
Pointeurs et mémoire dynamique
Un pointeur est une variable contenant l'adresse numérique d'un autre objet de données. Un pointeur fournit un accès indirect aux données. Par exemple, si vous avez un pointeur sur un enregistrement et que vous transmettez ce pointeur à une procédure, la procédure peut manipuler n'importe quel champ à l'aide du pointeur. La procédure n'a pas besoin de sa propre copie des données.
En Pascal, vous utilisez principalement des pointeurs comme des descripteurs d'objets de mémoire dynamique. La «mémoire dynamique» consiste en la mémoire que le programme demande explicitement au moment de l'exécution. La mémoire dynamique vous offre de nombreux avantages. Il permet à votre utilisation de la mémoire d'augmenter et de se contracter en fonction de vos besoins. Vous n'avez pas besoin de spécifier une taille ou une limite maximale.
Étant donné que la mémoire dynamique est allouée au moment de l'exécution, votre programme ne peut pas savoir à l'avance où se trouve le bloc. Le Pascal renvoie donc un pointeur lorsqu'il alloue de la mémoire dynamique. Le pointeur permet d'accéder aux données.
La mémoire dynamique vous permet de créer de puissantes structures de données telles que des listes chaînées de caractères et des arbres binaires. Ces structures, décrites à la fin de cette page, sont des réseaux de données dans lesquels des pointeurs assurent les liens de connexion.
Dans QuickPascal, vous pouvez également utiliser des pointeurs pour pointer vers des variables ordinaires (non dynamiques). Cette page commence par expliquer les bases des pointeurs utilisant des variables non dynamiques.
Déclaration et accès aux pointeurs
L'utilisation des pointeurs consiste en trois étapes principales, que vous devez toujours effectuer dans cet ordre :
- Déclarez le pointeur comme un type spécifique.
- Initialisez le pointeur.
- Utilisez le pointeur en affectant sa valeur, en testant sa valeur ou en accédant à la valeur vers laquelle il pointe.
Déclarer des pointeurs
Comme les autres variables, les pointeurs ont des types définis et ne peuvent pointer que vers une variable du type approprié. Vous pouvez déclarer un pointeur avec la syntaxe suivante :
| PointerName: ^DataType; |
Des exemples de déclarations de pointeur sont présentés ci-dessous :
Après avoir déclaré un pointeur, il ne pointe sur aucune valeur significative ; vous pouvez produire des erreurs si vous essayez de l'utiliser. La première chose que vous devez faire après avoir déclaré un pointeur est de l'initialiser.
Initialisation des pointeurs
Après avoir déclaré un pointeur, vous devez l'initialiser à une adresse. Vous pouvez toujours initialiser un pointeur sur la valeur spéciale NIL. Cette valeur indique que le pointeur est temporairement désactivé - il n'a pas d'objet vers lequel pointer. Votre programme peut tester cette condition et prendre les mesures appropriées. La valeur NIL est utile pour indiquer la fin d'un arbre ou d'une liste chaînée. Voici un exemple d'affectation à NIL :
- my_ptr:=NIL;
Pour affecter l'adresse d'une variable à un pointeur, vous pouvez utiliser soit l'opérateur d'adresse de (@), soit la fonction Addr. La syntaxe est la suivante :
| Pointer:=Addr(Variable) |
| Pointer:=@Variable |
La Variable peut être n'importe quelle variable du type apparaissant dans la déclaration de Pointer. Un exemple est illustré ci-dessous :
Dans la section suivante, vous apprendrez à affecter une valeur à un pointeur en faisant un appel de procédure de mémoire dynamique.
Manipulation des pointeurs
La manipulation des pointeurs en Pascal est extrêmement limitée. En plus des méthodes décrites ci-dessus, la seule façon de manipuler un pointeur est de lui affecter la valeur d'un autre pointeur du même type. Par exemple, l'énoncé :
- ptr1:=ptr2;
fait pointer ptr1 vers le même emplacement que ptr2. Ce type d'affectation est souvent utile pour traiter des structures de données telles que des listes chaînées. Une fois que vous avez déclaré et initialisé un pointeur, vous pouvez l'utiliser de l'une des manières suivantes :
- Attribuez la valeur du pointeur lui-même à un autre pointeur.
- Testez la valeur du pointeur lui-même.
- Accéder à la valeur de la variable pointée.
Le nombre d'opérations que vous pouvez effectuer avec la valeur du pointeur est limité. Comme décrit ci-dessus, vous pouvez affecter la valeur d'un pointeur à un autre pointeur du même type. Vous pouvez également tester l'égalité d'un pointeur avec NIL ou avec un autre pointeur. Par exemple, l'énoncé :
- If(ptr1 = ptr2)Then ...
exécute l'instruction suivante THEN si ptr1 et ptr2 pointent vers la même variable. Notez que si ptr1 et ptr2 pointent vers des emplacements différents, alors l'expression ptr1 = ptr2 est évaluée comme False, même si les objets vers lesquels pointent ptr1 et ptr2 sont égaux.
Vous pouvez également accéder à la valeur de la variable indiquée par le pointeur. Cette valeur peut être manipulée comme vous pouvez manipuler la variable elle-même. Utilisez la syntaxe suivante pour accéder à la variable indiquée par le pointeur :
| PointerName^ |
Cette opération s'appelle «déréférencer» le pointeur. Par exemple, le code suivant définit la valeur de x sur 5, puis affecte cette valeur à y :
Lors du test des valeurs de pointeur, gardez à l'esprit la différence entre un pointeur et la variable pointée. Par exemple, la déclaration :
- If(ptr1^ = ptr2^)Then ...
exécute l'instruction suivant THEN si les objets pointés par ptr1 et ptr2 sont égaux. Comparez cet exemple avec l'exemple d'instruction IF précédent, n'étant évalué à True que si ptr1 et ptr2 pointaient vers le même objet.
Allocation de mémoire dynamique
Dans la plupart des programmes, vous devez évaluer la quantité maximale de mémoire dont le programme aura besoin. Si la quantité de données devient plus importante que prévu, vous devez réécrire le programme puis le recompiler. Cependant, la mémoire dynamique permet à votre utilisation de la mémoire d'augmenter en fonction des besoins du programme. La quantité de mémoire physique disponible est la seule limite ultime de la mémoire dynamique.
L'utilisation de pointeurs est essentielle à toutes les opérations de mémoire dynamique. Lorsque QuickPascal alloue de la mémoire, il renvoie un pointeur. Le pointeur vous donne accès au bloc mémoire.
Il existe deux méthodes de base pour allouer dynamiquement de la mémoire :
- Allocation d'un objet à la fois (New et Dispose).
- Allocation d'un bloc de mémoire (GetMem et FreeMem).
Affectation d'un seul objet
En utilisant la procédure New, vous allouez un espace égal à la taille du type de données associé au pointeur. La syntaxe est :
| New(Pointer) |
Une fois la fonction New exécutée, le QuickPascal attribue l'adresse du bloc de mémoire dynamique à Pointer. Le pointeur doit être une variable préalablement déclarée. L'exemple suivant montre comment déclarer un pointeur de type Byte ; allouer de la mémoire via le pointeur ; puis utilisez la variable dynamique pour conserver, manipuler et afficher une valeur.
Comme décrit dans la section précédente, int_ptr^ est un exemple de pointeur déréférencé. int_ptr lui-même est un pointeur, ne pouvant être manipulé que de quelques manières restreintes. Cependant, int_ptr^ est équivalent à une variable ordinaire de type Byte. Utilisez int_ptr^ partout où vous utiliseriez une variable Byte.
Pour supprimer un objet de mémoire dynamique créé avec la fonction New, utilisez la fonction Dispose.
Allocation d'un bloc mémoire
Les fonctions GetMem et FreeMem sont similaires à New et Dispose. Cependant, GetMem et FreeMem traitent des blocs entiers de mémoire plutôt qu'un objet à la fois. Une fois qu'un bloc est alloué, vous y accédez comme s'il s'agissait d'un tableau de taille indéfinie.
Utilisez la procédure GetMem pour sélectionner la taille d'un bloc de mémoire dynamique. La taille doit être un multiple de la taille du type d'élément du tableau. Par conséquent, si size est le nombre d'éléments que vous souhaitez allouer et basetype est le type d'élément du tableau, passez les paramètres suivants à GetMem :
- Size*SizeOf(base_type)
Une manière courante d'utiliser GetMem consiste à déclarer d'abord un type de tableau d'éléments max_elements, où max_elements est le plus grand nombre possible d'éléments du type de base. Étant donné que le type est un tableau, vous pouvez accéder à la mémoire dans tout le bloc avec un index de tableau. Par exemple, le code suivant effectue les déclarations nécessaires, puis appelle GetMem pour renvoyer un bloc mémoire :
Le array_ptr pointe maintenant vers un tableau de type base_type. Vous pouvez traiter array_ptr comme n'importe quel tableau. Le plus grand index de ce tableau est la taille. Pour accéder à n'importe quel élément de ce tableau, utilisez la syntaxe suivante :
| ArrayPointer^[Index] |
L'exemple ci-dessous demande un bloc mémoire de 100 éléments de long. Dans ce cas, array_size est défini sur 100, mais au moment de l'exécution, le programme peut définir array_size sur la longueur dont il a besoin.
- Const
- max_elements=65520 DIV SizeOf(Real);
-
- Type
- some_reals:Array[1..max_elements] of Real;
-
- Var
- rptr:^some_reals;
- i:Byte;
- array_size:Word;
-
- BEGIN
- array_size:=100;
- GetMem(rptr, array_size*SizeOf(Real));
- For i:=1 TO array_size do Begin
- rptr^[i]:=i;
- WriteLn(rptr^[i]);
- End;
- FreeMem(rptr,array_size*SizeOf(Real));
- END.
La procédure FreeMem libère des blocs mémoire alloués par GetMem. Si vous n'avez plus besoin d'utiliser un bloc de mémoire particulier, c'est une bonne idée de libérer de la mémoire. Sinon, le programme peut épuiser toute la mémoire disponible au fil du temps. La procédure FreeMem prend les mêmes paramètres que GetMem. Assurez-vous que la taille que vous spécifiez dans FreeMem correspond à la taille allouée avec GetMem.
Le tableau suivant résume les procédures fournies par QuickPascal pour une utilisation avec des pointeurs.
| Routine | Objectif | Exemple |
|---|---|---|
| Addr | Renvoie l'adresse d'un objet de données (identique à l'opérateur @) | aptr:=Addr(I); |
| Dispose | Dispose d'une variable dynamique | Dispose(nextptr); |
| FreeMem | Dispose d'une variable dynamique de taille donnée en octets | FreeMem(aptr,512); |
| GetMem | Crée une variable dynamique d'une taille donnée en octets | GetMem(aptr,512); |
| New | Crée une variable dynamique | New(aptr) |
Listes liées
Les piles, les files d'attente et les arbres sont des structures de données étant des listes chaînées. Une "liste chaînée" est une collection d'enregistrements alloués dynamiquement, chacun ayant un champ étant un pointeur vers l'enregistrement suivant. Essentiellement, les pointeurs servent de connecteurs entre deux éléments. En modifiant la valeur des pointeurs, vous pouvez trier ou réorganiser la liste de n'importe quelle manière, sans déplacer physiquement aucun des enregistrements entreposés.
Si votre programme implémente un algorithme simple, vous n'avez pas besoin d'utiliser ces structures de données. Cependant, ces structures vous donnent beaucoup de puissance pour résoudre des tâches informatiques complexes. Ils peuvent atteindre n'importe quelle taille et ils laissent le programme parcourir, analyser et restructurer un réseau de chemins de données. La seule limite à la complexité est votre propre imagination.
Le programme LIST.PAS ajoute des enregistrements à une liste, les supprime et imprime le contenu de la liste. Les données sont entreposées dans un enregistrement déclaré comme :
Notez que le deuxième champ de type stack_rec pointe vers un autre enregistrement - également de type stack_rec. Bien que cette autoréférence puisse sembler paradoxale, elle est parfaitement légale. Cela signifie simplement que le deuxième champ est le connecteur vers un autre enregistrement du même type. Le champ de données contient les données à entreposer. Pour les programmes plus complexes, l'enregistrement peut avoir n'importe quel nombre de champs de données appropriés.
Pour créer une liste, déclarez d'abord un pointeur vers le début de la liste et initialisez ce pointeur à NIL :
Le programme a deux procédures principales, push et pop. Ces procédures modélisent le comportement des instructions PUSH et POP du microprocesseur. La liste chaînée de ce programme est un mécanisme du dernier entré, premier sorti, tout comme la pile du microprocesseur 8086. La procédure push ajoute des éléments au début de la liste, et pop supprime également ces éléments du premier plan. Par conséquent, le dernier élément entreposé est également le premier élément récupéré.
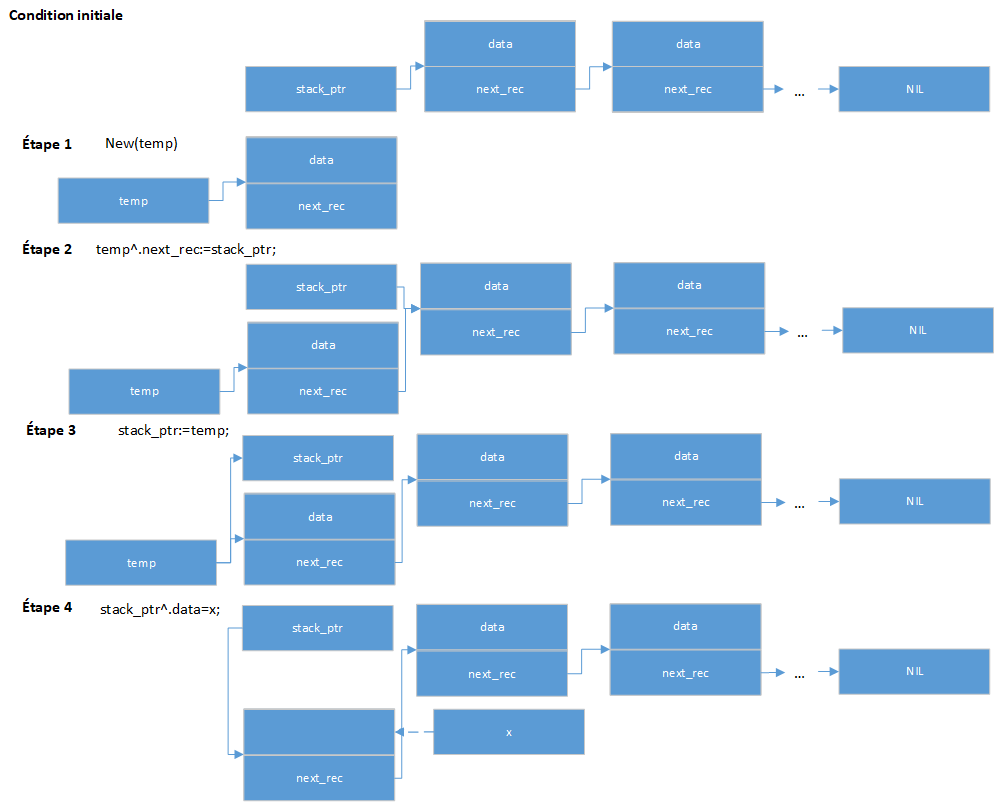
Le code de la procédure push insère un nouvel enregistrement au début de la liste, puis affecte la nouvelle valeur (x) au champ de données. Ces actions simulent l'action de pousser x sur le dessus d'une pile.
Les lignes de code ci-dessus montrent les quatre étapes nécessaires à la procédure push pour ajouter un nouvel enregistrement à la liste liée. Ces quatre étapes sont listées ci-dessous :
- La première instruction, New(temp), alloue un emplacement mémoire suffisamment grand pour contenir un enregistrement avec les champs data et next_rec. Le pointeur temp pointe maintenant vers ce nouvel enregistrement.
- Pour insérer cet enregistrement au début de la liste, le code réaffecte deux valeurs de pointeur. Tout d'abord, la procédure définit le champ next_rec pour qu'il pointe vers l'élément actuel au début de la liste. La variable de pointeur stack_ptr pointe vers le début de la liste, de sorte que la ligne de code suivante affecte la valeur stack_ptr au champ next_rec du nouvel enregistrement (le nouvel enregistrement est appelé temp^).
- temp^.next_rec:=stack_ptr;
- Ensuite, le pointeur stack_ptr doit être réaffecté à temp. Le résultat est que l'élément précédemment au début de la liste est maintenant le deuxième élément (à cause de l'étape 2), et le nouvel enregistrement est au tout début.
- Maintenant que le nouvel enregistrement a été créé et inséré, vous pouvez simplement charger les nouvelles données dans l'enregistrement. L'instruction suivante affecte la valeur de x au champ de données du nouvel enregistrement. Notez qu'en raison de l'étape 3, le nouvel enregistrement peut être appelé stack_ptr^.
- stack_ptr^.data:=x;
Notez que temp pointe toujours vers le nouvel enregistrement, mais maintenant temp peut être ignoré car stack_ptr pointe également vers cet enregistrement.
L'image suivante illustre la procédure push :
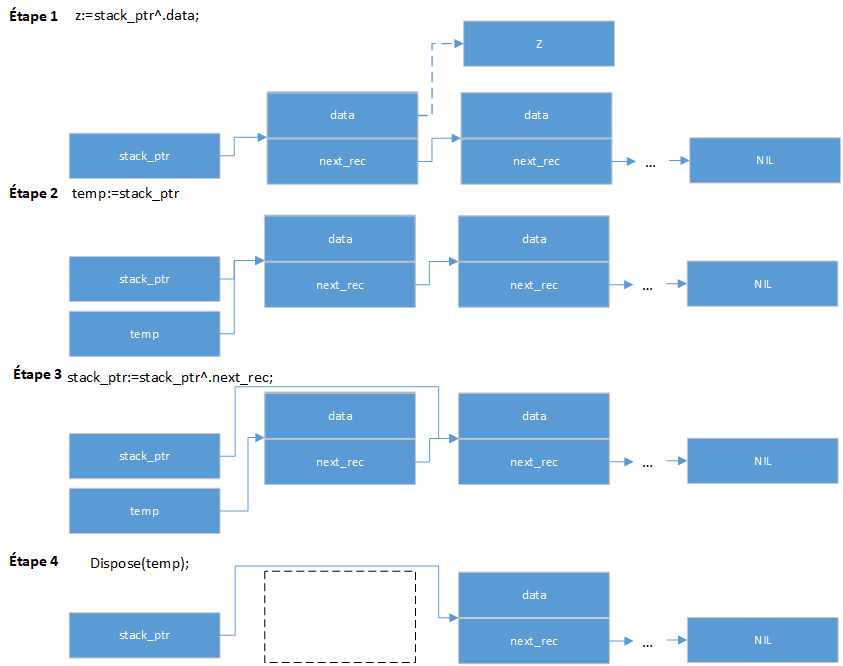
La procédure pop fonctionne en exécutant la série d'étapes en sens inverse, comme indiqué dans le code ci-dessous :
- z:=stack_Ptr^.data;
- temp:=stack_ptr;
- stack_ptr:=stack_ptr^.next_rec;
- Dispose(temp);
- La procédure extrait la valeur du haut de la pile en enregistrant la valeur dans le champ de données du premier enregistrement. L'instruction suivante enregistre
cette valeur en la chargeant dans z, la valeur de sortie de la procédure :
- z:=stack_ptr^.data;
- Notez que l'enregistrement actuel au début de la liste doit être supprimé. Le pointeur temp pointe sur cet enregistrement, afin que la procédure puisse utiliser temp pour supprimer l'enregistrement ultérieurement :
- temp:=stack_ptr;
- Ensuite, le pointeur vers le haut de la pile, stack_ptr, est déplacé de sorte qu'il pointe vers stack_ptr^.next_rec. Notez que stack_ptr pointe vers l'enregistrement supérieur de la liste, étant un enregistrement avec deux champs : le champ de données et le champ next_rec. Le champ next_rec de cet enregistrement supérieur pointe actuellement vers l'enregistrement suivant de la liste. La déclaration suivante :
- stack_ptr:=stack_ptr^.next_rec;
- L'ancien enregistrement au début de la liste, pointé par temp, est maintenant supprimé de la mémoire.
- Dispose(temp);
déplace stack_ptr pour pointer vers le même enregistrement que celui vers lequel stack_ptr^.next_rec pointe. En affectant stack_ptr pour pointer vers le même enregistrement vers lequel pointait l'enregistrement du haut, il n'y a plus de pointeur dans la liste pointant vers l'enregistrement étant en haut. L'enregistrement a été supprimé de la liste.
La figure suivante illustre la procédure pop :
Arbres binaires
Les arbres binaires sont l'un des nombreux types de structures arborescentes pouvant être créés avec des variables de pointeur. Les arbres binaires sont plus complexes que les listes chaînées décrites dans la section précédente. Chaque enregistrement (appelé "noeud") n'a pas un, mais deux pointeurs. Chacun de ces pointeurs connecte le noeud à deux autres noeuds (appelés "enfants") - un à sa gauche et un à sa droite.
La figure suivante montre un exemple d'arbre binaire. Comme vous pouvez le voir, un enfant de gauche contient toujours une valeur plus petite que le "noeud parent" et l'enfant de droite contient une valeur plus grande que le noeud parent. De plus, le sous-arbre entier d'un noeud donné contient des valeurs plus petites que le parent, s'il se trouve du côté gauche, ou des valeurs plus grandes que le parent, s'il se trouve du côté droit. Cette organisation permet une recherche efficace de n'importe quelle valeur dans l'arborescence.
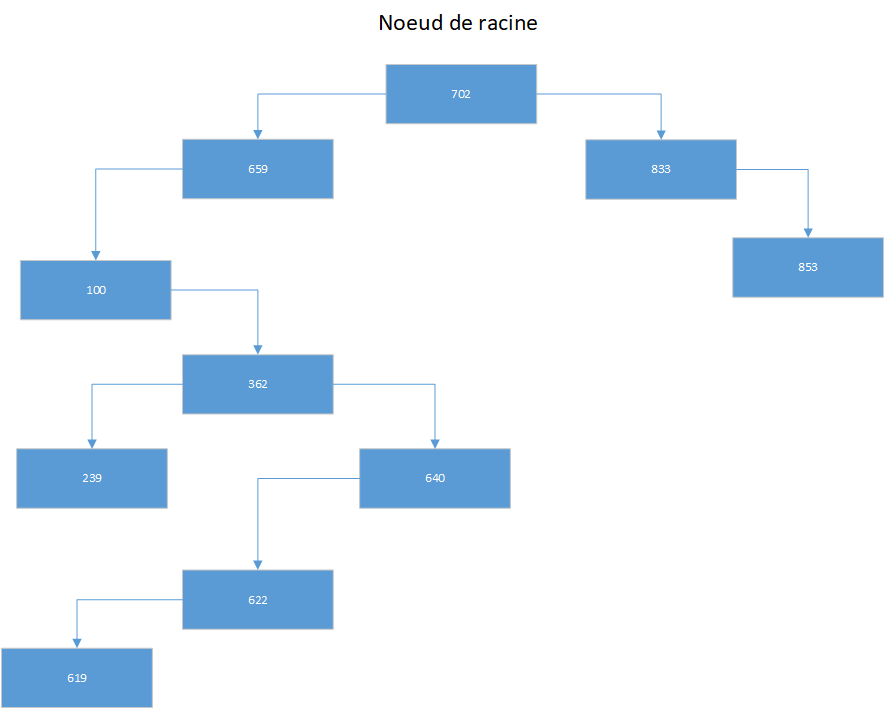
Cet exemple d'arbre binaire ne contient que des noeuds arithmétiques simples. Cependant, vous pouvez créer des arbres binaires contenant n'importe quel type d'informations (tant que chaque noud est du même type). Vous pouvez également organiser ou trier les éléments de l'arborescence à l'aide de diverses méthodes.
Pour construire un arbre binaire, déclarez d'abord les types suivants :
Semblable au type d'enregistrement d'une liste chaînée, le type Node contient des pointeurs pointant vers d'autres enregistrements du même type. Si le noud manque actuellement d'enfant gauche ou droit, le champ de pointeur correspondant doit être initialisé à NIL.
Pour créer un arbre, déclarez d'abord un pointeur vers le début de l'arbre et initialisez ce pointeur à NIL, comme indiqué ci-dessous. Bien qu'aucun noeud n'existe actuellement dans l'arborescence, un sera éventuellement inséré. Le premier noeud deviendra l'ancêtre d'origine de tous les autres noeuds de l'arbre.
Vous pouvez commencer à construire l'arborescence en insérant des valeurs, pouvant être générées de plusieurs façons : entrée standard, un fichier de données ou avec la fonction Random. Chaque fois que vous obtenez une valeur, ajoutez-la à l'arborescence en suivant les cinq étapes suivantes :
- Examinez root_ptr, le pointeur vers le premier noeud de l'arbre. L'expression root_ptr^ est équivalente au premier noeud, s'il existe. Si aucun noeud n'existe, root_ptr est égal à NIL.
- Si le pointeur est NIL, ajoutez un nouvel enregistrement et affectez le pointeur pour qu'il pointe vers cet enregistrement. Chargez le champ de données du nouvel enregistrement avec la valeur à ajouter.
- Si le pointeur n'est pas NIL, alors un noeud existe et doit être comparé à la nouvelle valeur. Comparez la valeur au champ de données du noeud.
- Si la nouvelle valeur est inférieure à celle du noeud, utilisez le champ de gauche comme nouvelle valeur de pointeur et passez à l'étape 2.
- Si la nouvelle valeur est supérieure à celle du noeud, utilisez le champ de droite comme nouvelle valeur de pointeur et passez à l'étape 2.
Vous pouvez utiliser une procédure récursive pour implémenter ces étapes. Les listes chaînées et les arbres sont souvent de bons sujets pour les solutions récursives. Une procédure «récursive» présente un algorithme simplifié en s'appelant elle-même à plusieurs reprises. Dans le cas des arbres binaires, une procédure récursive trace les branches gauche et droite à plusieurs reprises jusqu'à ce qu'elle trouve une valeur correspondante à la fin de l'arbre.
Dans le cas des étapes décrites ci-dessus, vous appelez initialement la procédure en transmettant la valeur que vous souhaitez insérer et root_ptr comme paramètres. La procédure s'appelle pour tracer le sous-arbre gauche ou droit, en passant à chaque fois le champ gauche ou droit comme paramètre de pointeur, comme suit :
Remarquez à quel point la procédure ci-dessus est courte. Le travail réel d'insertion du noeud est la dernière étape du processus, et il est effectué par une procédure distincte écrite juste à cet effet :
L'initialisation des champs gauche et droit à NIL est critique. Sinon, la procédure _insert produit des résultats imprévisibles lorsqu'elle atteint la fin de l'arborescence et tente une comparaison. Les procédures ci-dessus utilisent effectivement NIL comme indicateur de fin d'arbre.