
Les structures
Une structure est un ensemble d'une ou plusieurs variables, éventuellement de types différents, regroupées sous un nom unique pour une manipulation plus aisée. (Les structures sont appelées «enregistrements» dans certains langages, notamment Pascal.) Les structures aident à organiser des données complexes, en particulier dans les programmes volumineux, car elles permettent de traiter un groupe de variables liées comme une unité plutôt que comme des entités séparées.
Un exemple traditionnel de structure est le registre de paie : un employé est décrit par un ensemble d'attributs tels que le nom, l'adresse, le numéro de sécurité sociale, le salaire,... Certains d'entre eux peuvent à leur tour être des structures : un nom a plusieurs composantes, tout comme une adresse et même un salaire. Un autre exemple, plus typique du C, vient des graphiques : un point est une paire de coordonnées, un rectangle est une paire de points,...
Le principal changement apporté par la norme ANSI est de définir l'affectation de structure - les structures peuvent être copiées et affectées, transmises à des fonctions et renvoyées par des fonctions. Cela est pris en charge par la plupart des compilateurs depuis de nombreuses années, mais les propriétés sont désormais définies avec précision. Les structures et tableaux automatiques peuvent désormais également être initialisés.
Notions de base sur les structures
Créons quelques structures adaptées aux graphiques. L'objet de base est un point, dont nous supposerons qu'il possède une coordonnée x et une coordonnée y, toutes deux des nombres entiers.
Les deux composantes peuvent être placés dans une structure déclarée comme ceci :
Le mot clef struct introduit une déclaration de structure, étant une liste de déclarations entre accolades. Un nom facultatif appelé balise de structure peut suivre le mot struct (comme avec point ici). La balise nomme ce type de structure et peut être utilisée ultérieurement comme raccourci pour la partie de la déclaration entre accolades.
Les variables nommées dans une structure sont appelées membres. Un membre ou une balise de structure et une variable ordinaire (c'est-à-dire non membre) peuvent avoir le même nom sans conflit, car ils peuvent toujours être distingués par le contexte. De plus, les mêmes noms de membres peuvent apparaître dans différentes structures, bien que, par souci de style, on n'utilise normalement les mêmes noms que pour des objets étroitement liés.
Une déclaration de structure définit un type. L'accolade droite terminant la liste des membres peut être suivie d'une liste de variables, comme pour tout type de base. C'est-à-dire :
- struct { ... } x, y, z;
est syntaxiquement analogue à :
- int x, y, z;
dans le sens où chaque instruction déclare x, y et z comme étant des variables du type nommé et fait en sorte que de l'espace leur soit réservé.
Une déclaration de structure n'étant pas suivie d'une liste de variables ne réserve aucun espace d'entreposage; elle décrit simplement un modèle ou une forme de structure. Si la déclaration est balisée, cependant, la balise peut être utilisée ultérieurement dans les définitions d'instances de la structure. Par exemple, étant donné la déclaration de point ci-dessus :
- struct point pt;
définit une variable pt étant une structure de type struct point. Une structure peut être initialisée en faisant suivre sa définition d'une liste d'initialiseurs, chacun étant une expression constante, pour les membres :
- struct maxpt = { 320, 200 };
Une structure automatique peut également être initialisée par affectation ou par appel d'une fonction renvoyant une structure du type approprié.
Un membre d'une structure particulière est référencé dans une expression par une construction de la forme :
| structure-name.member |
L'opérateur de membre de structure «.» relie le nom de la structure et le nom du membre. Pour imprimer les coordonnées du point pt, par exemple :
- printf("%d,%d", pt.x, pt.y);
ou pour calculer la distance de l'origine (0,0) à pt :
Les structures peuvent être imbriquées. Une représentation d'un rectangle est une paire de points désignant les coins diagonalement opposés :
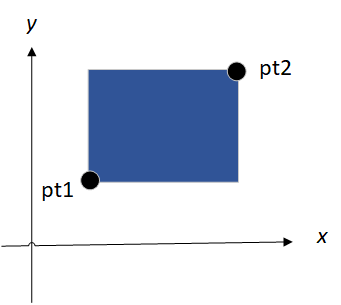
La structure rect contient deux structures de points. Si nous déclarons screen comme :
- struct rect screen;
alors :
- screen.pt1.x
fait référence à la coordonnée x du membre pt1 de l'écran.
Structures et fonctions
Les seules opérations légales sur une structure sont sa copie ou son affectation en tant qu'unité, la prise de son adresse avec & et l'accès à ses membres. La copie et l'affectation incluent le passage d'arguments aux fonctions et le retour de valeurs à partir de fonctions également. Les structures ne peuvent pas être comparées. Une structure peut être initialisée par une liste de valeurs de membres constantes ; une structure automatique peut également être initialisée par une affectation.
Étudions les structures en écrivant des fonctions pour manipuler des points et des rectangles. Il existe au moins trois approches possibles : passer des composantes séparément, passer une structure entière ou passer un pointeur vers celle-ci. Chacune a ses bons et ses mauvais côtés.
La première fonction, makepoint, prendra deux entiers et renverra une structure de points :
Notez qu'il n'y a pas de conflit entre le nom du paramètre et le membre portant le même nom ; en effet, la réutilisation des noms accentue la relation.
makepoint peut désormais être utilisé pour initialiser dynamiquement n'importe quelle structure ou pour fournir des paramètres de structure à une fonction :
L'étape suivante consiste en un ensemble de fonctions permettant d'effectuer des opérations arithmétiques sur des points. Par exemple :
Ici, les paramètres et la valeur de retour sont des structures. Nous avons incrémenté les composants dans p1 plutôt que d'utiliser une variable temporaire explicite pour souligner que les paramètres de structure sont passés par valeur comme les autres.
Autre exemple, la fonction ptinrect teste si un point est à l'intérieur d'un rectangle, où nous avons adopté la convention selon laquelle un rectangle comprend ses côtés gauche et inférieur mais pas ses côtés supérieur et droit&mbsp;:
Cela suppose que le rectangle est présenté sous une forme standard où les coordonnées pt1 sont inférieures aux coordonnées pt2. La fonction suivante renvoie un rectangle garanti comme étant sous forme canonique :
- #define min(a, b) ((a) < (b) ? (a) : (b))
- #define max(a, b) ((a) > (b) ? (a) : (b))
-
- /* canonrect: canoniser les coordonnées du rectangle */
- struct rect canonrect(struct rect r) {
- struct rect temp;
- temp.pt1.x = min(r.pt1.x, r.pt2.x);
- temp.pt1.y = min(r.pt1.y, r.pt2.y);
- temp.pt2.x = max(r.pt1.x, r.pt2.x);
- temp.pt2.y = max(r.pt1.y, r.pt2.y);
- return temp;
- }
Si une grande structure doit être transmise à une fonction, il est généralement plus efficace de transmettre un pointeur que de copier la structure entière. Les pointeurs de structure sont comme des pointeurs vers des variables ordinaires. La déclaration :
- struct point *pp;
dit que pp est un pointeur vers une structure de type struct point. Si pp pointe vers une structure de type point, *pp est la structure, et (*pp).x et (*pp).y sont les membres. Pour utiliser pp, nous pourrions écrire, par exemple :
Les parenthèses sont nécessaires dans «(*pp).x» car la priorité de l'opérateur membre de structure «.» est supérieure à «*». L'expression «*pp.x» signifie «*(pp.x)», ce qui est illégal ici car x n'est pas un pointeur.
Les pointeurs vers des structures sont si fréquemment utilisés qu'une notation alternative est fournie comme raccourci. Si p est un pointeur vers une structure, alors :
- p->member-of-structure
fait référence au membre particulier. Nous pourrions donc écrire à la place :
- printf("L'origine est (%d,%d)\n", pp->x, pp->y);
«.» et «->» s'associent de gauche à droite, donc si nous avons :
- struct rect r, *rp = &r;
alors ces quatre expressions sont équivalentes :
- r.pt1.x
- rp->pt1.x
- (r.pt1).x
- (rp->pt1).x
Les opérateurs de structure «.» et «->», ainsi que () pour les appels de fonction et [] pour les indices, se trouvent au sommet de la hiérarchie de priorité et sont donc très étroitement liés. Par exemple, étant donné la déclaration :
alors :
- ++p->len
incrémente len, pas p, car la parenthèse implicite est ++(p->len). Les parenthèses peuvent être utilisées pour modifier la liaison : (++p)->len incrémente p avant d'accéder à len, et (p++)->len incrémente p après. (Ce dernier ensemble de parenthèses est inutile.) De la même manière, *p->str récupère tout ce vers quoi str pointe ; *p->str++ incrémente str après avoir accédé à tout ce vers quoi il pointe (tout comme *s++) ; (*p->str)++ incrémente tout ce vers quoi str pointe ; et *p++->str incrémente p après avoir accédé à tout ce vers quoi str pointe.
Tableaux de structures
Envisagez d'écrire un programme pour compter les occurrences de chaque mot-clef C. Nous avons besoin d'un tableau de chaînes de caractères pour contenir les noms et d'un tableau d'entiers pour les comptages. Une possibilité consiste à utiliser deux tableaux parallèles, keyword et keycount, comme dans :
Mais le fait même que les tableaux soient parallèles suggère une organisation différente, un tableau de structures. Chaque mot-clef est une paire :
et il y a un tableau de paires. La déclaration de structure :
déclare une clef de type de structure, définit un tableau keytab de structures de ce type et réserve un espace d'entreposage pour celles-ci. Chaque élément du tableau est une structure. Cela pourrait également être écrit :
Étant donné que la structure keytab contient un ensemble constant de noms, il est plus facile d'en faire une variable externe et de l'initialiser une fois pour toutes lorsqu'elle est définie. L'initialisation de la structure est analogue aux précédentes : la définition est suivie d'une liste d'initialiseurs entre accolades :
Les initialiseurs sont répertoriés par paires correspondant aux membres de la structure. Il serait plus précis d'entourer les initialiseurs de chaque «ligne» ou structure entre accolades, comme dans :
- { "auto", 0 },
- { "break", 0 },
- { "case", 0 },
- ...
mais les accolades internes ne sont pas nécessaires lorsque les initialiseurs sont de simples variables ou des chaînes de caractères, et lorsque tous sont présents. Comme d'habitude, le nombre d'entrées dans le tableau keytab sera calculé si les initialiseurs sont présents et que le [] est laissé vide.
Le programme de comptage de mots-clefs commence par la définition de keytab. La routine principale lit l'entrée en appelant à plusieurs reprises une fonction getword récupérant un mot à la fois. Chaque mot est recherché dans keytab avec une version de la fonction de recherche binaire que nous avons écrite au Contrôle du flux. La liste des mots-clefs doit être triée par ordre croissant dans le tableau.
- #include <stdio.h>
- #include <ctype.h>
- #include <string.h>
-
- #define MAXWORD 100
-
- int getword(char *, int);
- int binsearch(char *, struct key *, int);
-
- /* compter les mots-clefs C */
- main() {
- int n;
- char word[MAXWORD];
- while (getword(word, MAXWORD) != EOF) if (isalpha(word[0])) if ((n = binsearch(word, keytab, NKEYS)) >= 0) keytab[n].count++;
- for (n = 0; n < NKEYS; n++) if (keytab[n].count > 0) printf("%4d %s\n",keytab[n].count, keytab[n].word);
- return 0;
- }
- /* binsearch: trouver le mot dans tab[0]...tab[n-1] */
- int binsearch(char *word, struct key tab[], int n) {
- int cond;
- int low, high, mid;
- low = 0;
- high = n - 1;
- while (low <= high) {
- mid = (low+high) / 2;
- if ((cond = strcmp(word, tab[mid].word)) < 0) high = mid - 1; else
- if (cond > 0) low = mid + 1;
- else return mid;
- }
- return -1;
- }
Nous allons montrer la fonction getword dans un instant ; pour l'instant, il suffit de dire que chaque appel à getword trouve un mot, étant copié dans le tableau nommé comme premier paramètre. La quantité NKEYS est le nombre de mots-clefs dans keytab. Bien que nous puissions compter cela à la main, il est beaucoup plus facile et plus sûr de le faire à la machine, surtout si la liste est sujette à changement. Une possibilité serait de terminer la liste des initialiseurs avec un pointeur nul, puis de boucler le long de keytab jusqu'à ce que la fin soit trouvée.
Mais c'est plus que nécessaire, car la taille du tableau est complètement déterminée au moment de la compilation. La taille du tableau est la taille d'une entrée multipliée par le nombre d'entrées, donc le nombre d'entrées est juste :
| taille de la keytab / taille de la clef struct |
C fournit un opérateur unaire de compilation appelé sizeof pouvant être utilisé pour calculer la taille de n'importe quel objet. Les expressions :
| sizeof object |
et :
| sizeof(nom du type) |
renvoie un entier égal à la taille de l'objet ou du type spécifié en octets. (Strictement, sizeof produit une valeur entière non signée dont le type, size_t, est défini dans l'entête <stddef.h>.) Un objet peut être une variable, un tableau ou une structure. Un nom de type peut être le nom d'un type de base comme int ou double, ou un type dérivé comme une structure ou un pointeur.
Dans notre cas, le nombre de mots-clefs est la taille du tableau divisée par la taille d'un élément. Ce calcul est utilisé dans une instruction #define pour définir la valeur de NKEYS :
- #define NKEYS (sizeof keytab / sizeof(struct key))
Une autre façon d'écrire cela est de diviser la taille du tableau par la taille d'un élément spécifique :
- #define NKEYS (sizeof keytab / sizeof(keytab[0]))
Cela a l'avantage de ne pas avoir besoin d'être modifié si le type change.
Un sizeof ne peut pas être utilisé dans une ligne #if, car le préprocesseur n'analyse pas les noms de type. Mais l'expression dans le #define n'est pas évaluée par le préprocesseur, donc le code ici est légal.
Passons maintenant à la fonction getword. Nous avons écrit un getword plus général que ce qui est nécessaire pour ce programme, mais il n'est pas compliqué. getword récupère le «mot» suivant de l'entrée, où un mot est soit une chaîne de caractères de lettres et de chiffres commençant par une lettre, soit un seul caractère non blanc. La valeur de la fonction est le premier caractère du mot, ou EOF pour fin de fichier, ou le caractère lui-même s'il n'est pas alphabétique.
- /* getword: Demande le mot ou le caractère suivant à partir de l'entrée */
- int getword(char *word, int lim) {
- int c, getch(void);
- void ungetch(int);
- char *w = word;
- while (isspace(c = getch()))
- ;
- if (c != EOF) *w++ = c;
- if (!isalpha(c)) {
- *w = '\0';
- return c;
- }
- for ( ; --lim > 0; w++) if (!isalnum(*w = getch())) {
- ungetch(*w);
- break;
- }
- *w = '\0';
- return word[0];
- }
getword utilise les fonctions getch et ungetch que nous avons décrites à la page Fonctions et structure du programme. Lorsque la collecte d'un jeton alphanumérique s'arrête, getword a dépassé d'un caractère. L'appel à ungetch renvoie ce caractère sur l'entrée pour le prochain appel. getword utilise également isspace pour ignorer les espaces, isalpha pour identifier les lettres et isalnum pour identifier les lettres et les chiffres ; tous proviennent de l'entête standard <ctype.h>.
Pointeurs vers des structures
Pour illustrer certaines des considérations impliquées dans les pointeurs vers des structures et des tableaux de structures, écrivons à nouveau le programme de comptage de mots-clefs, cette fois en utilisant des pointeurs au lieu d'indices de tableau.
La déclaration externe de keytab n'a pas besoin d'être modifiée, mais main et binsearch doivent être modifiés.
- #include <stdio.h>
- #include <ctype.h>
- #include <string.h>
-
- #define MAXWORD 100
-
- int getword(char *, int);
- struct key *binsearch(char *, struct key *, int);
-
- /* compter les mots-clefs C ; version du pointeur */
- main() {
- char word[MAXWORD];
- struct key *p;
- while (getword(word, MAXWORD) != EOF) if (isalpha(word[0])) if ((p=binsearch(word, keytab, NKEYS)) != NULL) p->count++;
- for (p = keytab; p < keytab + NKEYS; p++) if (p->count > 0) printf("%4d %s\n", p->count, p->word);
- return 0;
- }
-
- /* binsearch: trouver le mot dans tab[0]...tab[n-1] */
- struct key *binsearch(char *word, struck key *tab, int n) {
- int cond;
- struct key *low = &tab[0];
- struct key *high = &tab[n];
- struct key *mid;
- while (low < high) {
- mid = low + (high-low) / 2;
- if ((cond = strcmp(word, mid->word)) < 0) high = mid; else
- if (cond > 0) low = mid + 1;
- else return mid;
- }
- return NULL;
- }
Plusieurs points méritent d'être soulignés ici. Tout d'abord, la déclaration de binsearch doit indiquer qu'elle renvoie un pointeur vers la structure key au lieu d'un entier ; ceci est déclaré à la fois dans le prototype de fonction et dans binsearch. Si binsearch trouve le mot, il renvoie un pointeur vers celui-ci ; s'il échoue, il renvoie NULL.
Deuxièmement, les éléments de keytab sont désormais accessibles par des pointeurs. Cela nécessite des changements importants dans binsearch.
Les initialiseurs pour low et high sont désormais des pointeurs vers le début et juste après la fin de la table.
Le calcul de l'élément du milieu ne peut plus être simplement :
- mid = (low+high) / 2 /* MAUVAIS */
car l'addition de pointeurs est illégale. La soustraction est légale, cependant, le nombre d'éléments est donc très faible, et donc :
- mid = low + (high-low) / 2
définit mid sur l'élément à mi-chemin entre low et high.
Le changement le plus important consiste à ajuster l'algorithme pour s'assurer qu'il ne génère pas de pointeur illégal ou ne tente pas d'accéder à un élément en dehors du tableau. Le problème est que &tab[-1] et &tab[n] sont tous deux en dehors des limites du tableau tab. Le premier est strictement illégal, et il est illégal de déréférencer le second. La définition du langage garantit cependant que l'arithmétique du pointeur qui implique le premier élément au-delà de la fin d'un tableau (c'est-à-dire &tab[n]) fonctionnera correctement.
Dans main, nous avons écrit :
- for (p = keytab; p < keytab + NKEYS; p++)
Si p est un pointeur vers une structure, l'arithmétique sur p prend en compte la taille de la structure, donc p++ incrémente p de la quantité correcte pour obtenir l'élément suivant du tableau de structures, et le test arrête la boucle au bon moment.
Ne supposez pas, cependant, que la taille d'une structure est la somme des tailles de ses membres. En raison des exigences d'alignement pour différents objets, il peut y avoir des «trous» sans nom dans une structure. Ainsi, par exemple, si un char est un octet et un int quatre octets, la structure :
pourrait bien nécessiter huit octets, pas cinq. L'opérateur sizeof renvoie la valeur appropriée. Enfin, un aparté sur le format du programme : lorsqu'une fonction renvoie un type compliqué comme un pointeur de structure, comme dans :
le nom de la fonction peut être difficile à voir et à trouver avec un éditeur de texte. Par conséquent, un style alternatif est parfois utilisé :
C'est une question de goût personnel ; choisissez la forme vous plaisant et tenez-vous-y.
Structures autoréférentielles
Supposons que nous souhaitons traiter le problème plus général du comptage des occurrences de tous les mots dans une entrée. Comme la liste des mots n'est pas connue à l'avance, nous ne pouvons pas la trier facilement et utiliser une recherche binaire. Mais nous ne pouvons pas faire une recherche linéaire pour chaque mot au fur et à mesure qu'il arrive, pour voir s'il a déjà été vu ; le programme prendrait trop de temps. (Plus précisément, son temps d'exécution est susceptible d'augmenter de manière quadratique avec le nombre de mots d'entrée.) Comment pouvons-nous organiser les données pour les copier efficacement avec une liste ou des mots arbitraires ?
Une solution consiste à conserver l'ensemble des mots vus jusqu'à présent triés à tout moment, en plaçant chaque mot à sa position appropriée dans l'ordre au fur et à mesure de son arrivée. Cela ne doit cependant pas être fait en décalant les mots dans un tableau linéaire, car cela prend également trop de temps. Nous utiliserons plutôt une structure de données appelée arbre binaire.
L'arbre contient un «noeud» par mot distinct ; chaque noeud contient :
- Un pointeur vers le texte du mot,
- Un décompte du nombre d'occurrences,
- Un pointeur vers le noud enfant gauche,
- Un pointeur vers le noud enfant droit
Aucun noeud ne peut avoir plus de deux enfants ; il peut n'en avoir qu'un ou zéro.
Les noeuds sont maintenus de telle sorte qu'à chaque noud, le sous-arbre de gauche ne contienne que des mots étant lexicographiquement inférieurs au mot du noeud, et le sous-arbre de droite ne contienne que des mots étant supérieurs. Voici l'arbre de la phrase «il est maintenant temps pour tous les hommes de bien de venir en aide à leur parti », tel que construit en insérant chaque mot au fur et à mesure qu'il est rencontré :
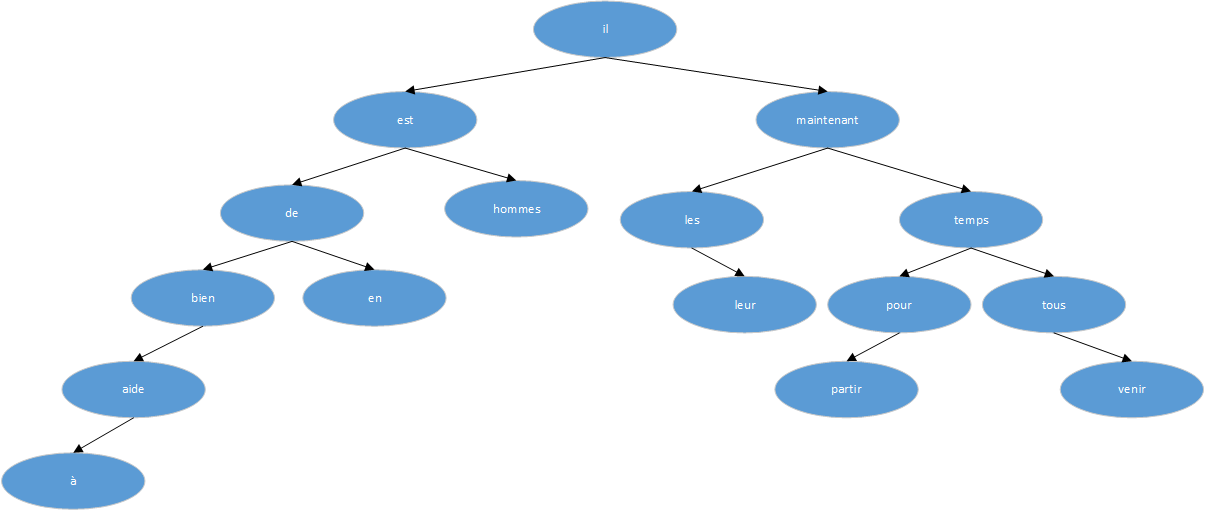
Pour savoir si un nouveau mot est déjà dans l'arbre, commencez à la racine et comparez le nouveau mot au mot entreposé dans ce noeud. S'ils correspondent, la réponse à la question est affirmative. Si le nouvel enregistrement est inférieur au mot de l'arbre, continuez la recherche sur l'enfant de gauche, sinon sur l'enfant de droite. S'il n'y a pas d'enfant dans la direction requise, le nouveau mot n'est pas dans l'arbre et en fait, l'emplacement vide est l'endroit approprié pour ajouter le nouveau mot. Ce processus est récursif, car la recherche à partir de n'importe quel noeud utilise une recherche à partir de l'un de ses enfants. En conséquence, les routines récursives pour l'insertion et l'impression seront les plus naturelles.
Pour revenir à la description d'un noeud, il est plus pratique de le représenter comme une structure à quatre composantes :
Cette déclaration récursive d'un noeud peut sembler hasardeuse, mais elle est correcte. Il est illégal pour une structure de contenir une instance d'elle-même, mais :
- struct tnode *left;
déclare left comme étant un pointeur vers un tnode, et non un tnode lui-même.
Parfois, on a besoin d'une variante de structures autoréférentielles : deux structures se référant l'une à l'autre. La façon de gérer cela est la suivante :
Le code de l'ensemble du programme est étonnamment petit, compte tenu d'une poignée de routines de support comme getword que nous avons déjà écrites. La routine principale lit les mots avec getword et les installe dans l'arbre avec addtree.
- #include <stdio.h>
- #include <ctype.h>
- #include <string.h>
-
- #define MAXWORD 100
- struct tnode *addtree(struct tnode *, char *);
- void treeprint(struct tnode *);
- int getword(char *, int);
-
- /* nombre de fréquences des mots */
- main() {
- struct tnode *root;
- char word[MAXWORD];
- root = NULL;
- while (getword(word, MAXWORD) != EOF) if (isalpha(word[0])) root = addtree(root, word);
- treeprint(root);
- return 0;
- }
La fonction addtree est récursive. Un mot est présenté par main au niveau supérieur (la racine) de l'arbre. À chaque étape, ce mot est comparé au mot déjà entreposé au niveau du noeud, et est transmis au sous-arbre gauche ou droit par un appel récursif à adtree. Finalement, le mot correspond à quelque chose se trouvant déjà dans l'arbre (auquel cas le compte est incrémenté), ou un pointeur nul est rencontré, indiquant qu'un noeud doit être créé et ajouté à l'arbre. Si un nouveau noeud est créé, addtree renvoie un pointeur vers celui-ci, qui est installé dans le noeud parent.
- struct tnode *talloc(void);
-
- char *strdup(char *);
-
- /* addtree: ajouter un noeud avec w, à ou en dessous de p */
- struct treenode *addtree(struct tnode *p, char *w) {
- int cond;
- if (p == NULL) { /* un nouveau mot est arrivé */
- p = talloc(); /* créer un nouveau noeud */
- p->word = strdup(w);
- p->count = 1;
- p->left = p->right = NULL;
- }
- else
- if ((cond = strcmp(w, p->word)) == 0) p->count++; else /* mot répété */
- if (cond < 0) p->left = addtree(p->left, w); /* moins que dans le sous-arbre de gauche */
- else /* supérieur à dans le sous-arbre de droite */
- p->right = addtree(p->right, w);
- return p;
- }
L'entreposage du nouveau noeud est récupéré par une routine talloc, renvoyant un pointeur vers un espace libre adapté pour contenir un noeud d'arbre, et le nouveau mot est copié dans un espace caché par strdup. (Nous discuterons de ces routines dans un instant.) Le compte est initialisé et les deux enfants sont rendus nuls. Cette partie du code n'est exécutée qu'aux feuilles de l'arbre, lorsqu'un nouveau noeud est ajouté. Nous avons (imprudemment) omis de vérifier les erreurs sur les valeurs renvoyées par strdup et talloc.
treeprint affiche l'arbre dans l'ordre trié ; à chaque noeud, il affiche le sous-arbre de gauche (tous les mots inférieurs à ce mot), puis le mot lui-même, puis le sous-arbre de droite (tous les mots supérieurs). Si vous ne savez pas comment fonctionne la récursivité, simulez treeprint tel qu'il fonctionne sur l'arbre présenté ci-dessus :
Remarque pratique : si l'arbre devient «déséquilibré» parce que les mots n'arrivent pas dans un ordre aléatoire, le temps d'exécution du programme peut devenir trop important. Dans le pire des cas, si les mots sont déjà dans l'ordre, ce programme effectue une simulation coûteuse de recherche linéaire. Il existe des généralisations de l'arbre binaire ne souffrant pas de ce comportement du pire des cas, mais nous ne les décrirons pas ici.
Avant de quitter cet exemple, il convient également de faire une brève digression sur un problème lié aux allocateurs d'entreposage. Il est clair qu'il n'y a qu'un seul allocateur d'entreposage dans un programme, même s'il alloue différents types d'objets. Mais si un allocateur doit traiter des requêtes pour, par exemple, des pointeurs vers des caractères et des pointeurs vers des structures tnodes, deux questions se posent. Tout d'abord, comment répond-il à l'exigence de la plupart des machines réelles selon laquelle les objets de certains types doivent satisfaire à des restrictions d'alignement (par exemple, les entiers doivent souvent être situés à des adresses paires) ? Deuxièmement, quelles déclarations peuvent gérer le fait qu'un allocateur doit nécessairement renvoyer différents types de pointeurs ?
Les exigences d'alignement peuvent généralement être satisfaites facilement, au prix d'un gaspillage d'espace, en s'assurant que l'allocateur renvoie toujours un pointeur respectant toutes les restrictions d'alignement. L'alloc de la page Pointeurs et tableaux ne garantit aucun alignement particulier, nous utiliserons donc la fonction de la bibliothèque standard malloc, le faisant. Dans la page L'interface système UNIX, nous montrerons une façon d'implémenter malloc.
La question de la déclaration de type pour une fonction comme malloc est une question délicate pour tout langage prenant au sérieux sa vérification de type. En C, la méthode appropriée consiste à déclarer que malloc renvoie un pointeur vers void, puis à forcer explicitement le pointeur dans le type souhaité avec un cast. malloc et les routines associées sont déclarées dans l'entête standard <stdlib.h>. Ainsi, talloc peut être écrit comme suit :
strdup copie simplement la chaîne donnée par son paramètre dans un endroit sûr, obtenu par un appel sur malloc :
malloc renvoie NULL si aucun espace n'est disponible ; strdup transmet cette valeur, laissant la gestion des erreurs à son appelant.
L'entreposage obtenu en appelant malloc peut être libéré pour réutilisation en appelant free ; voir les pages L'interface système UNIX et Entrée et sortie.
Recherche de table
Dans cette section, nous allons écrire les entrailles d'un paquet de recherche de table, pour illustrer plus d'aspects des structures. Ce code est typique de ce que l'on peut trouver dans les routines de gestion de table de symboles d'un processeur de macros ou d'un compilateur. Par exemple, considérez l'instruction #define. Lorsqu'une ligne comme :
- #define IN 1
est rencontré, le nom IN et le texte de remplacement 1 sont entreposés dans une table. Plus tard, lorsque le nom IN apparaît dans une instruction comme :
- state = IN;
il doit être remplacé par 1.
Il existe deux routines manipulant les noms et les textes de remplacement. install(s,t) enregistre le nom s et le texte de remplacement t dans une table ; s et t ne sont que des chaînes de caractères. lookup(s) recherche s dans la table et renvoie un pointeur vers l'endroit où il a été trouvé, ou NULL s'il n'était pas là.
L'algorithme est une recherche par hachage - le nom entrant est converti en un petit entier non négatif, étant ensuite utilisé pour indexer dans un tableau de pointeurs. Un élément de tableau pointe vers le début d'une liste chaînée de blocs décrivant les noms qui ont cette valeur de hachage. Il est NULL si aucun nom n'a été haché à cette valeur.
Un bloc dans la liste est une structure contenant des pointeurs vers le nom, le texte de remplacement et le bloc suivant dans la liste. Un pointeur suivant nul marque la fin de la liste.
Le tableau de pointeurs est simplement :
- #define HASHSIZE 101
-
- static struct nlist *hashtab[HASHSIZE]; /* tableau de pointeurs */
La fonction de hachage, utilisée à la fois par lookup et install, ajoute chaque valeur de caractère de la chaîne de caractères à une combinaison brouillée des valeurs précédentes et renvoie le reste modulo la taille du tableau. Ce n'est pas la meilleure fonction de hachage possible, mais elle est courte et efficace.
L'arithmétique non signée garantit que la valeur de hachage n'est pas négative.
Le processus de hachage produit un index de départ dans le tableau hashtab ; si la chaîne de caractères doit être trouvée n'importe où, elle sera dans la liste des blocs commençant à cet endroit. La recherche est effectuée par lookup. Si lookup trouve l'entrée déjà présente, elle renvoie un pointeur vers celle-ci ; sinon, elle renvoie NULL.
La boucle for dans la recherche est l'idiome standard pour parcourir une liste chaînée :
- for (ptr = head; ptr != NULL; ptr = ptr->next)
- ..
install utilise lookup pour déterminer si le nom en cours d'installation est déjà présent ; si c'est le cas, la nouvelle définition remplacera l'ancienne. Sinon, une nouvelle entrée est créée. install renvoie NULL si, pour une raison quelconque, il n'y a pas de place pour une nouvelle entrée :
- struct nlist *lookup(char *);
- char *strdup(char *);
-
- /* install: mettre (name, defn) dans le hashtab */
- struct nlist *install(char *name, char *defn) {
- struct nlist *np;
- unsigned hashval;
-
- if ((np = lookup(name)) == NULL) { /* non trouvé */
- np = (struct nlist *) malloc(sizeof(*np));
- if (np == NULL || (np->name = strdup(name)) == NULL) return NULL;
- hashval = hash(name);
- np->next = hashtab[hashval];
- hashtab[hashval] = np;
- }
- else /* déjà là */
- free((void *) np->defn); /* définition précédente libéré */
- if ((np->defn = strdup(defn)) == NULL) return NULL;
- return np;
- }
typedef
C fournit une fonction appelée typedef pour créer de nouveaux noms de types de données. Par exemple, la déclaration :
- typedef int Length;
fait du nom Length un synonyme de int. Le type Length peut être utilisé dans les déclarations, les conversions,..., exactement de la même manière que le type int :
- Length len, maxlen;
- Length *lengths[];
De même, la déclaration :
- typedef char *String;
fait de String un synonyme de char * ou de pointeur de caractère, pouvant ensuite être utilisé dans les déclarations et les conversions :
Notez que le type déclaré dans un typedef apparaît à la position d'un nom de variable, et non juste après le mot typedef. Syntaxiquement, typedef est comme les classes d'entreposage extern, static, ... Nous avons utilisé des noms en majuscules pour les typedef, afin de les faire ressortir.
Comme exemple plus compliqué, nous pourrions créer des typedef pour les noeuds d'arbre présentés plus tôt dans cette page :
Cela crée deux nouveaux mots-clefs de type appelés Treenode (une structure) et Treeptr (un pointeur vers la structure). La routine talloc pourrait alors devenir :
Il faut souligner qu'une déclaration de typedef ne crée en aucun cas un nouveau type ; elle ajoute simplement un nouveau nom à un type existant. Il n'y a pas non plus de nouvelle sémantique : les variables déclarées de cette manière ont exactement les mêmes propriétés que les variables dont les déclarations sont explicitement énoncées. En effet, typedef est comme #define, sauf que comme il est interprété par le compilateur, il peut gérer des substitutions textuelles dépassant les capacités du préprocesseur. Par exemple :
crée le type PFI, pour «pointeur vers une fonction (de deux paramètres char *) renvoyant int», pouvant être utilisé dans des contextes tels que :
- PFI strcmp, numcmp;
dans le programme de tri de la page Pointeurs et tableaux.
Outre les questions purement esthétiques, il existe deux raisons principales pour utiliser des typedef. La première est de paramétrer un programme contre les problèmes de portabilité. Si des typedef sont utilisés pour des types de données pouvant dépendre de la machine, seuls les typedef doivent changer lorsque le programme est déplacé. Une situation courante consiste à utiliser des noms de typedef pour différentes quantités entières, puis à créer un ensemble approprié de choix de short, int et long pour chaque machine hôte. Des types comme size_t et ptrdiff_t de la bibliothèque standard en sont des exemples.
Le deuxième objectif des typedef est de fournir une meilleure documentation pour un programme - un type appelé Treeptr peut être plus facile à comprendre qu'un type déclaré uniquement comme un pointeur vers une structure compliquée.
Unions
Une union est une variable pouvant contenir (à différents moments) des objets de différents types et tailles, le compilateur gardant une trace des exigences de taille et d'alignement. Les unions permettent de manipuler différents types de données dans une seule zone d'entreposage, sans intégrer d'informations dépendantes de la machine dans le programme. Elles sont analogues aux enregistrements de variantes en Pascal.
À titre d'exemple, comme on pourrait en trouver dans un gestionnaire de table de symboles de compilateur, supposons qu'une constante puisse être un int, un float ou un pointeur de caractère. La valeur d'une constante particulière doit être stockée dans une variable du type approprié, mais il est plus pratique pour la gestion de table que la valeur occupe la même quantité d'entreposage et soit entreposée au même endroit quel que soit son type. C'est le but d'une union - une variable unique pouvant légitimement contenir l'un des nombreux types. La syntaxe est basée sur les structures :
La variable u sera suffisamment grande pour contenir le plus grand des trois types ; la taille spécifique dépend de l'implémentation. N'importe lequel de ces types peut être assigné à u puis utilisé dans des expressions, à condition que l'utilisation soit cohérente : le type récupéré doit être le type le plus récemment entreposé. Il est de la responsabilité du programmeur de garder une trace du type actuellement entreposé dans une union ; les résultats dépendent de l'implémentation si quelque chose est stocké sous un type et extrait sous un autre.
Syntaxiquement, les membres d'une union sont accessibles comme suit :
| union-name.member |
ou :
| union-pointer->member |
tout comme pour les structures. Si la variable utype est utilisée pour garder une trace du type actuel entreposé dans u, on peut alors voir du code tel que :
Les unions peuvent se produire dans des structures et des tableaux, et vice versa. La notation pour accéder à un membre d'une union dans une structure (ou vice versa) est identique à celle des structures imbriquées. Par exemple, dans le tableau de structures défini par :
le membre ival est appelé :
- symtab[i].u.ival
et le premier caractère de la chaîne de caractères sval par l'un des :
- *symtab[i].u.sval
- symtab[i].u.sval[0]
En effet, une union est une structure dans laquelle tous les membres ont un déplacement nul par rapport à la base, la structure est suffisamment grande pour contenir le membre «le plus large» et l'alignement est approprié pour tous les types de l'union. Les mêmes opérations sont autorisées sur les unions que sur les structures : affectation ou copie en tant qu'unité, prise de l'adresse et accès à un membre.
Une union ne peut être initialisée qu'avec une valeur du type de son premier membre ; ainsi, l'union u décrite ci-dessus ne peut être initialisée qu'avec une valeur entière.
L'allocateur d'entreposage du L'interface système UNIX montre comment une union peut être utilisée pour forcer une variable à s'aligner sur un type particulier de limite d'entreposage.
Champs de bits
Lorsque l'espace d'entreposage est limité, il peut être nécessaire de regrouper plusieurs objets dans un seul mot machine ; une utilisation courante est un ensemble d'indicateurs à un seul bit dans des applications telles que les tables de symboles de compilateur. Les formats de données imposés de l'extérieur, tels que les interfaces vers des périphériques matériels, nécessitent également souvent la capacité d'accéder à des morceaux d'un mot.
Imaginez un fragment d'un compilateur qui manipule une table de symboles. Chaque identifiant d'un programme est associé à certaines informations, par exemple, s'il s'agit ou non d'un mot-clef, s'il est ou non externe et/ou statique,... La manière la plus compacte de coder ces informations est un ensemble d'indicateurs à un bit dans un seul char ou int.
La manière habituelle de procéder consiste à définir un ensemble de «masques» correspondant aux positions de bits pertinentes, comme dans :
- #define KEYWORD 01
- #define EXTERNAL 02
- #define STATIC 04
ou :
- enum { KEYWORD = 01, EXTERNAL = 02, STATIC = 04 };
Les nombres doivent être des puissances de deux. L'accès aux bits devient alors une question de «bidouillage de bits» avec les opérateurs de décalage, de masquage et de complémentation décrits dans la page Types, opérateurs et expressions.
Certaines expressions idiomatiques apparaissent fréquemment :
- flags |= EXTERNAL | STATIC;
active les bits EXTERNAL et STATIC dans les indicateurs, tandis que :
- flags &= ~(EXTERNAL | STATIC);
les éteint et :
- if ((flags & (EXTERNAL | STATIC)) == 0) ...
est vrai si les deux bits sont désactivés.
Bien que ces idiomes soient facilement maîtrisés, le C offre comme alternative la possibilité de définir et d'accéder directement aux champs d'un mot plutôt que par des opérateurs logiques au niveau du bit. Un champ de bits, ou champ en abrégé, est un ensemble de bits adjacents dans une seule unité d'entreposage définie par l'implémentation que nous appellerons un «mot». Par exemple, la table de symboles #defines ci-dessus pourrait être remplacée par la définition de trois champs :
Cela définit une table de variables appelée flags contenant trois champs de 1 bit. Le nombre suivant les deux points représente la largeur du champ en bits. Les champs sont déclarés unsigned int pour garantir qu'ils sont des quantités non signées.
Les champs individuels sont référencés de la même manière que les autres membres de la structure : flags.is_keyword, flags.is_extern,... Les champs se comportent comme de petits entiers et peuvent participer à des expressions arithmétiques comme d'autres entiers. Ainsi, les exemples précédents peuvent être écrits plus naturellement comme :
- flags.is_extern = flags.is_static = 1;
pour activer les bits :
- flags.is_extern = flags.is_static = 0;
pour les désactiver ; et :
- if (flags.is_extern == 0 && flags.is_static == 0)
- ...
pour les tester.
Presque tout ce qui concerne les champs dépend de l'implémentation. Le fait qu'un champ puisse chevaucher une limite de mot est défini par l'implémentation. Les champs n'ont pas besoin d'être des noms ; les champs sans nom (un deux-points et une largeur uniquement) sont utilisés pour le remplissage. La largeur spéciale 0 peut être utilisée pour forcer l'alignement à la limite de mot suivante.
Les champs sont attribués de gauche à droite sur certaines machines et de droite à gauche sur d'autres. Cela signifie que bien que les champs soient utiles pour maintenir des structures de données définies en interne, la question de savoir quelle extrémité vient en premier doit être soigneusement considérée lors de l'analyse des données définies en externe ; les programmes qui dépendent de telles choses ne sont pas portables. Les champs ne peuvent être déclarés que comme des entiers ; pour la portabilité, spécifiez explicitement signé ou non signé. Ce ne sont pas des tableaux et ils n'ont pas d'adresses, donc l'opérateur & ne peut pas leur être appliqué.