme laisse parfois certains aspects comme choix d'implémentation. Chaque fournisseur met en oeuvre également généralement des extensions à la norme dans les cas où le fournisseur estime qu'une fonctionnalité importante n'est pas couverte par la norme.
Écrire de manière standard est considéré comme une bonne pratique. Lorsque vous le faites, votre code est plus portable. Vos connaissances sont également plus portables, car il vous est facile de commencer à travailler avec de nouvelles plates-formes. Lorsque le dialecte avec lequel vous travaillez prend en charge à la fois une manière standard et non standard de faire quelque chose, vous devriez toujours préférer la forme standard comme choix par défaut. Vous ne devriez envisager une option non standard que lorsqu'elle présente pour vous un avantage important que celui couvert par l'alternative standard.
À titre d'exemple de choix de la forme standard, T-SQL prend en charge deux opérateurs "différent de" : <> et !=. Le premier est standard et le second ne l'est pas. Dans ce cas, le choix devrait être évident : optez pour le standard !
Comme exemple de cas où le choix de standard ou non standard dépend des circonstances, considérez ce qui suit : T-SQL prend en charge plusieurs fonctions convertissant une expression source en un type cible. Parmi elles se trouvent les fonctions CAST et CONVERT. Le premier est standard et le second ne l'est pas. La fonction CONVERT non standard a un paramètre de style que CAST ne prend pas en charge. Étant donné que CAST est standard, vous devez le considérer comme votre choix par défaut pour les conversions. Vous devriez envisager d'utiliser CONVERT uniquement lorsque vous devez vous fier au paramètre de style.
Un autre exemple de choix de la forme standard est la terminaison des instructions T-SQL. Selon la norme SQL, vous devez terminer vos instructions par un point-virgule. La documentation T-SQL spécifie que ne pas terminer toutes les instructions par un point-virgule est une fonctionnalité déconseillée, mais T-SQL ne l'applique actuellement pas à toutes les instructions, mais uniquement dans les cas où il y aurait autrement une ambiguïté des éléments de code. Par exemple, une instruction précédant la clause WITH d'une expression de table commune (CTE) doit être terminée car cette clause peut également être utilisée pour définir un indicateur de table dans l'instruction précédente. Comme autre exemple, l'instruction MERGE doit être terminée en raison d'une ambiguïté possible du mot clef MERGE. Vous devez toujours suivre la norme et mettre fin à toutes vos déclarations, même lorsque cela n'est actuellement pas requis.
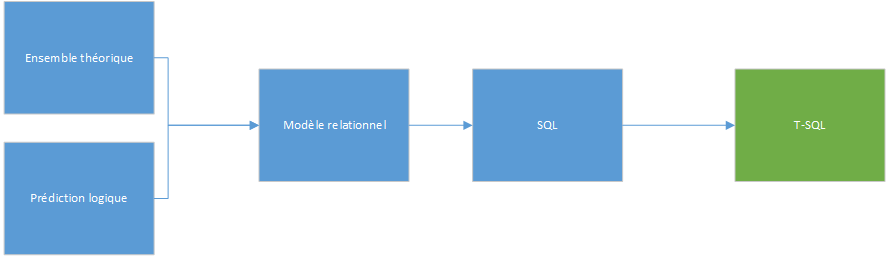
Le SQL standard est basé sur le modèle de relation, étant un modèle mathématique pour la gestion et la manipulation des données. Le modèle de relation a été initialement créé et proposé par Edgar F. Codd en 1969. Après sa création, il a été expliqué et développé par Codd, Chris Date, Hugh Drawen et d'autres.
Une idée fausse courante est que le nom «relationnel» est à voir avec les relations entre les tables (c'est-à-dire les clefs étrangères). En fait, la véritable source du nom du modèle est la relation de concept mathématique. Une relation dans le modèle de relation est ce que SQL représente avec une table. Les deux ne sont pas synonymes. On pourrait dire qu'une table est une tentative par SQL de représenter une relation (en plus d'une variable de relation, mais ce n'est pas nécessaire d'en parler ici). Certains disent que ce n'est pas une tentative très réussie. Même si SQL est basé sur le modèle relationnel, il s'en écarte de plusieurs manières. Mais il est important de noter qu'au fur et à mesure que vous comprenez les principes du modèle, vous pouvez utiliser SQL - ou plus précisément, le dialecte que vous utilisez - de manière relationnelle.
Pour en revenir à une relation, c'est ce que SQL essaie de représenter avec une table : une relation a un entête et un corps. L'entête est un ensemble d'attributs (ce que SQL tente de représenter avec des colonnes), chacun d'un type donné. Un attribut est identifié par un nom et un nom de type. Le corps est un ensemble de tuples (ce que SQL tente de représenter avec des lignes). L'entête de chaque tuple est l'entête de la relation. Chaque valeur de l'attribut de chaque tuple est de son type respectif. Certains des aspects les plus importants à comprendre à propos de T-SQL découlent des fondements fondamentaux du modèle relationnel : la théorie des ensembles et la logique des prédicats.
N'oubliez pas que l'entête est un ensemble d'attributs et que le corps est un ensemble de tuples. Alors, qu'est-ce qu'un ensemble ? Selon le créateur de la théorie mathématique des ensembles, Georg Cantor, un ensemble est décrit comme suit : «Par "ensemble", nous entendons toute collection M en un ensemble d'objets m définis et distincts (étant appelés les «éléments» de M) de notre perception ou de notre pensée.»
Il y a un certain nombre d'éléments très importants dans la définition qui, s'ils sont compris, devraient avoir des implications directes sur vos pratiques de codage T-SQL. Un élément nécessitant un avis est le terme entier. Un ensemble doit être considéré comme un tout. Cela signifie que vous n'interagissez pas avec les éléments individuels de l'ensemble, mais plutôt avec l'ensemble dans son ensemble. Remarquez le terme distinct; un ensemble n'a pas de doublons. Codd a fait remarquer une fois sur l'aspect de l'absence de doublons : «Si quelque chose est vrai, le dire deux fois ne le rendra pas plus vrai.» Par exemple, l'ensemble {a, b, c} est considéré égal à l'ensemble {a, a, b, c, c, c}. Un autre aspect critique d'un ensemble n'apparaît pas explicitement dans la définition susmentionnée de Cantor, mais est plutôt implicite ; il n'y a aucune pertinence pour l'ordre des éléments dans un ensemble. En revanche, une séquence (étant un ensemble ordonné) a un ordre pour ses éléments. La combinaison des aspects aucun doublon et aucune pertinence pour l'ordre signifie que la collection {a, b, c} est telle que définie, mais pas la collection (b, a, c, c, a, c).
L'autre branche des mathématiques sur laquelle le modèle de relation est basé s'appelle la logique des prédicats. Un prédicat est une expression qui, lorsqu'elle est attribuée à un objet, fait une proposition vraie ou fausse. Par exemple, «salaire supérieur à 45 000 $» est un prédicat. Vous pouvez évaluer ce prédicat pour un employé spécifique, auquel cas vous avez une proposition. Par exemple, supposons que pour un employé en particulier, le salaire est de 50 000 $. Lorsque vous évaluez la proposition pour cet employé, vous obtenez une proposition vraie. En d'autres termes, un prédicat est une proposition paramétrée.
Le modèle relationnel utilise des prédicats comme l'un de ses éléments de base. Vous pouvez appliquer l'intégrité des données à l'aide de prédicats. Vous pouvez filtrer les données à l'aide de prédicats. Vous pouvez même utiliser des prédicats pour définir le modèle de données lui-même. Vous d'abord les propositions d'identité devant être entreposées dans la base de données. Voici un exemple de proposition : une commande avec l'ID de commande 12345 a été passée le 16 février 2007 par le client avec l'ID 77, et traitée par l'ID d'employé 37. Vous créez ensuite des prédicats à partir des propositions en supprimant les données et en gardant l'entête. N'oubliez pas que l'entête est un ensemble d'attributs, chacun identifié par un nom et un nom de type. Dans cet exemple, vous avez orderid INT, orderdate DATE, custid INT et empid INT.
Utiliser T-SQL de manière relationnelle
Comme mentionné, T-SQL est basé sur SQL, qui à son tour est basé sur le modèle relationnel. Cependant, il existe un certain nombre de façons dont SQL, et donc T-SQL, s'écarte du modèle relationnel. Mais T-SQL vous donne suffisamment d'outils pour que si vous comprenez le modèle de relation, vous puissiez utiliser le langage de manière relationnelle, et ainsi écrire un code plus correct.
Rappelez-vous qu'une relation a un titre et un corps. Le titre est un ensemble d'attributs et le corps est un ensemble de tuples. Rappelons qu'un ensemble est censé être considéré comme un tout. C'est que cela se traduit dans T-SQL et que vous êtes censé écrire des requêtes interagissant avec les tables dans leur ensemble. Vous devriez essayer d'éviter d'utiliser des constructions itératives telles que des curseurs et des boucles parcourant les lignes une par une. Vous devriez également essayer d'éviter de penser en termes itératifs, car ce type de pensée est ce qui conduit à des solutions itératives.
Pour les personnes ayant une formation en programmation procédurale, la façon naturelle d'interagir avec les données (dans un fichier, un ensemble d'enregistrements ou un lecteur de données) consiste à effectuer des itérations. Ainsi, l'utilisation de curseurs et d'autres constructions itératives dans T-SQL est, en quelque sorte, une extension de ce qu'ils savent déjà. Cependant, la manière correcte du point de vue du modèle relationnel n'est pas d'interagir avec les lignes une à la fois, mais plutôt d'utiliser des opérations relationnelles et de renvoyer un résultat relationnel. Ceci, en T-SQL, se traduit par l'écriture de requêtes.
N'oubliez pas non plus qu'un ensemble n'a pas de doublons. En d'autres termes, il a des membres uniques. Le T-SQL n'applique pas toujours cette règle. Par exemple, vous pouvez créer une table sans clef. Dans ce cas, vous êtes autorisé à avoir des lignes en double dans la table. Pour suivre la théorie relationnelle, vous devez appliquer l'unicité dans vos tables. Par exemple, vous pouvez imposer l'unicité dans vos tables en utilisant une clef primaire ou une contrainte unique.