Notion de typage
On entend par «typage», l'association d'un type à un objet (souvent une variable), d'un ensemble de valeurs supportées (ou possible) ou d'une liste d'opérations applicable sur ces valeurs. L'idée dernière cette notion, s'est qu'il faut intégré une forme de conformité afin que le langage de programmation est la possibilité de vérifier que les valeurs fournies ont le même sens pour tous (qu'ils sont compatibles avec l'opération) et que l'opération ne rentre pas en contradiction avec la réaction doit avoir ce type d'opération. Par exemple, si vous faites 1 + 1, vous vous attendez à avoir 2 comme réponse et non pas 10 ! Ainsi, le typage doit être pareil pour tous !
Différence de typage
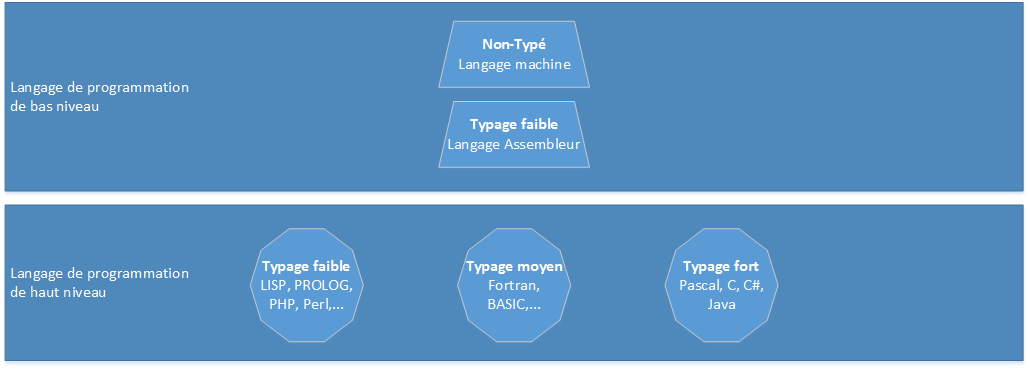
Les langages de programmation n'ayant pas de type, aussi appelé non-typé, désigne essentiellement les langages machine, soit un ensemble de valeurs de type entières correspondant à un ensemble d'instructions de machine précise. Le langage machine est soit utilisé directement sur les puces électroniques (par les manufacturiers) ou les machines virtuelles. Ainsi, dans le domaine de l'éducation, scientifique, du gouvernement ou du commerce, ils ne sont pas utilisés.
De leur côté, les langages de programmation assembleurs, toujours directement associés avec les caractéristiques physiques du microprocesseur ou du jeu d'instructions d'une machine virtuel, offrent la possibilité d'associer des mnémoniques aux différentes opérations pouvant être effectuées. A ce niveau, nous avons encore un typage très faible, puisqu'il est par exemple possible de déclarer des constantes de nombre entier dans différentes bases, des constantes de caractère, des constantes de chaine de caractères et des constantes de nombre réel. Il n'existe pourtant aucun contrôle lorsqu'on parle de la correspondance entre le type de la constante et l'opération à effectuer. Par exemple, le caractère «A» pourrait être perçu aussi bien comme le chiffre 65, que comme la valeur booléenne vraie.
Pour les langages de programmation détachée de la machine, il y a trois lignes de pensées, le typage est fort, le typage moyen ou le typage faible. Le typage fort est fortement incrusté dans les langages de programmation comme le Pascal, le C, le C# et le Java par exemple. Le typage moyen est présent dans des langages de programmation comme BASIC et Fortran. Le typage faible est présent dans des langages de programmation comme LISP, PROLOG, PHP, Perl. Durant la période des années 1965 à 1995, la tendance s'alignait vers le typage fort, comme par avec l'Algol (1968), Pascal (1971), Modula-2 (1980) et l'Ada (1980), Java (1995), mais après cette période et l'arrivée de l'INTERNET, l'intérêt pour les typages faibles et les typages moyens est revenu à la hausse. La raison pour laquelle le typage fort était préconisé résidait dans le fait qu'il était presque toujours compilé et qu'ainsi il était possible de déceler de nombreuses erreurs avant l'exécution du programme. De plus, à l'occasion, il permet de déceler des incohérences.
Contrôle de typage
Le contrôle de typage est un mécanisme dans les langages de programmation garantissant que les opérations effectuées sur des variables sont compatibles avec les types de données associés. Il existe deux approches principales pour vérifier si deux types sont équivalents ou compatibles : l'équivalence de nom et l'équivalence de structure. Chaque langage de programmation implémente ces approches de manière différente, ce qui influe sur la rigueur du typage et la sécurité du programme.
Équivalence de nom
L'équivalence de nom repose sur l'idée que deux types sont considérés comme équivalents uniquement s'ils ont été explicitement déclarés sous le même nom. Cela signifie que même si deux types ont des structures identiques, ils ne seront pas considérés comme compatibles s'ils portent des noms différents. Cette approche est plus stricte et garantit que les développeurs ne confondent pas des types de données similaires, mais conceptuellement différents.
Voici un exemple en Pascal :
Dans ce cas, bien que TPerson et TEmployee aient exactement la même structure (deux champs Name et Age), ils ne seront pas considérés comme équivalents sous le principe de l'équivalence de nom.
Équivalence de structure
L'équivalence de structure se concentre sur la composition interne des types. Deux types sont considérés comme équivalents s'ils ont la même structure, c'est-à-dire qu'ils contiennent les mêmes champs ou composantes dans le même ordre et avec les mêmes types de données. Ici, le nom du type n'est pas important tant que les structures sont identiques.
Voici un exemple en langage de programmation C (utilisant parfois l'équivalence de structure) :
En langage de programmation C, struct Person et struct Employee pourraient être considérés comme équivalents dans certains contextes car leurs structures sont identiques, même si leurs noms diffèrent. Cette approche offre plus de flexibilité au programmeur, mais elle peut également introduire des risques si des types semblant similaires mais ayant des usages différents sont confondus.
Cas de quelques langages d'usage courant
Les langages de programmation populaires adoptent différentes stratégies de contrôle de typage en fonction de leurs objectifs et de leur conception :
- Pascal : Pascal utilise principalement l'équivalence de nom. Deux types définis sous des noms différents, même s'ils sont structurellement identiques, ne sont pas considérés comme équivalents. Cela impose un typage strict pour une meilleure clarté du code.
- C : Le langage C tend à favoriser l'équivalence de structure dans certains cas, notamment avec les structures (struct). Cela permet de partager des structures identiques sans avoir à déclarer les mêmes types sous le même nom.
- Go : Le langage de programmation Go utilise l'équivalence de structure pour les interfaces. Si deux interfaces ont la même méthode, elles sont considérées comme équivalentes, même si elles ne portent pas le même nom.
- Java : Java repose sur l'équivalence de nom pour les classes et les interfaces. Si deux classes ou interfaces ne portent pas le même nom, elles ne sont pas équivalentes, même si leurs méthodes ou attributs sont identiques.
Nomenclature
La nomenclature fait référence à l'ensemble des règles, des conventions et des principes utilisés pour nommer et classifier les différents types de données dans un programme. Ces conventions sont cruciales pour maintenir une organisation claire et cohérente des données, permettant une compréhension rapide et efficace du code par les développeurs.
La nomenclature dans la notion de types se concentre principalement sur la manière dont les types de données, qu'ils soient primitifs ou complexes, sont nommés et organisés dans le code. Cela inclut la création de types de données personnalisés (comme les structures, les classes ou les énumérations) et leur utilisation cohérente. Une bonne nomenclature permet non seulement de rendre le code lisible, mais aussi de minimiser les erreurs liées à une mauvaise utilisation des types de données.
Rôle et importance de la nomenclature dans les types
- Clarté des types de données : La nomenclature des types doit permettre de distinguer rapidement les différents types de données dans le code. Par exemple, dans un langage de programmation comme Pascal, les types tels que Integer, String, ou Boolean doivent être clairement définis et leurs noms doivent refléter leur rôle et leur nature.
- Création de types personnalisés : Les développeurs peuvent définir leurs propres types de données pour organiser des informations complexes. Par exemple, la création d'un type TEmployee dans un système de gestion des employés aide à structurer et à clarifier les données associées à chaque employé.
- Noms explicites et significatifs : Les types doivent avoir des noms suffisamment descriptifs pour que leur rôle soit immédiatement compris. Par exemple, utiliser TCompteBancaire pour représenter un compte bancaire est plus clair que d'utiliser simplement Compte ou un nom générique.
Exemples de nomenclature des types en Pascal :
En résumé, la nomenclature dans la notion de types est essentielle pour s'assurer que les structures de données soient faciles à comprendre, à utiliser et à maintenir. Elle contribue à une bonne lisibilité du code et à une gestion efficace des erreurs de types dans les programmes.