
CONTAINS |
Contenu |
|---|---|
| SQL Server | Microsoft SQL Server |
Syntaxe
|
CONTAINS(( { column_name | (column_list) | * | PROPERTY ({ column_name }, 'property_name')} , 'contains_search_condition' [ , LANGUAGE language_term ] ) contains_search_condition ::= { simple_term | prefix_term | generation_term | proximity_term | weighted_term } | { ( contains_search_condition ) [ { AND | AND NOT | OR } ] contains_search_condition [ ...n ] } simple_term ::= word | " phrase " prefix term ::= { "word * " | "phrase *" } generation_term ::= FORMSOF ( { INFLECTIONAL | THESAURUS } , simple_term [ ,...n ] ) generic_proximity_term ::= { simple_term | prefix_term } { { { NEAR | ~ } { simple_term | prefix_term } } [ ...n ] } custom_proximity_term ::= NEAR ( { { simple_term | prefix_term } [ ,...n ] | ( { simple_term | prefix_term } [ ,...n ] ) [, maximum_distance [, match_order ] ] } ) maximum_distance ::= { integer | MAX } match_order ::= { TRUE | FALSE } weighted_term ::= ISABOUT ( { { simple_term | prefix_term | generation_term | proximity_term } [ WEIGHT ( weight_value ) ] } [ ,...n ] ) AND ::= { AND | & } AND NOT ::= { AND NOT | & !} OR ::= { OR | | }) |
Paramètres
| Nom | Description | |
|---|---|---|
| column_name | Ce paramètre permet d'indiquer le nom d'une colonne indexée en texte intégral de la table spécifiée dans la clause FROM. Les colonnes peuvent être de type char, varchar, nchar, nvarchar, text, ntext, image, xml, varbinary ou varbinary(max). | |
| column_list | Ce paramètre permet d'indiquer deux colonnes ou plus, séparées par des virgules. Le paramètre column_list doit être entre parenthèses. À moins que le paramètre language_term ne soit spécifié, la langue de toutes les colonnes de column_list doit être la même. | |
| * | Ce paramètre permet d'indiquer que la requête recherche toutes les colonnes indexées en texte intégral dans la table spécifiée dans la clause FROM pour la condition de recherche donnée. Les colonnes de la clause CONTAINS doivent provenir d'une seule table comportant un index de recherche en texte intégral. À moins que language_term ne soit spécifié, la langue de toutes les colonnes de la table doit être la même. | |
| PROPERTY(column_name,'property_name') | Ce paramètre permet d'indiquer une propriété de document sur laquelle rechercher la condition de recherche spécifiée. S'applique à : SQL Server 2012 (11.x) et versions ultérieures. Pour que la requête renvoie des lignes, property_name doit être spécifié dans la liste des propriétés de recherche de l'index de texte intégral et l'index de texte intégral doit contenir des entrées spécifiques à la propriété pour property_name. | |
| LANGUAGE language_term | Ce paramètre permet d'indiquer la langue à utiliser pour la césure des mots, la radicalisation, les extensions et les remplacements de thésaurus, et la suppression des mots parasites (ou les mots vides) dans le cadre de la requête. Ce paramètre est facultatif. Si des documents de langues différentes sont entreposés ensemble sous forme d'objets binaires volumineux (BLOB) dans une seule colonne, l'identificateur de paramètres régionaux (LCID) d'un document donné détermine la langue à utiliser pour indexer son contenu. Lors de l'interrogation d'une telle colonne, la spécification de «LANGUAGE language_term» peut augmenter la probabilité d'une bonne correspondance. Le paramètre language_term peut être spécifié sous la forme d'une chaîne de caractères, d'un entier ou d'une valeur hexadécimale correspondant au LCID d'une langue. Si language_term est spécifié, la langue qu'il représente est appliquée à tous les éléments de la condition de recherche. Si aucune valeur n'est spécifiée, la langue de texte intégral de la colonne est utilisée. Lorsqu'il est spécifié sous forme de chaîne de caractères, language_term correspond à la valeur de la colonne d'alias dans la vue de compatibilité sys.syslanguages (Transact-SQL). La chaîne de caractères doit être entourée de guillemets simples, comme dans 'language_term'. Lorsqu'il est spécifié sous forme d'entier, language_term est le LCID actuel identifiant la langue. Lorsqu'il est spécifié sous forme de valeur hexadécimale, language_term est 0x suivi de la valeur hexadécimale du LCID. La valeur hexadécimale ne doit pas dépasser 8 chiffres, y compris les zéros non significatifs. Si la valeur est au format d'ensemble de caractères codés sur deux octets (DBCS), le SQL Server la convertit en Unicode. Si la langue spécifiée n'est pas valide ou si aucune ressource installée ne correspond à cette langue, SQL Server renvoie une erreur. Pour utiliser les ressources de langage neutre, spécifiez 0x0 comme language_term. | |
| contains_search_condition | Ce paramètre permet d'indiquer le texte à rechercher dans column_name et les conditions de correspondance. Le paramètre contains_search_condition est nvarchar. Une conversion implicite se produit lorsqu'un autre type de données caractère est utilisé comme entrée. Les types de données de chaîne volumineux nvarchar(max) et varchar(max) ne peuvent pas être utilisés. Dans l'exemple suivant, la variable @SearchWord, étant définie comme varchar(30), provoque une conversion implicite dans le prédicat CONTAINS. | |
| word | Ce paramètre permet d'indiquer une chaîne de caractères sans espaces ni ponctuation. | |
| phrase | Ce paramètre permet d'indiquer un ou plusieurs mots avec des espaces entre chaque mot. | |
| simple_term | Ce paramètre permet d'indiquer une correspondance pour un mot exact ou une expression. Des exemples de termes simples valides sont «blue berry», blueberry et «Microsoft SQL Server». Les phrases doivent être placées entre guillemets doubles (""). Les mots d'une phrase doivent apparaître dans le même ordre que celui spécifié dans contains_search_condition tel qu'ils apparaissent dans la colonne de la base de données. La recherche de caractères dans le mot ou la phrase n'est pas sensible à la casse. Les mots parasites (ou mots vides) (tels que a, et, ou le) dans les colonnes indexées de texte intégral ne sont pas entreposés dans l'index de texte intégral. Si un mot parasite est utilisé dans une recherche par mot unique, SQL Server renvoie un message d'erreur indiquant que la requête ne contient que des mots parasites. Le SQL Server inclut une liste standard de mots parasites dans le répertoire \Mssql\Binn\FTERef de chaque instance de SQL Server. La ponctuation est ignorée. Par conséquent, CONTAINS(testing, "computer failure") correspond à une ligne avec la valeur "Where is my computer? Failure to find it would be expensive.". | |
| prefix_term | Ce paramètre permet d'indiquer une correspondance de mots ou d'expressions commençant par le texte spécifié. Placez un préfixe entre guillemets doubles ("") et ajoutez un astérisque (*) avant le guillemet de fin, de sorte que tout le texte commençant par le terme simple spécifié avant l'astérisque corresponde. La clause doit être spécifiée de la manière suivante : CONTAINS(column, '"text*"'). L'astérisque correspond à zéro, un ou plusieurs caractères (du mot racine ou des mots du mot ou de la phrase). Si le texte et l'astérisque ne sont pas délimités par des guillemets doubles, de sorte que le prédicat indique CONTAINS(column, 'text*'), la recherche de texte intégral considère l'astérisque comme un caractère et recherche les correspondances exactes avec text*. Le moteur de texte intégral ne trouvera pas les mots avec le caractère astérisque (*) car les séparateurs de mots ignorent généralement ces caractères. Lorsque prefix_term est une expression, chaque mot contenu dans l'expression est considéré comme un préfixe distinct. Par conséquent, une requête spécifiant un préfixe "local wine*" correspond à toutes les lignes avec le texte "local winery", "locally wined and dined",... | |
| generation_term | Ce paramètre permet d'indiquer une correspondance de mots lorsque les termes simples inclus incluent des variantes du mot d'origine à rechercher. | |
| INFLECTIONAL | Ce paramètre permet d'indiquer que le stemmer dépendant de la langue doit être utilisé sur le terme simple spécifié. Le comportement de Stemmer est défini en fonction des règles de radicalisation de chaque langue spécifique. La langue neutre n'a pas de stemmer associé. Le langage de colonne des colonnes interrogées est utilisé pour faire référence au stemmer souhaité. Si language_term est spécifié, le stemmer correspondant à cette langue est utilisé. Un simple_term donné dans un generation_term ne correspondra pas à la fois aux noms et aux verbes. | |
| THESAURUS | Ce paramètre permet d'indiquer que le thésaurus correspondant à la langue de texte intégral de la colonne ou la langue spécifiée dans la requête est utilisé. Le ou les modèles les plus longs du simple_term sont mis en correspondance avec le thésaurus et des termes supplémentaires sont générés pour développer ou remplacer le modèle d'origine. Si aucune correspondance n'est trouvée pour tout ou partie du simple_term, la partie non correspondante est traitée comme un simple_term. | |
| generic_proximity_term | Ce paramètre permet d'indiquer une correspondance de mots ou d'expressions devant figurer dans le document recherché. Cette fonctionnalité sera supprimée dans une future version de SQL Server. Évitez d'utiliser cette fonctionnalité dans de nouveaux travaux de développement et prévoyez de modifier les applications utilisant actuellement cette fonctionnalité. Il est recommandez d'utiliser custom_proximity_term. | |
| NEAR | ~ | Ce paramètre permet d'indiquer que le mot ou la phrase de chaque côté de l'opérateur NEAR ou ~ doit apparaître dans un document pour qu'une correspondance soit renvoyée. Vous devez spécifier deux termes de recherche. Un terme de recherche donné peut être soit un mot unique, soit une phrase délimitée par des guillemets doubles ("phrase"). Plusieurs termes de proximité peuvent être chaînés, comme dans «a NEAR b NEAR c or a ~ b ~ c». Les termes de proximité chaînés doivent tous figurer dans le document pour qu'une correspondance soit renvoyée. Par exemple, «CONTAINS(*column_name*, 'fox NEAR chicken')» et «CONTAINSTABLE(*table_name*, *column_name*, 'fox ~ chicken')» renvoient tous les documents dans la colonne spécifiée contenant à la fois "fox" et "chicken". De plus, CONTAINSTABLE renvoie un rang pour chaque document en fonction de la proximité de "fox" et "chicken". Par exemple, si un document contient la phrase "The fox ate the chicken,", son classement sera élevé car les termes sont plus proches les uns des autres que dans d'autres documents. | |
| custom_proximity_term | Ce paramètre permet d'indiquer une correspondance de mots ou d'expressions, et éventuellement, la distance maximale autorisée entre les termes de recherche. Ce paramètre custom_proximity_term s'applique à SQL Server 2012 (11.x) et versions ultérieures. Vous pouvez également spécifier que les termes de recherche doivent être trouvés dans l'ordre exact dans lequel vous les spécifiez (match_order). Un terme de recherche donné peut être soit un mot unique, soit une phrase délimitée par des guillemets doubles ("phrase"). Chaque terme spécifié doit figurer dans le document pour qu'une correspondance soit renvoyée. Vous devez spécifier au moins deux termes de recherche. Le nombre maximum de termes de recherche est de 64. Par défaut, le terme de proximité personnalisé renvoie toutes les lignes contenant les termes spécifiés, quelle que soit la distance intermédiaire et quel que soit leur ordre. | |
| maximum_distance | Ce paramètre permet d'indiquer la distance maximale autorisée entre les termes de recherche au début et à la fin d'une chaîne de caractères pour que cette chaîne soit considérée comme une correspondance. | |
| integer | Ce paramètre permet d'indiquer un entier positif compris entre 0 et 4294967295. Cette valeur contrôle le nombre de termes non liés à la recherche pouvant apparaître entre le premier et le dernier terme de recherche, à l'exclusion de tout terme de recherche spécifié supplémentaire. | |
| MAX | Ce paramètre permet de retourner toutes les lignes contenant les termes spécifiés, quelle que soit la distance les séparant. C'est la valeur par défaut. | |
| match_order | Ce paramètre permet d'indiquer si les termes doivent apparaître dans l'ordre spécifié pour être renvoyés par une requête de recherche. Pour spécifier match_order, vous devez également spécifier maximum_distance. Le paramètre match_order prend l'une des valeurs suivantes : | |
| Valeur | Description | |
| TRUE | Ce paramètre permet d'appliquer l'ordre spécifié dans les termes. Par exemple, NEAR(A,B) ne correspondrait qu'à A ... B. | |
| FALSE | Ce paramètre permet d'ignorer l'ordre spécifié. Par exemple, NEAR(A,B) correspondrait à la fois à A ... B et B ... A. C'est la valeur par défaut. | |
| weighted_term | Ce paramètre permet d'indiquer que les lignes correspondantes (renvoyées par la requête) correspondent à une liste de mots et d'expressions, chacun ayant éventuellement une valeur de pondération. | |
| ISABOUT | Ce paramètre permet d'indiquer le mot clef weighted_term. | |
| WEIGHT(weight_value) | Ce paramètre permet d'indiquer une valeur de pondération, étant un nombre compris entre 0,0 et 1,0. Chaque composante de weighted_term peut inclure un weight_value. Le paramètre weight_value est un moyen de modifier la façon dont diverses parties d'une requête affectent la valeur de classement attribuée à chaque ligne correspondant à la requête. WEIGHT n'affecte pas les résultats des requêtes CONTAINS, mais WEIGHT a un impact sur le classement dans les requêtes CONTAINSTABLE. | |
| { AND | & } | { AND NOT | &! } | { OR | | } | Ce paramètre permet d'indiquer une opération logique entre deux contient des conditions de recherche. | |
| { AND | & } | Ce paramètre permet d'indiquer que les deux conditions de recherche contient doivent être remplies pour une correspondance. Le symbole esperluette (&) peut être utilisé à la place du mot clef AND pour représenter l'opérateur AND. | |
| { AND NOT | &! } | Ce paramètre permet d'indiquer que la deuxième condition de recherche ne doit pas être présente pour une correspondance. L'esperluette suivie du symbole de point d'exclamation (&!) peut être utilisée à la place du mot clef AND NOT pour représenter l'opérateur AND NOT. | |
| { OR | | } | Ce paramètre permet d'indiquer que l'une des deux conditions de recherche contient doit être remplie pour une correspondance. Le symbole de la barre (|) peut être utilisé à la place du mot clef OR pour représenter l'opérateur OR. Lorsque contains_search_condition contient des groupes entre parenthèses, ces groupes entre parenthèses sont évalués en premier. Après avoir évalué les groupes entre parenthèses, ces règles s'appliquent lors de l'utilisation de ces opérateurs logiques avec des conditions de recherche contient : NOT est appliqué avant AND. NOT ne peut se produire qu'après AND, comme dans AND NOT. L'opérateur OR NOT n'est pas autorisé. NOT ne peut pas être spécifié avant le premier terme. Par exemple, CONTAINS (mycolumn, 'NOT "phrase_to_search_for" ' ) n'est pas valide. AND est appliqué avant OR. Les opérateurs booléens de même type (AND, OR) sont associatifs et peuvent donc être appliqués dans n'importe quel ordre. | |
| n | Ce paramètre permet d'indiquer un espace réservé spécifiant que plusieurs conditions de recherche CONTAINS et les termes qu'elles contiennent. | |
Description
Cette fonction permet d'effectuer des recherches dans certaines colonnes de chaîne de caractères.
Remarques
- Pour pouvoir utiliser CONTAINS, assurez-vous d'avoir installé Full-Text Search dans les Features Selection de SQL Server :
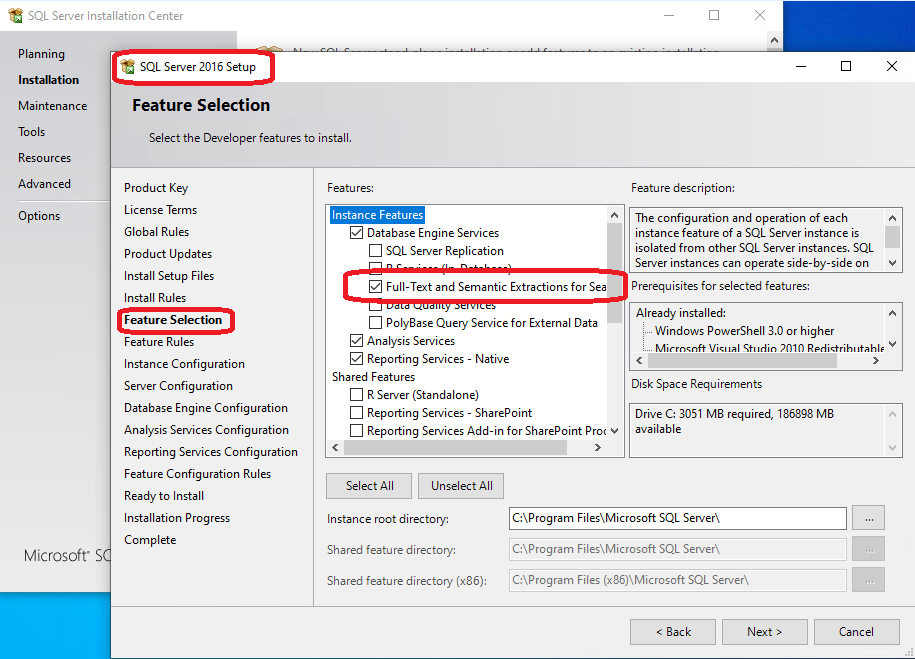
Ensuite, créer un catalogue s'il n'existe pas avec une requête ressemblant à ceci :
- USE [DatabaseName];
- CREATE FULLTEXT CATALOG FullTextCatalog AS DEFAULT;
Créer l'index en vous assurez-vous que : vous n'avez pas déjà d'index de recherche de texte intégral sur la table car un seul index de recherche de texte intégral est autorisé sur une table, un index unique existe sur la table (l'index doit être basé sur une colonne à clef unique, n'autorisant pas NULL), un catalogue en texte intégral existe (vous devez spécifier explicitement le nom du catalogue de texte intégral s'il n'y a pas de catalogue de texte intégral par défaut). Sinon, vous aurez une erreur dans le style :
Cannot use a CONTAINS or FREETEXT predicate on table or indexed view 'matable' because it is not full-text indexed. - Vous pouvez utiliser un nom en quatre parties dans le prédicat CONTAINS ou FREETEXT pour interroger les colonnes indexées de texte intégral des tables cible sur un serveur lié. Pour préparer un serveur distant à recevoir des requêtes de texte intégral, créez un index de texte intégral sur les tables et colonnes cibles sur le serveur à distance, puis ajoutez le serveur à distance en tant que serveur lié.
- Contrairement à la recherche en texte intégral, le prédicat LIKE de Transact-SQL fonctionne uniquement sur les modèles de caractères. De plus, vous ne pouvez pas utiliser le prédicat LIKE pour interroger des données binaires formatées. De plus, une requête LIKE sur une grande quantité de données textuelles non structurées est beaucoup plus lente qu'une requête en texte intégral équivalente sur les mêmes données. Une requête LIKE sur des millions de lignes de données textuelles peut prendre quelques minutes pour être renvoyée ; alors qu'une requête en texte intégral peut prendre seulement quelques secondes ou moins sur les mêmes données, selon le nombre de lignes renvoyées et leur taille. Une autre considération est que LIKE n'effectue qu'un simple balayage de modèle d'une table entière. Une requête de texte intégral, en revanche, est sensible à la langue, appliquant des transformations spécifiques au moment de l'index et de la requête, telles que le filtrage des mots vides et la création de thésaurus et d'expansions flexionnelles. Ces transformations aident les requêtes en texte intégral à améliorer leur rappel et le classement final de leurs résultats.
- Les prédicats et les fonctions de texte intégral fonctionnent sur une seule table, ce qui est implicite dans le prédicat FROM. Pour effectuer une recherche sur plusieurs tables, utilisez une table jointe dans votre clause FROM pour effectuer une recherche sur un ensemble de résultats étant le produit de deux tables ou plus.
- Les prédicats de texte intégral ne sont pas autorisés dans la clause OUTPUT lorsque le niveau de compatibilité de la base de données est défini sur 100.
- Le prédicat CONTAINS ne peut fonctionner que si l'indexation de texte intégral (Full-Text Indexing) est appliquée au magasin recherché. Les mots courants, tels que «et», «est», «mais» et «le», également appelés mots parasites, sont ignorés dans une recherche.
- Seuls les éléments avec la séquence exacte sont mis en correspondance, par exemple "Meilleurs saisons".
- A partir de SQL Server 2016, la vue système sys.database_scoped_configurations prend en charge de nombreux paramètres pouvant influencé le Full-Text Search.
Voir également
Articles - Les géants de l'informatique - Microsoft