Files d'attente, piles, listes liées et arborescences
Les programmes se composent d'algorithmes et de structures de données. Le bon programme est un mélange des deux. Le choix et la mise en oeuvre d'une structure de données sont aussi importants que la routine manipulant les données. La manière dont les informations sont organisées et accessibles est généralement déterminée par la nature du problème de programmation. Par conséquent, en tant que programmeur, vous devez avoir dans votre «sac de trucs» sur les bonnes méthodes d'entreposage et de récupération pour chaque situation.
La représentation réelle des données dans l'ordinateur est construite «à partir de zéro», en commençant par les types de données de base tels que char, integer et real. Au niveau suivant se trouvent les tableaux, étant des collections organisées des types de données. Ensuite, il y a les enregistrements, étant des types de données de conglomérat accessibles sous un seul nom. Transcendant ces aspects physiques des données, le niveau final se concentre sur la séquence dans laquelle les données seront entreposées et récupérées. Essentiellement, les données physiques sont liées à des «machines de données» contrôlant la façon dont votre programme accède aux informations. Il y a quatre de ces machines de données :
- Une file d'attente (queue)
- Une pile
- Une liste chaînée (listes liées)
- Un arbre binaire.
Chaque méthode fournit une solution à une classe de problèmes : chacun est essentiellement un périphérique effectuant une opération d'entreposage et de récupération spécifique sur les informations et la demande données. Les méthodes partagent deux opérations : entreposer un élément et récupérer un élément, dans lequel l'élément est une unité d'information.
File d'attente (Queues)
Une file d'attente est une liste linéaire d'informations auxquelles on accède dans l'ordre premier entré, premier sorti (parfois appelé FIFO). Le premier élément placé dans la file d'attente est le premier élément récupéré, et ainsi de suite. Cette ordre est le seul moyen d'entreposer et de récupération; une file d'attente n'autorise pas l'accès aléatoire à un élément spécifique.
Les files d'attente sont courantes dans la vie de tous les jours. Par exemple, une file d'attente dans une banque ou dans un restaurant de restauration rapide est une file d'attente - sauf lorsque les clients se frayent un chemin vers l'avant. Pour visualiser le fonctionnement d'une file d'attente, considérez les deux routines Qstore et Qretrieve. Qstore place un élément à la fin de la file d'attente et Qretrieve supprime le premier élément de la file d'attente et renvoie sa valeur. La figure suivante montre l'effet d'une série de ces opérations.
| Action | Contenu de file d'attente |
|---|---|
| Qstore(A) | A |
| Qstore(B) | A B |
| Qstore(C) | A B C |
| Qretrieve retourne A | B C |
| Qstore(D) | B C D |
| Qretrieve retourne B | C D |
| Qretrieve retourne C | D |
Gardez à l'esprit qu'une fois récupéré, il est détruit et l'élément ne peut plus être accédé.
Les files d'attente sont utilisées dans de nombreux types de situations de programmation, telles que les simulations, la planification d'événements (comme dans un diagramme PERT ou Gant) et la mise en mémoire tampon d'entrée/sortie.
À titre d'exemple, considérons un simple programme de planification d'événements vous permettant de saisir un certain nombre d'événements. Au fur et à mesure que chaque événement est exécuté, il est retiré de l'organisation d'événements tels que les rendez-vous d'une journée. Pour simplifier les exemples, le programme utilise un tableau de chaînes de caractères pour contenir les événements. Il limite chaque description d'événement à 80 caractères et le nombre d'événements à 100. Tout d'abord, voici le programme de planification. Ils sont affichés ici avec les variables globales nécessaires et les définitions de types.
- Const
- MAX_EVENT=100;
-
- Type
- EvtType=String[80];
-
- Var
- Event:Array[1..MAX_EVENT] of EvtType;
- SPos, RPos:Integer;
-
- Procedure Qstore(Q:EvtType);Begin
- If Spos=MAX_EVENT Then WriteLn('Liste pleine')
- Else
- Begin
- Event[SPos]:=Q;
- SPos:=SPos+1;
- End;
- End;
-
- Function Qretrieve:EvtType;Begin
- If RPos=SPos Then Begin
- WriteLn('Pas d''evenements dans la file d''attente');
- Qretrieve:='';
- End
- Else
- Begin
- RPos:=RPos+1;
- Qretrieve:=Event[RPos-1];
- End;
- End;
Ces fonctions nécessitent trois variables globales: spos, contenant l'index du prochain emplacement d'entreposage libre : rpos, contenant l'index de l'élément suivant à récupérer; et event, étant le tableau de chaînes de caractères contenant les informations. Avant que le programme puisse appeler Qstore ou Qretrieve, les variables spos et rpos doivent être initialisées à zéro.
Dans ce programme, la procédure Qstore place de nouveaux événements à la fin de la liste et vérifie si la liste est pleine. La fonction Qretrieve supprime les événements de la file d'attente lorsqu'il y a des événements à exécuter. Lorsqu'un nouvel événement est planifié, spos est incrémenté, et lorsqu'un événement est terminé, rpos est incrémenté. Essentiellement, rpos poursuit spos dans la file d'attente. Le schéma suivant montre comment ce processus apparaît en mémoire pendant l'exécution du programme :

Si rpos est égal à spos, alors il n'y a plus d'événements dans le calendrier. Gardez à l'esprit que même si les informations entreposées dans la file d'attente ne sont pas réellement détruites par la fonction Qretrieve, elles ne peuvent plus jamais être accédées et sont en fait disparues.
Voici le programme complet pour le calendrier simple des événements. Vous souhaiterez peut-être améliorer ce programme pour votre propre usage :
- Program MiniScheduler;
-
- Const
- MAX_EVENT=100;
-
- Type
- EvtType=String[80];
-
- Var
- Event:Array[1..MAX_EVENT] of EvtType;
- spos,rpos,t:Integer;
- ch:Char;
- done:Boolean;
-
- Procedure Qstore(q:EvtType);Begin
- If spos=MAX_EVENT Then WriteLN('Liste pleine')
- Else
- Begin
- Event[Spos]:=q;
- Inc(spos);
- End;
- End;
-
- Function Qretrieve:EvtType;Begin
- If rpos=spos Then Begin
- WriteLn('Pas d''evenements dans la file d''attente');
- Qretrieve:='';
- End
- Else
- Begin
- Inc(rpos);
- Qretrieve:=event[rpos-1];
- End;
- End;
-
- Procedure Enter;
- Var
- s:String[80];
- Begin
- Repeat
- Write('Entrer l''evenement ',spos+1,':');
- Read(s);
- WriteLn;
- If Length(s)<>0 Then Qstore(s);
- Until Length(s)=0;
- End;
-
- Procedure Review;
- Var
- t:Integer;
- Begin
- For t:=rpos to spos-1 do WriteLn(t,':',event[t]);
- End;
-
- Procedure Perform;
- Var
- S:String[80];
- Begin
- S:=Qretrieve; { Demande le prochaine evenement }
- If Length(s)<>0 Then WriteLn(s);
- End;
-
- BEGIN { Planification }
- For t:=1 to MAX_EVENT do event[t]:=''; { Initie les evenements }
- spos:=0; rpos:=0; done:=False;
- Repeat
- Write('Entrer, Revoir, Traiter, Quitte :');
- Read(ch);
- WriteLn;
- Case UpCase(ch)of
- 'E':Enter;
- 'R':Review;
- 'T':Perform;
- 'Q':done:=True;
- End;
- Until done;
- END.
La file d'attente circulaire
Précédemment, vous avez peut-être pensé à une amélioration du programme MiniScheduler. Au lieu d'arrêter le programme lorsqu'il atteint la limite du tableau utilisé pour entreposer la file d'attente, vous pouvez avoir à la fois l'index d'entreposage spos et l'index de récupération rpos en boucle au début du tableau. Cette méthode permettrait de placer n'importe quel nombre d'éléments dans la file d'attente, à condition que les éléments soient également retirés. Cette mise en oeuvre d'une file d'attente est appelée une file d'attente circulaire car elle utilise son tableau d'entreposage comme s'il s'agissait d'un cercle au lieu d'une liste linéaire.
Pour créer une file d'attente circulaire dans le programme MiniScheduler, vous devez modifier les routines Qstore et Qretrieve, comme indiqué ici :
- Procedure Qstore(q:EvtType);Begin
- If spos+1=rpos Then WriteLN('Liste pleine')
- Else
- Begin
- Event[Spos]:=q;
- Inc(spos);
- If spos=MAX_EVENT Then spos:=1 { Revient dans la boucle }
- End;
- End;
-
- Function Qretrieve:EvtType;Begin
- If rpos=MAX_EVENT Then rpos:=1; { Revient dans la boucle }
- If rpos=spos Then Begin
- WriteLn('File d''attente vide');
- Qretrieve:='';
- End
- Else
- Begin
- Inc(rpos);
- Qretrieve:=event[rpos-1];
- End;
- End;
En substance, la file d'attente n'est pleine que lorsque l'index d'entreposage et l'index de récupération sont égaux; sinon, la file d'attente a encore de la place pour un autre événement. Cependant, cela signifie que lorsque le programme démarre, l'index de récupération rpos ne doit pas être défini sur 0 mais plutôt sur MAX_EVENT, afin que le premier appel à Qstore ne produise pas la liste de messages pleine. Notez qu'il doit toujours être séparé d'au moins un élément; sinon, il serait impossible de savoir si la file d'attente est pleine ou vide. Le schéma suivant montre le tableau utilisé pour la version circulaire du programme MiniScheduler.
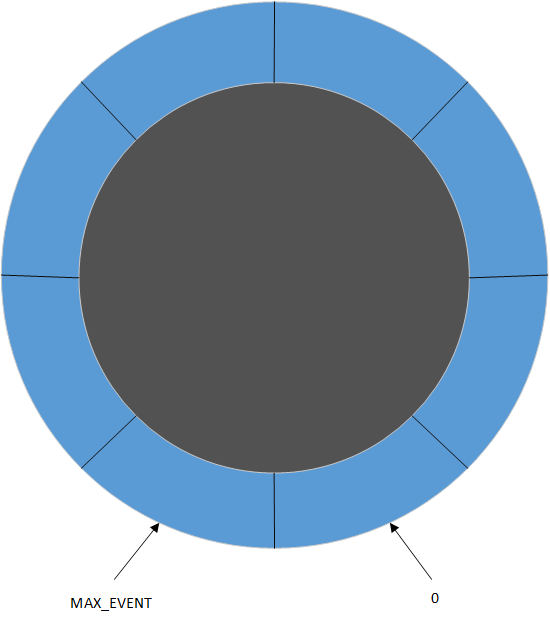
L'utilisation la plus courante d'une file d'attente circulaire peut être dans le système d'exploitation mettant en mémoire tampon les informations lues et écrites sur les fichiers du disque ou la console. Une autre utilisation courante est dans les programmes d'application en temps réel dans lesquels, par exemple, l'utilisateur peut continuer à entrer à partir du clavier pendant que le programme exécute ou justifie une ligne. Il y a une brève période pendant laquelle ce qui est tapé n'est pas affiché tant que l'autre processus sur lequel le programme travaille n'est pas terminé. Pour ce faire, le programme d'application doit continuer à vérifier l'entrée au clavier pendant l'exécution de l'autre processus. Si une clef a été tapée, elle est placée rapidement dans la file d'attente et le processus se poursuit. Une fois le processus terminé, les caractères sont extraits de la file d'attente et traités de manière normale.
Pour voir comment cela peut être fait avec une file d'attente circulaire, étudiez le programme simple suivant, contenant deux processus. Le premier processus compte jusqu'à 32 000. Le deuxième processus place les caractères dans une file d'attente circulaire au fur et à mesure de leur saisie, sans faire d'écho à l'écran jusqu'à ce qu'il trouve un point-virgule. Les caractères que vous tapez ne seront pas affichés, car le premier processus est prioritaire jusqu'à ce que vous tapiez un point-virgule ou jusqu'à ce que le décompte se termine. Ensuite, les caractères de la file d'attente sont récupérés et affichés.
- Program KeyBuffer;
-
- Uses Crt,DOS;
-
- Const
- MAX_EVENT=10;
- Type
- EvtType=Char;
-
- Var
- Event:Array[1..MAX_EVENT] of EvtType;
- spos,rpos,t:Integer;
- ch:Char;
- DosCall:Registers;
-
- Procedure Qstore(q:EvtType);Begin
- If spos+1=rpos Then WriteLn('Liste pleine')
- Else
- Begin
- Event[spos]:=q;
- Inc(spos);
- If spos=MAX_EVENT Then spos:=1; { Retour de boucle }
- End;
- End;
-
- Function Qretrieve:EvtType;Begin
- If rpos=MAX_EVENT Then rpos:=1; { Retour de boucle }
- If rpos=spos Then Begin
- WriteLn('File d''attente pleine');
- Qretrieve:=';';
- End
- Else
- Begin
- Inc(rpos);
- Qretrieve:=Event[rpos-1];
- End;
- End;
-
- BEGIN
- DosCall.AH:=7;
- DosCall.AL:=Byte(' ');
- t:=1;
- Repeat
- If KeyPressed Then Begin
- MsDos(DosCall); { Lecture sans écho }
- Qstore(Char(DosCall.AL));
- End;
- Inc(t);
- Until (t=32000)or(Char(DosCall.AL)=';');
- Repeat
- ch:=Qretrieve;
- If ch<>''Then Write(ch);
- Until ch=';';
- END.
La routine KeyPressed utilise un appel de fonction au système d'exploitation, renvoyant TRUE si une touche a été enfoncée. L'appel MsDos lit une touche du clavier sans la renvoyer à l'écran (voir Interruption 21h, fonction 07h). Les appels fonctionnent uniquement pour le IBM PC.
Piles
Une pile est l'opposé d'une file d'attente, car elle utilise l'accès dernier entré, premier sorti (parfois appelé LIFO). Imaginez une pile d'assiettes : la plaque inférieure de la pile est la dernière à être utilisée et la plaque supérieure (la dernière plaque de la pile) est la première à être utilisée. Les piles sont beaucoup utilisées dans les logiciels système, y compris les compilateurs et les interpréteurs. Pour des raisons historiques, les deux opérations de pile principales - entreposer et récupérer - sont généralement appelées respectivement empiler (push) et dépiler (pop). Par conséquent, pour implémenter une pile, vous avez besoin de deux fonctions : Push, plaçant une valeur en haut de la pile ; et Pop, récupérant la valeur supérieure de la pile. Vous avez également besoin d'une région de mémoire à utiliser comme pile : vous pouvez utiliser un tableau, ou vous pouvez allouer une région de mémoire en utilisant les fonctions d'allocation de mémoire dynamique de Turbo Pascal. Comme la file d'attente, la fonction de récupération retire une valeur de la liste et si la valeur n'est pas entreposée ailleurs et là détruire. Voici les formes générales de Push et Pop utilisant un tableau d'entiers :
- Const
- MAX=100;
-
- Var
- Stack:Array[1..100] of Integer;
- TOS:Integer; { Pointe sur le haut de la pile }
-
- Procedure Push(i:Integer);Begin
- If TOS>=MAX Then WriteLn('Pile pleine')
- Else
- Begin
- Stack[TOS]:=1;
- TOS:=TOS+1;
- End;
- End;
-
- Function Pop:Integer;Begin
- TOS:=TOS-1;
- If TOS<1 Then Begin
- WriteLn('Débordement de pile');
- TOS:=TOS+1;
- Pop:=0;
- End
- Else
- Pop:=Stack[TOS];
- End;
La variable TOS est l'index du prochain emplacement de pile ouvert. Lors de la mise en ouvre de ces fonctions, n'oubliez jamais d'éviter les débordements et les débordements. Dans ces routines, si TOS vaut 0, la pile est vide : si TOS est supérieur ou égal au dernier emplacement d'entreposage, la pile est pleine. Le tableau suivant montrent comment fonctionne une pile :
| Action | Contenus de la pile |
|---|---|
| Push(A) | A |
| Push(B) | B A |
| Push(C) | C B A |
| Pop demande C | B A |
| Push(F) | F B A |
| Pop demande F | B A |
| Pop demande B | A |
| Pop demande A | Vide |
Un excellent exemple d'utilisation d'une pile est une calculatrice à quatre fonctions. La plupart des calculatrices acceptent aujourd'hui une forme d'expression standard appelée notation infixe, prenant la forme générale opérande-opérateur-opérande. Par exemple, pour ajouter 100 à 200, vous devez saisir 100, appuyer sur +, saisir 200 et appuyer sur =. Cependant, certaines calculatrices utilisent une évaluation d'expression appelée notation postfixe, dont les deux opérandes sont entrés avant l'entrée de l'opérateur. Par exemple, pour ajouter 100 à 200 en utilisant le suffixe, vous devez d'abord saisir 100, puis 200, puis appuyer sur +. Au fur et à mesure que les opérandes sont entrés, ils sont placés sur une pile ; lorsqu'un opérateur est entré, deux opérandes sont supprimés de la pile et le résultat est repoussé sur la pile. L'avantage de la forme suffixe est que des expressions très complexes peuvent être évaluées facilement par la calculatrice sans trop de code. Le programme complet de la calculatrice est affiché ici&bbsp;:
- Program Calculatrice4Fonctions;
- Const
- MAX=100;
-
- Var
- Stack:Array[1..100]of Integer;
- TOS:Integer; { Pointe en haut de la pile }
- a,b:Integer;
- S:String[80];
-
- Procedure Push(i:Integer);Begin
- If TOS>=MAX Then WriteLn('Pile pleine')
- Else
- Begin
- Stack[TOS]:=I;
- Inc(TOS);
- End;
- End;
-
- Function Pop:Integer;Begin
- Dec(TOS);
- If TOS<1Then Begin
- WriteLn('Débordement de pile');
- Inc(TOS);
- Pop:=0;
- End
- Else
- Pop:=Stack[TOS];
- End;
-
- BEGIN
- TOS:=1;
- WriteLn('Calculatrice à 4 fonct ions');
- Repeat
- Write(': ');
- Read(s);
- WriteLn;
- Val(s,a,b);
- If(b=0)and((Length(s)>1)or(s[1]<>'-'))Then Push(a)
- Else
- Case s[1]of
- '+':Begin
- a:=Pop; b:=Pop;
- WriteLn(a+b);
- Push(a+b);
- End;
- '-':Begin
- a:=Pop; b:=Pop;
- WriteLn(a-b);
- Push(a-b);
- End;
- '*':Begin
- a:=Pop; b:=Pop;
- WriteLn(a*b);
- Push(a*b);
- End;
- '/':Begin
- a:=Pop; b:=Pop;
- If a=0 Then WriteLn('Division par 0')
- Else
- Begin
- WriteLn(b div a);
- Push(b div a);
- End;
- End;
- End;
- Until 'Q'=UpCase(S[1]);
- END.
Bien que cette version ne soit capable que de l'arithmétique d'entiers, il serait simple de la basculer en opération à virgule flottante complète en changeant le type de données de la pile et en convertissant l'opérateur div en opérateur à virgule flottante (/). Voir également Langage de programmation - Structure de données - Évaluation d'expression («Infix to Postfix»)
Listes chaînées (listes liées)
Les files d'attente (queue) et les piles partagent deux traits communs. Premièrement, les deux ont des règles strictes pour référencer les données y étant entreposées. Deuxièmement, les opérations de récupération sont par nature consommatrices ; c'est-à-dire que l'accès à un élément dans une pile ou une file d'attente nécessite son retrait et, à moins qu'il ne soit entreposé ailleurs, sa destruction. Les piles et les files d'attente nécessitent également, au moins en théorie, une région de mémoire contiguë pour fonctionner.
Contrairement à une pile ou à une file d'attente, une liste chaînée peut accéder à son entreposage de manière aléatoire, car chaque élément d'information comporte un lien vers l'élément de données suivant de la chaîne. Une liste chaînée nécessite une structure de données complexe, alors qu'une pile ou une file d'attente peut opérer sur des éléments de données simples et complexes. Une opération de récupération de liste chaînée ne supprime et ne détruit pas un élément de la liste; une opération de suppression spécifique doit être ajoutée pour cela.
Les listes chaînées sont utilisées à deux fins. Le premier objectif est de créer des tableaux de taille inconnue en mémoire. Si vous connaissez à l'avance la quantité d'entreposage, vous pouvez utiliser un simple tableau; mais si vous ne connaissez pas la taille réelle d'une liste, vous devez utiliser une liste chaînée. Le deuxième objectif est l'entreposage sur disque des bases de données. La liste liée vous permet d'insérer et de supprimer des éléments rapidement et facilement sans réorganiser l'intégralité du fichier disque. Pour ces raisons, les listes sont largement utilisées dans les logiciels de gestion de bases de données.
Les listes chaînées peuvent être soit simplement liées, soit doublement liées. Une seule liste chaînée contient un lien vers l'élément de données suivant. Une liste doublement liée (aussi appelé liste symétrique) contient des liens vers l'élément suivant et l'élément précédent de la liste. Le type que vous utilisez dépend de votre application.
Listes à liens unique (Liste à chaînage simple)
Une liste à liaison unique (aussi nommé liste à chaînage simple) nécessite que chaque élément d'information contienne un lien vers l'élément suivant de la liste. Chaque élément de données consiste généralement en un enregistrement contenant à la fois des champs d'information et un pointeur de lien. Le concept d'une liste à chaînage simple ressemble à ceci :

Il existe deux façons de créer une seule liste chaînée. Le premier ajoute simplement à chacun un nouvel élément au début ou à la fin de la liste. L'autre ajoute des éléments à des emplacements spécifiques de la liste (par exemple, par ordre de tri croissant).
La manière dont vous construisez cette liste détermine la manière dont la fonction d'entreposage sera codée, comme illustré dans le cas simple de la création d'une liste chaînée en ajoutant des éléments à la fin. Vous devez définir un enregistrement pour contenir les informations et les liens. Étant donné que les listes de diffusion sont courantes, cet exemple en utilise une. Le type d'enregistrement pour chaque élément de la liste de diffusion est défini ici.
- Type
- AddrPointer=^Address;
- Address=Record
- _Name:String[30];
- Street:String[40];
- City:String[20];
- State:String[2];
- Zip:String[9];
- Next:AddrPointer;
- End;
-
- DataItem=Address;
- DataArray=Array[1..100] of AddrPointer; { Conserver les pointeurs vers les enregistrements d'adresses }
-
- Var
- Start,Last:AddrPointer;
La fonction SL_Store construit une liste chaînée simple en plaçant chaque nouvel élément à la fin. Un pointeur vers un enregistrement de type address doit être passé à SL_Store, comme illustré ici :
Bien que vous puissiez trier la liste créée avec SL_Store en tant qu'opération distincte, il est plus facile de trier lors de la construction de la liste en insérant chaque nouvel élément dans l'ordre approprié de la chaîne. De plus, si la liste est déjà triée, il est avantageux de la maintenir triée en insérant de nouveaux éléments à leur emplacement approprié. Pour ce faire, la liste est parcourue séquentiellement jusqu'à ce que l'emplacement approprié soit trouvé ; la nouvelle adresse est insérée à ce point et les liens sont réorganisés si nécessaire.
Trois situations possibles peuvent se produire lors de l'insertion d'un élément dans une liste à liens simples. Tout d'abord, l'élément peut devenir le nouveau premier élément ; deuxièmement, il peut être inséré entre deux autres éléments ; ou troisièmement, il peut devenir le dernier élément. L'image suivante montre comment les liens sont modifiés pour chaque cas :
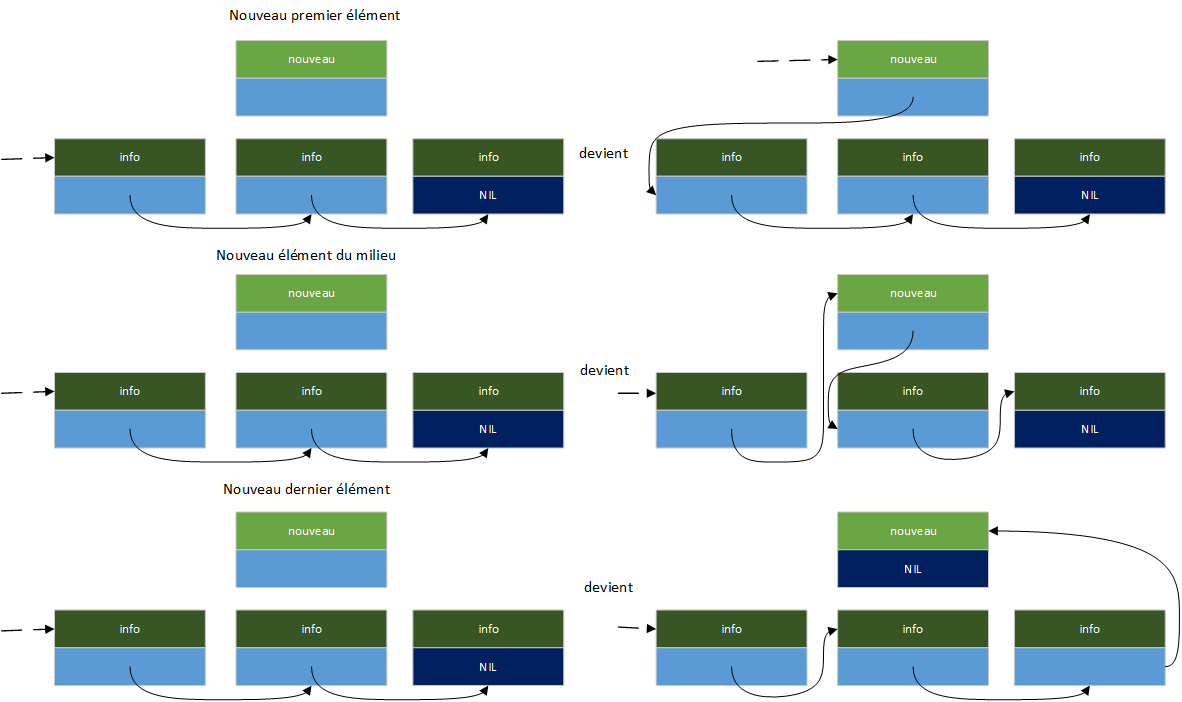
Si vous modifiez le premier élément de la liste, vous devez mettre à jour le point d'entrée de la liste ailleurs dans votre programme. Pour éviter cela, vous utilisez une sentinelle comme premier élément. Une sentinelle est une valeur spéciale étant toujours la première dans la liste, cette méthode vous permet d'empêcher le changement du point d'entrée de la liste. Cependant, cette méthode a l'inconvénient d'utiliser un emplacement d'entreposage supplémentaire pour contenir la sentinelle, elle n'est donc pas utilisée ici.
La fonction, SLS_Store, illustrée ici, insère des adresses dans le premier élément de diffusion de la liste et exige également que les pointeurs vers le début et la fin de la liste lui soient transmis :
- Function SLS_Store(Info,Start:AddrPointer;Var Last:AddrPointer):AddrPointer; { Entrepose les entrées dans l'ordre enregistré }
- Var
- Old,Top:^Address;
- Done:Boolean;
- Begin
- Top:=Start;
- Old:=NIL;
- Done:=False;
- If Start=NIL Then Begin { Premier élément de la liste }
- Info^.Next:=NIL;
- Last:=Info;
- SLS_Store:=Info;
- End
- Else
- Begin
- While(Start<>NIL)and(Not Done)do Begin
- If Start^.Name<Info^.Name Then Begin
- Old:=Start;
- Start:=Start^.Next;
- End
- Else
- Begin { Va au milieu }
- If Old<>NIL Then Begin
- Old^.Next:=Info;
- Info.Next:=Start;
- SLS_Store:=Top; { Conserver le même point de départ }
- Done:=True;
- End;
- End;
- End;
- If Not Done THen Begin
- Last^.Next:=Info;
- Info^.Next:=NIL;
- Last:=Info;
- SLS_Store:=Top;
- End;
- End;
- End;
Dans une liste liée, il est rare de trouver une fonction spécifique dédiée au processus de récupération, renvoyant élément après élément dans l'ordre de la liste. Ce code est une fonction de recherche, de suppression ou d'affichage. Par exemple, cette routine affiche tous les noms d'une liste de diffusion :
Ici, start est un pointeur sur le premier enregistrement de la liste. Récupérer des éléments de la liste est aussi simple que de suivre une chaîne de caractères. Vous pouvez écrire une routine de recherche basée sur le champ de nom comme ceci :
Parce que Search renvoie un pointeur vers l'élément de liste correspondant au nom de la recherche. Search doit être déclaré comme renvoyant un pointeur d'enregistrement de type address. S'il n'y a pas de correspondance, un pointeur NIL est renvoyé.
Le processus de suppression d'un élément d'une seule liste liée est simple. Comme dans l'insertion, il y a trois cas : supprimer le premier élément, supprimer un élément du milieu et supprimer le dernier élément. L'image suivante montre chaque cas :
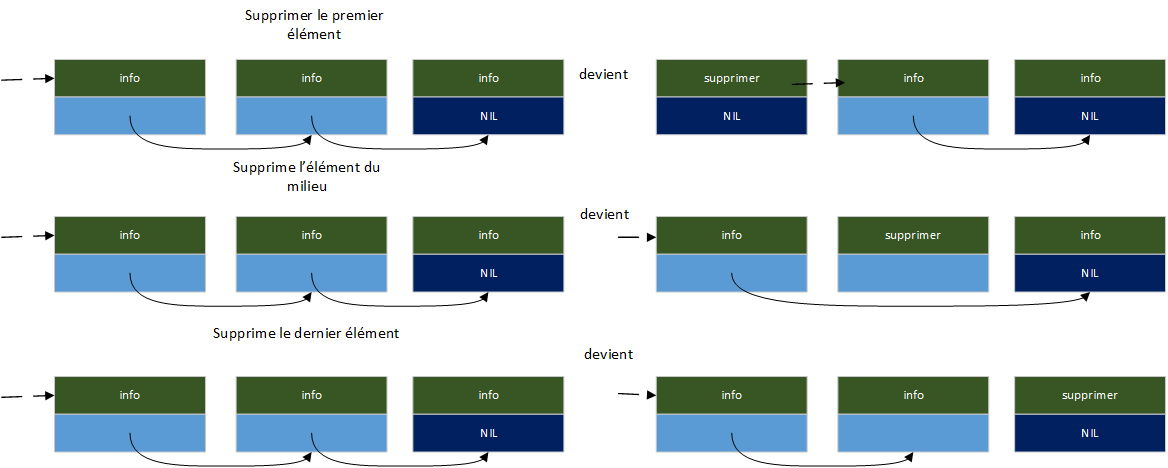
Cette fonction supprime un élément donné d'une liste d'enregistrements de type address :
SL_Delete doit recevoir des pointeurs vers l'élément supprimé, vers l'élément le précédant dans la chaîne et vers le début de la liste. Si le premier élément doit être supprimé, le pointeur précédent doit être NIL. La fonction doit renvoyer un pointeur vers le début de la liste en raison du cas où le premier élément est supprimé - le programme doit savoir où se trouve le nouveau premier élément.
Les listes chaînées ont un inconvénient majeur empêchant leur utilisation intensive : la liste ne peut pas être suivie dans l'ordre inverse. Pour cette raison, des listes doublement liées sont généralement utilisées.
Listes à liens double (liste à chaînage double)
Les listes doublement liées sont constituées de données liées à la fois à l'élément suivant et à l'élément précédent. L'image suivante montre comment les liens sont organisés :

Une liste ayant deux liens au lieu d'un a deux avantages majeurs. Premièrement, la liste peut être lue dans les deux sens. Cela simplifie non seulement le tri de la liste mais également, dans le cas d'une base de données, permet à un utilisateur de parcourir la liste dans les deux sens. Deuxièmement, comme un lien vers l'avant ou un lien vers l'arrière peut lire la liste entière, un lien devient invalide, la liste peut être reconstruite en utilisant l'autre lien. Cela n'a de sens qu'en cas de panne de l'équipement.
Trois opérations principales peuvent être effectuées sur une liste doublement liée : insérer un nouveau premier élément, insérer un nouvel élément intermédiaire et insérer un nouveau dernier élément.