
Les modèles de mémoire
Que sont les modèles de mémoire et pourquoi devez-vous vous en préoccuper ? Pour répondre à cette question, nous devons examiner le système informatique sur lequel vous travaillez. Son unité centrale (CPU) est un microprocesseur appartenant à la famille Intel iAPx86; probablement un 8088, mais peut-être un 8086, un 80186 ou un 80286. Pour l'instant, nous allons simplement l'appeler 8086.
Les registres 8086
La figure suivante montre les registres trouvés dans le processeur 8086, avec une brève description de leur utilisation. Il y a deux autres registres - IP (pointeur d'instruction) et le registre de drapeau - mais Turbo C ne peut pas y accéder, donc ils ne sont pas affichés ici :
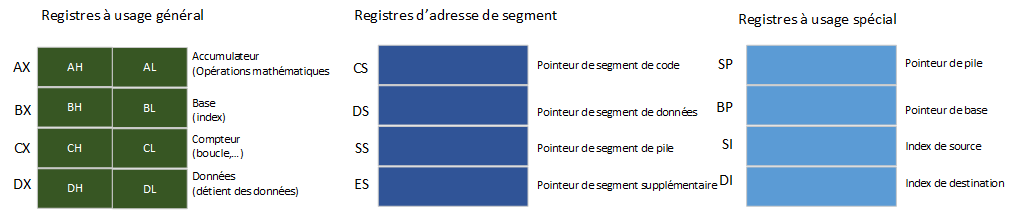
Registres à usage général
Les registres à usage général sont ceux étant le plus souvent utilisés pour conserver et manipuler des données. Chacun a des fonctions spéciales que lui seul peut faire. Par exemple :
- De nombreuses opérations mathématiques ne peuvent être effectuées qu'avec le registre AX.
- Le registre BX peut être utilisé pour contenir la partie déplacement (offset) d'un pointeur long.
- Le registre CX est utilisé par certaines des instructions de boucle (LOOP,...) du 8086.
- Le registre DX est utilisé par certaines instructions pour conserver des données.
Mais il existe de nombreuses opérations que tous ces registres peuvent effectuer; dans de nombreux cas, vous pouvez les échanger librement.
Registres de segments
Les registres de segments contiennent l'adresse de départ de chacun des quatre segments. La valeur de 16 bits dans un registre de segment est déplacée vers la gauche de 4 bits (multipliée par 16) pour obtenir la véritable adresse de 20 bits de ce segment.
Registres à usage spécial
Le 8086 possède également des registres à usage spécial.
- Les registres SI et DI peuvent faire beaucoup des choses que les registres à usage général peuvent faire, en plus ils sont utilisés comme registres d'index. Ils sont également utilisés par Turbo C pour les variables de registre.
- Le registre SP pointe vers le haut de pile actuel et est un déplacement dans le segment de pile.
- Le registre BP est un pointeur de pile secondaire, généralement utilisé pour indexer dans la pile afin de récupérer des paramètres.
Le registre de pointeur de base (BP) est utilisé dans les fonctions C comme adresse de base pour les paramètres et les variables automatiques. Les paramètres ont des déplacements positifs par rapport à BP, variant en fonction du modèle de mémoire et du nombre de registres enregistrés lors de l'entrée de la fonction. Le registre BP pointe toujours vers la valeur du registre BP précédente enregistrée. Les fonctions n'ayant pas de paramètres et ne déclarent aucun paramètre n'utiliseront ni ne sauveront du tout BP.
Les variables automatiques reçoivent des déplacement négatifs par rapport à BP, les premières variables automatiques ayant le décalage négatif de plus grande amplitude.
Segmentation de la mémoire
Le microprocesseur Intel 8086 a une architecture de mémoire segmentée. Il a un espace d'adressage total de 1 mégaoctet, mais il est conçu pour adresser directement seulement 64 Ko de mémoire à la fois. Un bloc de mémoire de 64 Ko est appelé segment; d'où l'expression architecture de mémoire segmentée. Maintenant, combien de segments différents y a-t-il, où sont-ils situés et comment le 8086 sait-il où ils se trouvent ?
- Le 8086 garde la trace de quatre segments différents : code, données, pile et supplémentaire (extra). Le segment de code est l'endroit où se trouvent les instructions de la machine; le segment de données, où se trouvent les informations; la pile est, bien entendu, la pile; et le segment supplémentaire est utilisé (généralement) pour les données supplémentaires.
- Le 8086 a quatre registres de segment de 16 bits (un pour chaque segment) nommés CS, DS, SS et ES; ceux-ci pointent respectivement vers le code, les données, la pile et les segments supplémentaires (extra).
- Un segment peut être situé n'importe où dans la mémoire - au moins, presque n'importe où. Un segment doit commencer sur une adresse divisible par 16 (en base 10).
Calcul d'adresse
Comment le 8086 utilise-t-il ces registres de segments pour calculer une adresse ? Une adresse complète sur le 8086 est composée de deux valeurs de 16 bits : l'adresse de segment et le déplacement (offset). Supposons que l'adresse du segment de données - la valeur dans le registre DS - soit 2F84 (base 16), et que vous souhaitiez calculer l'adresse réelle de certaines données ayant un déplacement de 0532 (base 16) à partir du début du segment de données; comment cela se fait-il ? Le calcul de l'adresse se fait comme suit : décalez la valeur du registre de segment de quatre (4) bits vers la gauche (équivalent à un chiffre hexadécimal), puis ajoutez le déplacement. La valeur 20 bits résultante est l'adresse réelle des données, comme illustré ici :
|
Registre DS (décalage) : 0010 1111 1000 0100 0000 = 2F840 Déplacement : 0000 0101 0011 0010 = 00532 Adresse : 0010 1111 1101 0111 0010 = 2F072 |
L'adresse de début d'un segment est toujours un nombre de 20 bits, mais un registre de segment ne contient que 16 bits, de sorte que les quatre bits inférieurs sont toujours supposés être tous des zéros. Cette situation signifie - comme nous l'avons dit - que les segments ne peuvent démarrer que tous les 16 octets dans la mémoire, à une adresse où les 4 derniers bits (ou le dernier chiffre hexadécimal) sont zéro. Ainsi, si le registre DS contient une valeur de 2F84, le segment de données commence en fait à l'adresse 2F840. À propos, un morceau de 16 octets est appelé paragraphe, vous pouvez donc dire qu'un segment commence toujours sur une limite de paragraphe. La notation standard d'une adresse prend la forme segment:déplacement (segment:offset); par exemple, l'adresse précédente serait écrite sous la forme 2F84:0532.
Notez que puisque les décalages peuvent se chevaucher, une paire de segment:déplacement n'est pas unique; les adresses suivantes font toutes référence au même emplacement mémoire :
|
0000:0123 0002:0103 0008:00A3 0010:0023 0012:0003 |
Une dernière remarque : les segments peuvent (mais ne sont pas obligés) se chevaucher. Par exemple, les quatre segments peuvent commencer à la même adresse, ce qui signifie que l'ensemble de votre programme ne prendrait pas plus de 64 Ko, mais c'est tout l'espace dont vous disposeriez pour votre code, vos données et votre pile.
Pointeurs Near, Far et Huge
Qu'est-ce que les pointeurs ont à voir avec les modèles de mémoire et Turbo C ? Beaucoup. Le type de modèle de mémoire que vous choisissez déterminera le type par défaut de pointeurs utilisés pour le code et les données. Cependant, vous pouvez déclarer explicitement un pointeur (ou une fonction) comme étant d'un type spécifique, quel que soit le modèle utilisé. Les pointeurs sont disponibles en trois saveurs : court, soit Near (16 bits), long, soit Far (32 bits) et énorme, soit Huge (également 32 bits); regardons chacun.
Pointeurs court (Near)
Un pointeur de 16 bits (court) s'appuie sur l'un des registres de segment pour terminer le calcul de son adresse; par exemple, un pointeur vers une fonction ajouterait sa valeur de 16 bits au contenu décalé à gauche du registre de segment de code (CS). D'une manière similaire, un pointeur de données proches contient un déplacement par rapport au registre de segment de données (DS). Les pointeurs courts sont faciles à manipuler, car toute arithmétique (telle que l'addition) peut être effectuée sans se soucier du segment.
Pointeurs long (FAR)
Un pointeur long (32 bits) contient non seulement le déplacement dans le segment, mais également (comme une autre valeur 16 bits) l'adresse du segment, étant ensuite décalée vers la gauche et ajoutée au déplacement. En utilisant des pointeurs long, vous pouvez avoir plusieurs segments de code; cela, à son tour, vous permet d'avoir des programmes de plus de 64 Ko. De même, avec des pointeurs de données éloignés, vous pouvez adresser plus de 64 Ko de données. Lorsque vous utilisez des pointeurs éloignés pour les données, vous devez être conscient de certains problèmes potentiels lors de la manipulation des pointeurs. Vous pouvez avoir de nombreux segments différents : les paires de déplacement renvoient à la même adresse. Par exemple, les pointeurs long 0000:0120, 0010:0020 et 0012:0000 résolvent tous vers la même adresse 20 bits. Cependant, si vous aviez trois variables de pointeur éloigné différentes - a, b et c contenant respectivement ces trois valeurs, toutes les expressions suivantes seraient fausses :
if (a == b)
if (b == c) ...
if (a == c) ...
Un problème connexe se produit lorsque vous souhaitez comparer des pointeurs éloignés à l'aide des opérateurs >, >=, < et <=. Dans ces cas, seul le déplacement (en tant que non signé) est utilisé à des fins de comparaison; étant donné que a, b et c ont toujours les valeurs précédemment répertoriées, les expressions suivantes seraient toutes vraies :
if (a > b) ...
if (b > c) ...
if (a > c) ...
Les opérateurs égal (==) et non égal (!=) Utilisent la valeur 32 bits comme un long non signé (pas comme l'adresse mémoire complète). Les opérateurs de comparaison <=, >=, < et > n'utilisent que le déplacement. Les opérateurs == et != ont besoin des 32 bits, de sorte que l'ordinateur peut comparer au pointeur NULL (0000:0000). Si vous avez utilisé uniquement la valeur de déplacement pour la vérification d'égalité, tout pointeur avec un décalage de 0000 serait égal au pointeur NULL, ce qui n'est pas ce que vous voulez. Une dernière chose à savoir: si vous ajoutez des valeurs à un pointeur éloigné, seul le déplacement est modifié. Si vous ajoutez suffisamment pour que le déplacement dépasse FFFF (sa valeur maximale possible), le pointeur revient simplement au début du segment. Par exemple, si vous ajoutez 1 à 5031: FFFF, le résultat serait 5031:0000 (et non 6031:0000). De même, si vous soustrayez 1 de 5031:0000, vous obtiendrez 5031:FFFF (et non 5030:000F). Si vous souhaitez effectuer des comparaisons de pointeurs, il est plus sûr d'utiliser des pointeurs courts - utilisant tous la même adresse de segment - ou des pointeurs énormes.
Pointeurs énormes (Huge)
Les pointeurs énormes (Huge) ont également une longueur de 32 bits et, comme les pointeurs éloignés, contiennent à la fois une adresse de segment et un déplacement. Contrairement aux pointeurs long (FAR), cependant, ils sont normalisés, pour éviter les problèmes décrits dans «Pointeurs long». Qu'est-ce qu'un pointeur normalisé ? C'est un pointeur 32 bits ayant autant de valeur que possible dans l'adresse de segment. Puisqu'un segment peut commencer tous les 16 octets (10 en base 16), cela signifie que le déplacement n'aura qu'une valeur de 0 à 15 (0 à F en base 16). Comment normalisez-vous un pointeur? Simple : convertissez-le en son adresse 20 bits, puis utilisez les 4 bits de droite pour votre déplacement (offset) et les 16 bits de gauche pour votre adresse de segment. Par exemple, étant donné le pointeur 2F84:0532, nous le convertissons en l'adresse absolue 2FD72, que nous normalisons ensuite en 2FD7:0002. Voici quelques autres pointeurs avec leurs équivalents normalisés :
|
0000:0123 0012:0003 0040:0056 0045:0006 5000:9407 594D:0007 7418:D03F 811B:000F |
Vous savez maintenant que des pointeurs énormes (Huge) sont toujours normalisés. Pourquoi est-ce important ? Parce que cela signifie que pour une adresse mémoire donnée, il n'y a qu'un seul énorme segment d'adresse possible, soit la paire segment:déplacement. Et cela signifie que les opérateurs == et != renvoient des réponses correctes pour tout pointeur énorme. En plus de cela, les opérateurs >, >=, < et <= sont tous utilisés sur la valeur 32 bits complète pour les pointeurs énormes. La normalisation garantit que les résultats y seront également corrects. Enfin, en raison de la normalisation, le déplacement dans un pointeur énorme s'enroule automatiquement toutes les 16 valeurs, mais contrairement aux pointeurs long (FAR), le segment est également ajusté. Par exemple, si vous deviez incrémenter 811B:000F, le résultat serait 811C:0000; de même, si vous décrémentez 811C:0000, vous obtenez 811B:000F. C'est cet aspect des pointeurs énormes (Huge) vous permettant de manipuler des structures de données d'une taille supérieure à 64 Ko. Il y a un prix pour l'utilisation de pointeurs énormes (Huge): une plus grande consommation des ressources du micro-ordinateur. L'arithmétique des pointeurs énormes (Huge) est effectuée avec des appels à des sous-programmes spéciaux. Pour cette raison, l'arithmétique des pointeurs énormes est nettement plus lente que celle des pointeurs long (FAR) ou court (NEAR).
Les six modèles de mémoire du Turbo C
Éviter les consommations de ressources inutiles - sauf lorsque vous le souhaitez - est exactement ce que Turbo C vous permet de faire. Vous avez le choix entre six modèles de mémoire différents : tiny, small, medium, compact, large et huge. Celui que vous choisissez dépend de vos besoins. Voici un bref résumé de chacun :
| Modèle | Description |
|---|---|
| Tiny | Comme vous pouvez le deviner, c'est le plus petit des modèles de mémoire. Les quatre registres de segments (CS, DS, SS, ES) sont définis sur la même adresse, vous disposez donc d'un total de 64 Ko pour l'ensemble de votre code, données et tableaux. Les pointeurs courts (NEAR) sont toujours utilisés. Utilisez-le lorsque la mémoire est une prime absolue. Les modèles de programmation Tiny peuvent être convertis au format .COM. |
| Small | Le code et les segments de données sont différents et ne se chevauchent pas, vous avez donc 64 Ko de code et 64 Ko de données statiques. La pile et les segments supplémentaires commencent à la même adresse que le segment de données. Les pointeurs courts sont toujours utilisés. C'est une bonne taille pour les applications moyennes. |
| Medium | Les pointeurs long (FAR) sont utilisés pour le code, mais pas pour les données. Par conséquent, les données statiques sont limitées à 64 Ko, mais le code peut occuper jusqu'à 1 Mo. Idéal pour les grands programmes ne conservant pas beaucoup de données en mémoire. |
| Compact | L'inverse de Medium: les pointeurs long sont utilisés pour les données, mais pas pour le code. Le code est alors limité à 64 Ko, tandis que les données ont une plage de 1 Mo. Idéal si votre code est petit mais que vous devez traiter beaucoup de données. |
| Large | Les pointeurs éloignés sont utilisés à la fois pour le code et les données, donnant à la fois un intervalle de 1 Mo. Nécessaire uniquement pour les applications très volumineuses. |
| Huge | Les pointeurs éloignés sont utilisés à la fois pour le code et les données. Le Turbo C limite normalement la taille de toutes les données statiques à 64 Ko; le modèle Huge de mémoire met de côté cette limite, permettant aux données statiques d'occuper plus de 64 Ko. |
Le schéma suivant montrent comment la mémoire du 8086 est répartie pour les six modèles de mémoire du Turbo C :
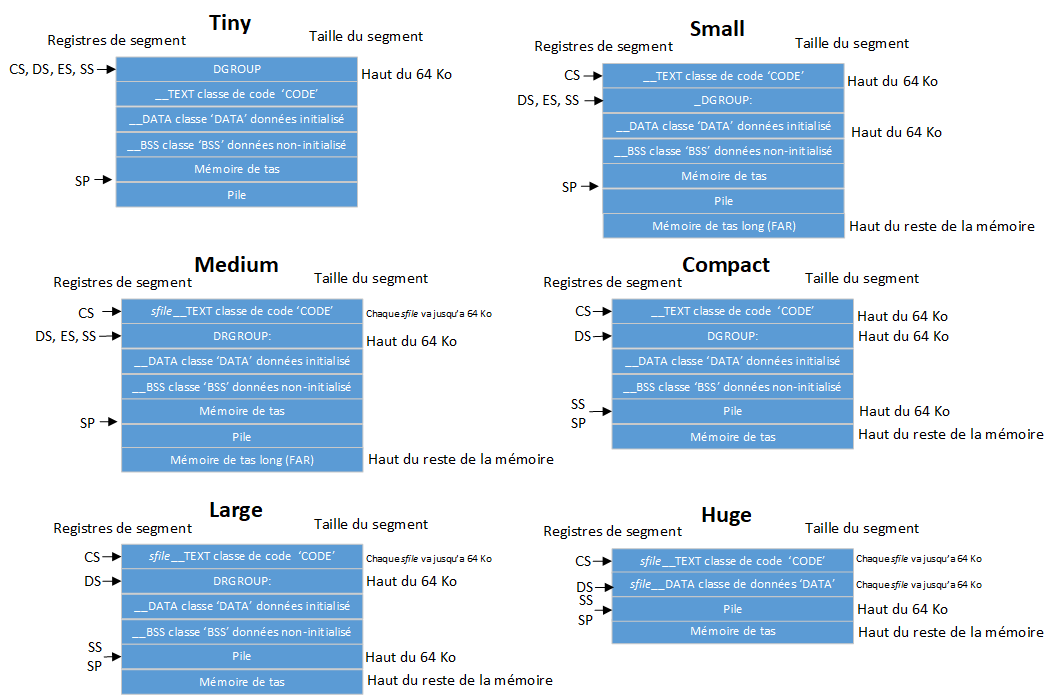
Les modèles sont souvent regroupés selon que leur code ou leurs modèles de données sont petits (64 Ko) ou grands (1 Mo); ces groupes correspondent aux lignes et colonnes du schéma suivant. Ainsi, par exemple, les modèles Tiny, Small et Compact sont appelés petits modèles de code car, par défaut, les pointeurs de code sont court (Near); de même, Compact, Large, et Huge sont appelés modèles de données volumineux car, par défaut, les pointeurs de données sont long (FAR). Notez que cela est également vrai pour le modèle Huge - les pointeurs de données par défaut sont long (FAR), pas Huge. Si vous voulez des pointeurs énormes (Huge) de données, vous devez les déclarer explicitement comme énormes (Huge).
| Taille des données | Taille du code | |
|---|---|---|
| 64 Ko | 1 Mo | |
| 64 Ko | Tiny (chevauchement des données et du code, taille total = 64 Ko) | |
| Small (pas de chevauchement; taille total = 128 Ko) | Medium (données petite et gros code) | |
| 1 Mo | Compact (grosses données et petit code) | Large (grosses données et gros code) |
| Huge (même chose que Large mais données statique > 64 Ko) | ||
Lorsque vous compilez un module (un fichier source donné contenant un certain nombre de routines), le code résultant pour ce module ne peut pas être supérieur à 64 Ko, car il doit tous tenir dans un segment de code. Cette situation est vrai même si vous utilisez un modèle de code volumineux (Medium, Large, Huge). Si votre module est trop volumineux pour tenir dans un segment de code (64 Ko), vous devez le diviser en différents fichiers de code source, compiler chaque fichier séparément, puis les lier ensemble. De même, même si le modèle Huge permet aux données statiques de totaliser plus de 64 Ko, dans chaque module, elles doivent toujours être inférieures à 64 Ko.
Programmation de modèles mixtes : modificateurs d'adressage
Le Turbo C introduit sept nouveaux mots clefs introuvables dans le C standard (de Kernighan et Ritchie ou ANSI) : near, far, huge, _cs, _ds, _es, _ss. Ceux-ci peuvent être utilisés comme modificateurs vers des pointeurs (et dans certains cas, vers des fonctions), avec certaines limitations et avertissements. Dans Turbo C, vous pouvez modifier les fonctions et les pointeurs avec les mots clefs near, far ou huge. Nous avons expliqué les pointeurs de données courts (Near), longs (FAR) et énormes (Huge) plus tôt dans cette page. Les fonctions near sont appelées avec des appels courts et se terminent avec des retours courts. De même, les fonctions far sont appelées far et effectuent des retours long (FAR). les fonctions huge sont comme les fonctions longues, sauf que les fonctions huge peuvent définir DS sur une nouvelle valeur, alors que les fonctions éloignées ne le peuvent pas. Il existe également quatre pointeurs de données courts spéciaux : _cs, _ds, _ss et _es. Ce sont des pointeurs 16 bits étant spécifiquement associés au registre de segment correspondant. Par exemple, si vous déclarez qu'un pointeur est :
char _ss *p;
alors p contiendrait un déplacement de 16 bits dans le segment de pile. Les fonctions et les pointeurs d'un programme donné seront par défaut courts ou longs, selon le modèle de mémoire que vous sélectionnez. Si la fonction ou le pointeur est court, alors il est automatiquement associé au registre CS ou DS. Le tableau suivant montre comment cela fonctionne. Notez que la taille du pointeur correspond au fait qu'il fonctionne dans une limite de mémoire de 64 Ko (près, dans un segment) ou à l'intérieur de l'espace mémoire général de 1 Mo (long, a sa propre adresse de segment) :
| Modèle de mémoire | Pointeurs de fonction | Pointeurs de données |
|---|---|---|
| Tiny | near, _cs | near, _ds |
| Small | near, _cs | near, _ds |
| Medium | far | near, _ds |
| Compact | near, _cs | far |
| Large | far | far |
| Huge | far | far |
Déclarer des fonctions courtes (NEAR) ou longs (FAR)
À l'occasion, vous voudrez (ou devrez) remplacer le type de fonction par défaut de votre modèle de mémoire. Par exemple, supposons que vous utilisez le modèle de mémoire Large, mais que vous avez une fonction récursive (auto-appelante) dans votre programme, comme ceci :
Chaque fois que la fonction appel power, elle doit faire un appel long (FAR), utilisant plus d'espace de pile et de cycles d'horloge. En déclarant la fonction power comme court (Near), vous éliminez une partie de la surcharge en forçant tous les appels à cette fonction à être courts :
Ainsi, il garantit que power ne peut être appelée que dans le segment de code dans lequel elle a été compilée et que tous les appels à celle-ci sont presque des appels. Cela signifie que si vous utilisez un modèle de code volumineux (Medium, Large ou Huge), vous ne pouvez appeler power qu'à partir du module défini. D'autres modules ont leur propre segment de code et ne peuvent donc pas appeler des fonctions courts dans différents modules. De plus, une fonction court doit être définie ou déclarée avant la première fois qu'elle est utilisée ou le compilateur ne saura pas qu'elle a besoin de générer un appel court. Inversement, déclarer une fonction long signifie qu'un retour long est généré. Dans les petits modèles de code, la fonction longue (far) doit être déclarée ou définie avant sa première utilisation pour s'assurer qu'elle est appelée avec un appel long (far).
Revenons à l'exemple de power. Il est sage de déclarer également le power comme statique, car elle ne doit être appelée que depuis le module actuel. De cette façon, étant statique, son nom ne sera disponible pour aucune fonction en dehors du module. Puisque power prend toujours un nombre fixe de paramètres, vous pouvez optimiser davantage en le déclarant pascal, comme ceci :
Déclarer des pointeurs Near, Far ou Huge
Vous avez vu pourquoi vous pourriez vouloir déclarer des fonctions comme étant d'un modèle différent du reste du programme. Pourquoi voudriez-vous faire la même chose pour les pointeurs ? Pour les mêmes raisons données précédement, soit pour éviter une surcharge inutile (en déclarant Near quand la valeur par défaut serait Far) ou pour référencer quelque chose en dehors du segment par défaut (en déclarant loin ou énorme quand la valeur par défaut serait proche).
Il y a, bien sûr, des pièges potentiels dans la déclaration des fonctions et des pointeurs comme étant des types autres que ceux par défaut. Par exemple, disons que vous avez le petit programme de modèle suivant :
Ce programme fonctionne très bien et, en fait, la déclaration de proximité sur mystr est redondante, car tous les pointeurs, à la fois le code et les données, seront proches. Mais que se passe-t-il si vous recompilez ce programme en utilisant le modèle de mémoire compact (ou grand ou énorme) ? Le pointeur mystr dans main est toujours proche (il s'agit toujours d'un pointeur 16 bits). Cependant, le pointeur s dans myputs est maintenant loin, puisque c'est la valeur par défaut. Elle signifie que myputs va extraire deux mots de la pile dans le but de créer un pointeur éloigné, et l'adresse avec laquelle il se termine ne sera certainement pas celle de mystr.
Comment éviter ce problème ? La solution est de définir les myputs dans le style C moderne, comme ceci :
Maintenant, lorsque Turbo C compile votre programme, il sait que myputs attend un pointeur vers char; et puisque vous compilez sous le grand modèle, il sait que le pointeur doit être Far. Pour cette raison, le Turbo C poussera le registre de segment de données (DS) sur la pile avec la valeur 16 bits de mystr, formant un pointeur éloigné. Que diriez-vous du cas inverse : les paramètres de myputs déclarés aussi Far et compilés avec un petit modèle de données ? Encore une fois, sans le prototype de fonction, vous aurez des problèmes, car le main poussera à la fois le déplacement et l'adresse du segment sur la pile, mais myputs n'attendra que le déplacement. Cependant, avec les définitions de fonction de style prototype, le main ne fera que pousser le déplacement sur la pile. Morale: si vous déclarez explicitement que les pointeurs sont de type lointain ou proche, assurez-vous d'utiliser des prototypes de fonction pour toutes les fonctions pouvant les utiliser.
Pointage vers une adresse segment:déplacement
Comment faire pointer un pointeur Far vers un emplacement mémoire donné (une adresse segment:déplacement spécifique) ? Vous pouvez utiliser la routine de bibliothèque intégrée MK_FP , prenant un segment et un déplacement et renvoie un pointeur Far. Par exemple :
- MK_FP(segment_value, offset_value)
Étant donné un pointeur Far, fp, vous pouvez obtenir la composante segment avec FP_SEG(fp) et la composante de déplacement avec FP_OFF(fp).
Construire des déclarateurs propres
Un déclarateur est une instruction en C que vous utilisez pour déclarer des fonctions, des variables, des pointeurs et des types de données. Et C vous permet de créer des déclarateurs très complexes. Cette page vous donne quelques exemples de déclarateurs afin que vous puissiez vous exercer à les concevoir (et les lire); il vous montrera également quelques pièges à éviter.
La programmation traditionnelle en C vous permet de créer votre déclarateur complet en place, en imbriquant les définitions selon vos besoins. Malheureusement, elle peut rendre les programmes difficiles à lire (et à écrire). Considérez, par exemple, les déc1arateurs suivants, en supposant que vous compilez sous le modèle de petite mémoire (petit code, petites données).
| Déclarateur | Description |
|---|---|
| int f1(); | Fonction retournant int. |
| int *p1; | Pointeur à int |
| int *f2(); | Fonction renvoyant le pointeur vers int |
| int far *p2; | Pointeur far à int |
| int far *f3(); | Fonction near retournant le pointeur far à int |
| int * far f4(); | Fonction far renvoyant le pointeur near vers int. |
| int (*fp1) (int); | Pointeur vers la fonction retournant int et acceptant le paramètre int. |
| int (*fp2) (int *ip); | Pointeur vers la fonction retournant int et acceptant le pointeur vers int. |
| int (far *fp3) (int far tip); | Pointeur far vers la fonction retournant int et acceptant le pointeur far vers int. |
| int (far *list[S]) (int far tip); | Tableau de cinq pointeurs far vers des fonctions renvoyant int et acceptant des pointeurs far vers int. |
| int (far *gopher(int (far * fp[S]) (int far tip))) (int far tip); | Fonction near acceptant un tableau de 5 pointeurs far vers des fonctions renvoyant int et acceptant des pointeurs far vers int, et renvoyant un tel pointeur. |
Ce sont tous des déclarants valides; ils deviennent de plus en plus difficiles à comprendre. Cependant, avec une utilisation judicieuse de typedef, vous pouvez améliorer la lisibilité de ces déclarateurs. Voici les mêmes déclarateurs, réécrits à l'aide d'instructions typedef :
| Déclarateur | Description |
|---|---|
| int f1(); | Fonction retournant int |
|
typedef int *intptr; intptr p1; intptr f2(); |
Pointeur vers int Fonction renvoyant le pointeur vers int |
| typedef int far *farptr; farptr p2; farptr f3(); intptr far f4(); |
Pointeur far vers int Fonction near renvoyant le pointeur far vers int Fonction far renvoyant le pointeur near vers int |
| typedef int (*fncptrl) (int); fncptrl fp1; |
Pointeur vers la fonction retournant int et acceptant le paramètre int |
| typedef int (*fncptr2) (intptr); fncptr2 fp2; |
Pointeur vers la fonction retournant int et acceptant le pointeur vers int |
| typedef int (far *ffptr) (farptr); ffptr fp3; |
Pointeur far vers la fonction retournant int et acceptant le pointeur far vers int |
| typedef ffptr ffplist[5]; ffplist list; | Tableau de 5 pointeurs far vers des fonctions renvoyant int et acceptant des pointeurs far vers int |
| ffptr gopher(ffplist); | Fonction near acceptant un tableau de 5 pointeurs far vers des fonctions renvoyant int et acceptant des pointeurs far vers int, et renvoyant un tel pointeur |
Comme vous pouvez le voir, il y a une grande différence de lisibilité et de clarté entre cette déclaration typedef de gopher et la précédente. Si vous utilisez judicieusement les instructions typedef et les prototypes de fonctions, vous trouverez vos programmes plus faciles à écrire, à déboguer et à maintenir.
Utilisation des fichiers de bibliothèque
Le Turbo C propose une version des routines de bibliothèque standard pour chacun des six modèles de mémoire. Fonctionnant dans l'environnement intégré (TC), le Turbo C est suffisamment intelligent pour se lier dans les bibliothèques appropriées dans le bon ordre, en fonction du modèle que vous avez sélectionné. De même, fonctionnant en tant que compilateur autonome (TCC), le Turbo C est suffisamment intelligent lorsque vous lui demandez de se lier automatiquement. Si, cependant, vous utilisez TLINK (l'éditeur de liens Turbo C) directement (en tant qu'éditeur de liens autonome), vous devez spécifier les bibliothèques à utiliser. Si vous n'utilisez pas les six modèles de mémoire, il vous suffit de copier (sur votre disque de travail ou sur votre disque dur) les fichiers correspondant au(x) modèle(s) que vous utilisez. Voici une liste des fichiers de bibliothèque nécessaires pour chaque modèle de mémoire :
| Modèle | Description |
|---|---|
| Tiny | C0T.OBJ, MATHS.LIB, CS.LIB |
| Small | C0S.OBJ, MATHS.LIB, CS.LIB |
| Compact | C0C.OBJ, MATHC.LIB, CC.LIB |
| Medium | C0M.OBJ, MATHM.LIB, CM.LIB |
| Large | C0L.OBJ, MATHL.LIB, CL.LIB |
| Huge | C0H.OBJ, MATHH.LIB, CH.LIB |
Notez que les modèles minuscules et petits utilisent les mêmes bibliothèques, mais ont des fichiers de démarrage différents (C0T.OBJ vs C0S.OBJ). De plus, si votre système possède un coprocesseur mathématique 8087, vous aurez besoin du fichier FP87.LIB; si à la place vous souhaitez émuler le 8087, vous aurez besoin du fichier EMU.LIB. Voici quelques exemples de lignes de commande TLINK :
|
tlink c0m abc, prog, mprog, fp87 mathm cm tlink e0e d e f, plan, mplan, emu mathc cc |
Le premier produira un programme exécutable appelé PROG.EXE, avec les bibliothèques de modèle moyen et la bibliothèque de support 8087 liées dedans. La deuxième ligne de commande produira PLAN.EXE, compilé en tant que programme de modèle compact émulant les routines à virgule flottante 8087 si un coprocesseur n'est pas disponible au moment de l'exécution. Remarque: l'ordre des objets et des bibliothèques est très important. Vous devez toujours placer le module de démarrage C (C0x.OBJ) en premier dans la liste des objets. La liste des bibliothèques doit contenir, dans cet ordre spécifique :
- vos propres bibliothèques (le cas échéant)
- FP87.LIB ou EMU.LIB, suivi de MATHx.LIB (nécessaire uniquement si vous utilisez une virgule flottante)
- Cx.LIB (fichier de bibliothèque d'exécution Turbo C standard)
(Le x dans C0x, MATHx et Cx fait référence à la lettre spécifiant le modèle de mémoire: t, s, m, c, l ou h.)