Comment fonctionne Heroku
En 2013, Heroku avait déployé plus de trois millions d'applications distinctes sur son infrastructure, et ce nombre augmente de jour en jour. L'exécution d'un grand nombre d'applications au jour le jour nécessite une approche sensiblement différente de l'exécution d'une poignée, et c'est l'une des raisons pour lesquelles l'architecture Heroku est nettement différente de ce que vous ou moi pourrions développer si nous configurions notre propre environnement sur notre propre matériel pour une seule application. La tâche d'Heroku est de prendre en charge l'exécution de toutes ces applications en même temps, de gérer les déploiements demandés par les utilisateurs, ainsi que de faire évoluer les besoins des applications.
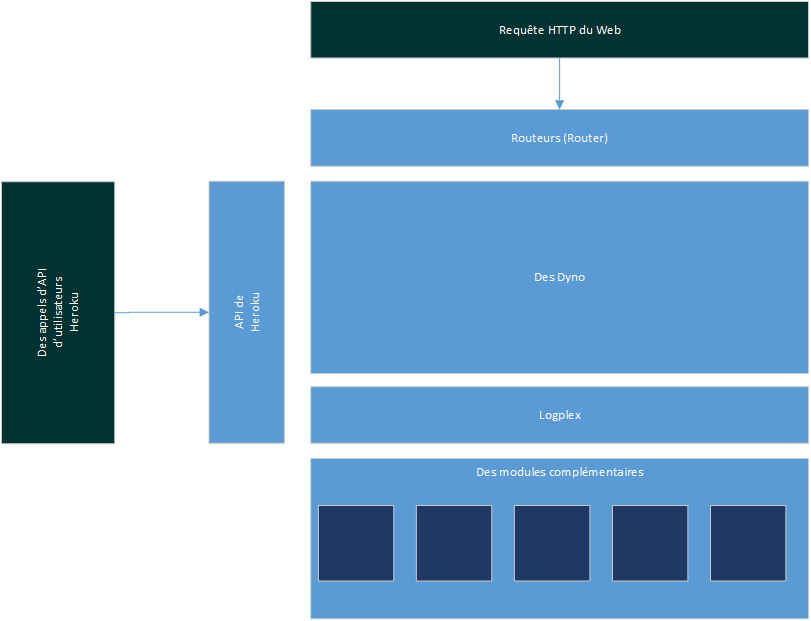
Pour y parvenir, la plate-forme Heroku est divisée en plusieurs segments clefs ; les plus importants parmi ceux-ci sont :
- Router, garantissant que votre application reçoit les requêtes des utilisateurs sur le Web.
- Dyno, où votre code d'application s'exécute réellement au jour le jour.
En plus de ceux-ci, il existe un certain nombre de composantes supplémentaires, tels que le Logplex et les divers modules complémentaires et services disponibles pour vos applications :
Qu'est-ce qu'un Dyno ?
Lorsque vous déployez une application sur Heroku, elle est exécutée dans un conteneur appelé Dyno. Plus votre application possède de Dynos, plus il y a d'instances en cours d'exécution de votre application disponibles pour prendre des demandes. Chaque Dyno est complètement isolé des autres Dynos. Vous pouvez ajouter des Dynos pour étendre la capacité et permettre la tolérance aux pannes (puisqu'un Dyno tombant en panne n'affectera pas les autres Dynos). A l'origine, chaque Dyno représentait 512 Mo de RAM physique.
Les applications sont facturées au Dyno/heure au prorata de la seconde, et chaque application est créditée de 750 Dyno/heures par mois. La mise en garde ici est que Heroku inactive toutes les applications exécutant un seul Dyno lorsqu'il n'est pas utilisé pour libérer des ressources pour d'autres applications.
Ainsi, un Dyno est comme un petit ordinateur virtuel, mais si votre application est répartie sur plusieurs unités de calcul, comment Heroku sait-il à quels Dynos envoyer des requêtes ? Avec le routage HTTP.
Routage HTTP
Lorsqu'un utilisateur tape l'URL de votre application dans un navigateur ou tente de lui faire une demande via une API (et ainsi de suite), il doit y avoir un moyen de connecter l'utilisateur à votre application exécutée quelque part au plus profond de la plate-forme Heroku. Des milliers d'applications s'exécutent sur Heroku, et le maintien d'un emplacement permanent pour une application au sein de la plate-forme est une approche semée d'embûches.
Le routeur Heroku est un logiciel (écrit en Erlang, appelé Hermes), agissant comme une passerelle entre vos utilisateurs et les Dynos exécutant votre code. Dans sa mémoire, il connaît chaque application actuellement déployée sur la plate-forme et les URL externes auxquelles chacune de ces applications doit répondre (y compris les URL *.herokuapp.com, les URL héritées *.heroku.com et tous les domaines personnalisés que vous avez peut-être ajouté). Enfin, il entrepose l'emplacement actuel de votre application sur la plate-forme à l'heure actuelle.
Cycle de vie de la demande
Lorsqu'un utilisateur souhaite visiter votre site, il tape l'URL dans la barre d'adresse et appuie sur Entrée. Ensuite, une requête DNS est faite à votre fournisseur. Ils voient que vous avez indiqué votre adresse à Heroku en utilisant un enregistrement A ou un CNAME. Avec ces informations, la requête est envoyée aux routeurs Heroku.
Chaque fois qu'un routeur reçoit une requête, il effectue une recherche sur l'URL demandée et détermine l'emplacement de votre code d'application. Une fois trouvé, il déclenche la requête sur votre code et attend une réponse. C'est là que votre application intervient et gère la demande, en faisant tout ce que vous lui avez programmé.
Une fois que votre code a terminé de traiter la demande et qu'une réponse a été renvoyée, le routeur transmettra la réponse à l'utilisateur final. La meilleure partie à ce sujet est que les routeurs sont complètement transparents pour le monde extérieur.
Requêtes de longue durée
Afin de protéger l'utilisateur contre les demandes de longue durée, le routeur traitant la demande n'attendra que 30 secondes avant de renvoyer une erreur de délai d'attente à l'utilisateur final. L'erreur renvoyée dans ces instances s'affiche dans vos journaux d'application sous la forme d'un H12. Notez, cependant, que cela ne compte que le premier octet renvoyé. Une fois que ce premier octet de réponse est renvoyé, le routeur définit une fenêtre glissante de 55 secondes avant qu'une erreur ne soit renvoyée (dans ces cas, le code d'erreur se transforme en H15). Cela signifie donc que vous êtes effectivement en mesure de renvoyer les réponses à l'utilisateur sans vous soucier de rencontrer cette erreur de délai d'attente.
Le gestionnaire de Dyno et les Dynos
En termes simples, un Dyno est un conteneur UNIX isolé et virtualisé fournissant l'environnement requis pour exécuter une application.
Chaque Dyno exécuté sur la plate-forme exécutera un code d'application différent. Par exemple, s'il s'agissait d'une application Ruby on Rails, un Dyno pourrait exécuter une instance de Unicorn, alors que s'il s'agissait d'une application Java, vous pourriez voir Tomcat ou quelque chose de similaire. Dans cette gamme de Dynos, vous pouvez avoir potentiellement des milliers d'applications, chaque Dyno exécutant quelque chose de différent. Certaines applications s'exécutant à une échelle supérieure s'exécuteront sur plusieurs de ces Dynos, certaines ne s'exécuteront que sur un ou deux, mais l'élément clé à retenir ici est qu'une seule application peut être représentée n'importe où dans ce système.
Avant que votre code d'application ne soit associé à un Dyno, les Dynos sont tous identiques. Cette uniformité permet à Heroku de gérer facilement les milliers d'applications sur la plateforme. Lorsque vous envoyez votre code à Heroku, il est compilé dans un format connu en interne sous le nom de "slug" poovant ensuite être exécuté rapidement sur n'importe lequel des Dynos disponibles. Étant donné que Heroku gère un tel éventail de Dynos, il est inévitable que les performances d'un serveur sous-jacent ralentissent ou qu'une panne matérielle se produise. Heureusement, lorsque cela est détecté, les Dynos seront automatiquement arrêtés et redémarrés.
Alors que 10 000 heures de disponibilité sur un disque dur peuvent sembler longues, si vous utilisez 10 000 disques durs, cela représente une panne par heure.
Pour cette raison, Heroku préconise la création d'applications Web sans état. Comme mesure supplémentaire vers la stabilité, chaque Dyno est redémarré une fois toutes les 24 heures. Tout cela ne nécessite aucune interaction de votre part, ce qui vous permet de vous concentrer sur le développement du code de votre application.
Configuration
Une base de code donnée peut avoir de nombreux déploiements : un site de production, un site intermédiaire et un nombre illimité d'environnements locaux gérés par chaque développeur. Une application open source peut avoir des centaines ou des milliers de déploiements.
Bien qu'ils exécutent tous le même code, chacun de ces déploiements a des configurations spécifiques à l'environnement. Un exemple serait les informations d'identification pour un service externe, tel qu'Amazon S3. Les développeurs peuvent partager un compte S3, tandis que les sites de développement et de production ont chacun leurs propres clefs.
L'approche traditionnelle pour gérer ces variables de configuration consiste à les placer sous la source (dans un fichier de propriétés quelconque). Il s'agit d'un processus sujet aux erreurs et particulièrement compliqué pour les applications open source, devant souvent maintenir des branches séparées (et privées) avec des configurations spécifiques à l'application.
Une meilleure solution consiste à utiliser des variables d'environnement et à garder les clefs hors du code. Sur un hôte traditionnel ou en travaillant localement, vous pouvez définir des variables d'environnement dans votre bashrc. Sur Heroku, vous utilisez des variables de configuration ressemblant à ceci :
|
$ heroku config:set GITHUB_USERNAME=monutilisateur Adding config vars and restarting myapp... done, v12 GITHUB_USERNAME: monutilisateur $ heroku config GITHUB_USERNAME: monutilisateur OTHER_VAR: production $ heroku config:get GITHUB_USERNAME monutilisateur $ heroku config:unset GITHUB_USERNAME Unsetting GITHUB_USERNAME and restarting myapp... done, v13 |
Heroku manifeste ces variables de configuration en tant que variables d'environnement pour l'application. Ces variables d'environnement sont persistantes (elles resteront en place lors des déploiements et des redémarrages de l'application), donc à moins que vous n'ayez besoin de modifier les valeurs, vous ne devez les définir qu'une seule fois.
En utilisant ces variables de configuration, il est donc possible d'avoir deux Dynos différents contenant le même code applicatif se comportant différemment. Par exemple, l'une peut être une application de niveau production envoyant des courriels à ses utilisateurs, tandis que l'autre peut être un système de développement n'envoyant des courriels qu'aux développeurs.
Ainsi, un Dyno est un conteneur contenant notre code et notre configuration, mais comment y intégrons-nous notre code d'application ? Heroku appelle ce processus la compilation slug.
Les réalisations (Releases)
Avant de parler du processus de création d'une version déployée sur Heroku, définissons rapidement ce qu'est une version.
En ce qui concerne Heroku, une version comprend une combinaison de votre code d'application (ou slug) et de la configuration l'entourant. Par conséquent, toute modification apportée à l'un ou l'autre de ces éléments générera une nouvelle "version", pouvant être vue via la commande releases :
| heroku releases -a gladirexemple |
on obtiendra un résultat ressemblant à ceci :
|
=== gladirexemple Releases v52 Deploy e5b55f4 test@gladir.com 2014/04/28 22:24:44 v51 Deploy 5155278 test@gladir.com 2014/04/25 18:44:57 v50 Add-on add newrelic:standard test@gladir.com 2014/04/20 00:04:06 v49 Add papertrail:choklad add-on test@gladir.com 2014/04/20 00:03:00 v48 Deploy 0685e11 test@gladir.com 2014/04/19 17:53:20 v47 Deploy 823fbde test@gladir.com 2014/04/19 17:25:55 v46 Remove librato:dev add-on test@gladir.com 2014/04/17 23:42:39 |
Cette définition des versions permet de revenir aux versions précédentes de votre code et de la configuration l'entourant. Ceci est très utile si un déploiement tourne mal ou si vos modifications de configuration provoquent des problèmes imprévus.
Compilation de Slug
À partir du moment où Heroku détecte que vous poussez du code, il lancera une instance d'exécution pour compiler votre application (au tout début de Heroku, cela n'était pas nécessaire, car Rails était le seul cadre d'application Web pris en charge). De plus, les dépendances externes, telles que les gems, pourraient simplement être préinstallées sur chaque Dyno. Bien que ce soit une bonne idée, la liste des dépendances externes sur lesquelles votre code pourrait s'appuyer augmente de façon exponentielle. Au lieu d'essayer de préinstaller tous ces logiciels, Heroku s'appuie sur des outils adoptés par la communauté pour la gestion des dépendances.
Avant qu'un code soit couplé à votre Dyno ou que des dépendances soient installées, le Dyno a une image de base du logiciel préexistant. Ceci est connu en interne sous le nom de runtime car l'image devra avoir suffisamment de fonctionnalités pour exécuter votre code ou au moins installer les dépendances nécessaires pour exécuter votre code. Cette image est maintenue assez légère pour minimiser les frais généraux. Tous les logiciels de l'image de base (par exemple, cURL) sont disponibles en open source. Il s'agit d'un choix intentionnel pour maximiser la portabilité du code et pour augmenter la compatibilité avec la machine de développement d'un utilisateur. Cela inclut le système d'exploitation de base, étant et ayant toujours été une version de Linux. En gardant toutes les images de base des Dynos identiques, les mises à jour de sécurité des composantes sont effectuées rapidement par les ingénieurs Heroku et avec peu ou pas d'impact sur les applications en cours d'exécution.
Bien que certaines critiques de la plate-forme en tant que service (PaaS) impliquent ce que l'on appelle le «verrouillage du fournisseur», de telles incompatibilités dans l'écosystème indiqueraient un coût associé à l'adoption de la plate-forme. L'objectif d'Heroku est de fournir un processus de déploiement aussi fluide et transparent que possible tout en maintenant la fiabilité et la cohérence. Heroku prend en charge les logiciels open source et vous devriez en faire autant.
Donc, maintenant que Heroku a une image de base sécurisée avec des outils appropriés, et qu'il a votre code d'application, il exécute un buildpack pour déterminer exactement ce qui doit être fait pour configurer votre code à exécuter. Les buildpack sont tous open source et peuvent être bifurqués et personnalisés.
Une fois le buildpack exécuté avec succès, un instantané du produit fini (moins l'image d'exécution) est entreposé pour un accès facile ultérieurement. Ce produit est appelé Slug, et vous avez peut-être remarqué lors du déploiement que Heroku vous indiquera la taille de votre Slug. L'une des raisons de faire attention est que les slugs plus gros prennent plus de temps à être transférés sur le réseau et prennent donc plus de temps à tourner sur de nouveaux dynos.
Maintenant que votre Slug est enregistré, les dynos portant l'ancien code d'application reçoivent des commandes pour commencer à tuer leurs processus. Pendant ce temps, votre code est copié sur d'autres dynos. Une fois que l'ancienne application cesse de fonctionner, les nouveaux dynos sont mis en ligne et mis à la disposition des routeurs prêts à répondre aux demandes.
Étant donné qu'Heroku conserve une copie de votre application dans l'entreposage, si vous avez besoin d'évoluer vers plus de dynos, il peut facilement copier le Slug sur un nouveau dyno et le faire tourner. Ce type d'exécution rapide signifie que vous pouvez faire des choses comme exécuter un planificateur dans son propre dyno, et chaque fois qu'une commande est exécutée sur l'une de vos applications via la commande run, comme heroku run bash, vous l'exécutez réellement à l'intérieur d'un Dyno complètement frais et isolé. Cela vous protège contre l'exécution accidentelle de rm -rf sur votre serveur Web de production.
Maintenant que vous en savez un peu plus sur ce qui se passe réellement dans le processus de construction d'un Slug et de son exécution en tant que processus en cours d'exécution, examinons comment nous pouvons l'utiliser à notre avantage.
Mise à l'échelle ou pas
Traditionnellement, lorsque les serveurs manquent de capacité, ils sont mis à l'échelle (c'est-à-dire que les développeurs éteignent la machine et ajoutent de la RAM, un disque dur plus gros, plus de coeurs, une meilleure carte réseau,..., puis la rallument). Cela peut prendre du temps, mais au fur et à mesure qu'une application grandit dans la base d'utilisateurs, un serveur maximisera les mises à niveau et les ingénieurs n'auront d'autre choix que d'évoluer. La mise à l'échelle consiste à ajouter des serveurs supplémentaires pour la capacité plutôt qu'une capacité supplémentaire à votre serveur. C'est une excellente pratique car vous pouvez évoluer de manière illimitée, alors que la mise à l'échelle est très limitée. En règle générale, la mise à l'échelle est facile et la mise à l'échelle est difficile. Cela nécessite de fournir du nouveau matériel, de le mettre en réseau, d'installer des logiciels, de corriger et de mettre à jour ces logiciels, de créer une infrastructure d'équilibrage de charge, puis d'acheter un tas d'avertisseurs, car plus de matériel signifie plus de pannes.
Lorsque vous exécutez sur Heroku, votre application est déjà prête à évoluer, le tout sans les avertisseurs. Entreposer le code d'application compilé dans des Slug et le garder séparé de vos instances en cours d'exécution vous donne une énorme élasticité. Lorsque vous donnez la commande à Heroku, il associe votre Slug compilé à un Dyno pour vous donner plus de capacité. Cela signifie que vous pouvez faire passer votre application de 2 dynos à 50 Dynos avec une seule commande (c'est 26 Go de mémoire si vous faites le calcul à la maison). Ainsi, si votre grand lancement de produit V3 approche dans quelques jours, vous pouvez dormir sur vos deux oreilles en sachant qu'une capacité supplémentaire est disponible si vous en avez besoin, mais vous n'êtes pas obligé de l'utiliser.
Cette capacité à évoluer n'est pas accidentelle et s'accompagne de nombreux avantages secondaires. Comme nous l'avons mentionné précédemment, cela rend votre application plus tolérante aux erreurs matérielles. Par exemple, un seul serveur peut exécuter plusieurs Dynos lorsque la mémoire tombe en panne. Normalement, ce serait un problème important dans les environnements traditionnels, mais le gestionnaire de Dynos est capable de repérer l'instance morte et de migrer les Dynos ailleurs en un clin d'oeil.
Un autre avantage de l'architecture Dyno est l'isolation. Chaque Dyno est un conteneur complètement séparé de tous les autres, il n'y a donc aucune possibilité qu'une autre application accède à votre code d'application, ou souffre parce qu'un Dyno voyou devient incontrôlable et utilise tout le microprocesseur sur l'instance hôte. En ce qui vous concerne, le développeur, ce sont toutes des entités distinctes.
Résistance à l'érosion
Un avantage non technique de l'architecture Dyno est la résistance à l'érosion. L'érosion logicielle est ce qui arrive à votre application à votre insu ou sans votre consentement au fil du temps : elle fonctionnait à un moment donné, mais ne fonctionne plus. Imaginez qu'une faille de sécurité soit découverte dans le système d'exploitation que votre application exécute. Si vous ne corrigez pas la vulnérabilité rapidement, les attaquants peuvent profiter de l'exploit et accéder à votre code, ou pire. Bien que vous n'ayez pas intentionnellement placé la vulnérabilité dans votre application, ne rien faire érode la capacité de votre application à effectuer son travail en toute sécurité.
Lorsque votre application rencontre une erreur due à une érosion du logiciel, vous devez investir de l'énergie pour diagnostiquer et résoudre le problème. L'érosion est un problème dont souffrent toutes les applications, quelle que soit leur taille, et que de nombreuses applications ont du mal à gérer si elles sont laissées trop longtemps.
L'érosion logicielle peut être considérée principalement comme le fait que votre application devient «obsolète». Votre application se compose de nombreuses pièces mobiles, dont certaines sont constamment mises à jour par les communautés du monde entier. Par exemple, vous avez des mises à niveau du système d'exploitation, des correctifs du noyau et des mises à jour des logiciels d'infrastructure (par exemple, Apache, MySQL, SSH, OpenSSL) pour corriger les vulnérabilités de sécurité ou ajouter des fonctionnalités. Tous ces éléments doivent être tenus à jour et sont souvent laissés de côté en raison de l'effort requis pour le faire.
Étant donné que tous les Dynos sont dérivés de la même image, il est garanti qu'il s'agit de la plus récente et de la meilleure image que l'équipe des opérations Heroku ait créée au moment de la création du Dyno. Ces images sont soumises à de longs processus de test et d'évaluation avant d'être mises en production.
Une fois que votre application est opérationnelle, ses Dynos sont automatiquement cyclés silencieusement une fois par jour pour s'assurer que la version d'image dyno qu'ils exécutent est la dernière version d'exécution disponible (votre Slug restera le même). Vous pouvez vérifier vos journaux d'application pour voir que le processus de cycle a eu lieu. Par conséquent, si vous deviez déployer une application sur Heroku et la laisser plusieurs mois, elle ne serait pas plus obsolète qu'une application déployée il y a un jour.
Travail et traitement en arrière-plan
Tous les Dynos n'ont pas besoin d'être ceux répondant aux requêtes HTTP. Un Dyno peut être considéré comme un conteneur pour les processus UNIX. Dynos peut donc gérer une variété de types de tâches différents. Alors que vos Dynos Web traiteront toutes vos requêtes Web, d'autres Dynos peuvent être chargés d'effectuer une sorte de traitement en arrière-plan, qu'il s'agisse de gérer une file d'attente de tâches, d'envoyer des courriels ou de gérer des déclencheurs d'événements basés sur un calendrier. La liste des possibilités ici est infinie. Cependant, notez que ces Dynos ont toujours un coût attaché et devront donc être pris en compte lors de la planification de l'architecture de votre application et de la projection des coûts.
Un cas d'utilisation très courant d'un Dyno de travail consiste à traiter les courriels sortants. Lorsqu'un utilisateur s'inscrit sur un site Web, il reçoit généralement un courriel de confirmation ou de bienvenue. Si vous envoyez ce message lors de votre requête Web, votre utilisateur doit attendre la fin de la transaction par courriel avant de pouvoir accéder à la page suivante. Cela rend votre site lent et peut en fait entraîner des délais d'attente. En plaçant ces informations dans une file d'attente légère et en envoyant ce courriel à partir d'un travailleur en arrière-plan, vous pouvez améliorer la vitesse de votre serveur Web tout en augmentant sa capacité.
Vous pouvez également programmer des tâches ponctuelles en arrière-plan avec le planificateur de Heroku. C'est comme un travailleur, mais n'exécute qu'une commande spécifique pour un intervalle donné. Ceci est très similaire à la façon dont vous pouvez programmer une tâche à exécuter avec cron. Les tâches exécutées par le planificateur ne sont facturées que pour le temps qu'elles utilisent, donc si une tâche ne prend que 16 minutes, votre compte ne sera débité que de 16 dyno/minutes.
Maintenant que nous avons notre pile Web et notre infrastructure de travail sous contrôle, examinons les autres fonctionnalités fournies par Heroku pour aider les développeurs.
Autres services
Nous avons discuté des principaux composantes de la plate-forme Heroku maintenant votre code d'application opérationnel, alors parlons maintenant de certains des services de support constituant les parties de la plateforme que l'utilisateur ne voit pas. Ceux-ci incluent le Logplex, les systèmes de déploiement et les divers modules complémentaires que vous pouvez attacher à votre application pour fournir des services auxiliaires.
Le Logplex
Chaque application génère une sortie, qu'il s'agisse de contenu via des pages Web générées ou de données via une API externe. Les fichiers journaux sur le serveur constituent une autre forme de sortie créée par les applications. Si vous avez exécuté un serveur Web de production, vous saurez que rien ne remplace un accès facile aux journaux.
Dans une configuration de serveur Web traditionnelle, de nombreux fichiers journaux sont créés. Tout d'abord, vous avez les fichiers journaux système réguliers étant générés par le système d'exploitation lui-même. Ensuite, vous avez les fichiers journaux créés par les services exécutés sur le serveur, tels que les journaux Apache (serveur Web) ou les journaux PostgreSQL (serveur de base de données). Enfin, vous disposez de vos propres fichiers journaux d'application.
En règle générale, tous ces fichiers sont écrits sur le disque local de leurs serveurs respectifs avant que des processus tels que le logrotate d'UNIX n'arrivent et archivent les fichiers à un autre emplacement, généralement en les compressant. Un administrateur système respectable à ce stade archivera périodiquement ces fichiers journaux dans un emplacement différent pour une interrogation ou une référence ultérieure.
L'un des inconvénients des fichiers journaux est qu'ils affectent la façon dont nous examinons les données au sein d'un système. Les journaux des applications et du système contiennent un flux d'informations ordonnées dans le temps sur ce qui se passe dans votre application à un moment donné. Bien que ce flux soit constant et continu, la façon dont ils sont généralement représentés dans les fichiers journaux tend à impliquer qu'il y a un début et une fin. Pour remédier à cette perception erronée, Heroku a développé le Logplex.
Le Logplex est un outil open source remplaçant le concept de fichier journal en fournissant un flux constant d'informations provenant de votre application sans début ni fin. De plus, ce flux contient une seule source canonique d'informations provenant de chaque partie de la pile, qu'il s'agisse des routeurs, de vos Dynos, ... Cela signifie qu'en tant que développeur, vous pouvez accéder à ce flux à tout moment et voir toute l'activité de votre application en un seul endroit en même temps. Par conséquent, Heroku ne fournit pas de fichiers journaux en soi, mais propose ce flux. Si vous souhaitez capturer ces informations, Heroku vous permet de drainer ces informations dans un magasin externe.
Bases de données et autres modules complémentaires
Jusqu'à présent, nous avons expliqué comment Heroku peut prendre votre code d'application et l'exécuter dans l'infonuagique, ce qui vous permet d'évoluer pour répondre aux besoins de votre application. Cependant, nous n'avons pas expliqué comment Heroku fournit tous les autres services dont une application Web moderne a besoin.
Il n'est pas rare de nos jours qu'une application nécessite plus que du code. Les bases de données sont une exigence extrêmement courante, tout comme les services externes tels que le SMTP de courriel ou les services de mise en cache tels que Memcached. De nombreux autres services deviennent également plus courants : Redis, AMQP, la recherche de texte intégral, le traitement d'images et de vidéos, les bases de données NoSQL et les SMS sont tous de plus en plus utilisés quotidiennement.
Alors, comment Heroku fournit-il ces services ? En bref, Heroku ne le fait pas. Dès le début, Heroku a mis en place le programme Add-on, étant un processus par lequel un fournisseur externe peut développer un service, puis le mettre à disposition de la plate-forme via l'API des modules complémentaires.
En utilisant cette approche, il a été possible de constituer au fil du temps une bibliothèque de modules complémentaires pouvant fournir presque tous les services auxiliaires qu'une application pourrait avoir besoin de consommer. Étant donné que la plupart de ces services sont connectés via une configuration simple, l'effort requis pour utiliser ces services avec leur propre application est très faible.
L'un des modules complémentaires les plus populaires est celui fourni par Heroku lui-même. Appelé Heroku Postgres, ce module complémentaire fournit des services PostgreSQL à toutes les applications.
Lors du déploiement initial, Heroku détectera la langue et le type de votre application. Si vous déployez à l'aide d'un cadre d'application Web populaire basé sur une base de données, tel que Ruby on Rails, Heroku provisionnera et configurera le module complémentaire PostgreSQL pour votre application. Cela signifie que le déploiement d'une application basée sur une base de données est aussi simple que de transmettre votre code à Heroku et d'exécuter une migration.
Cependant, tout le monde n'a pas besoin de PostgreSQL ; par exemple, vous voudrez peut-être utiliser MySQL ou une autre forme de base de données avec votre code d'application. Bien que Heroku recommande PostgreSQL, la plupart des alternatives peuvent être trouvées dans la bibliothèque de modules complémentaires (par exemple, le service de base de données relationnelle [RDS] d'Amazon ou le service ClearDB de MySQL).
Systèmes de déploiement
L'une des parties les plus souvent négligées de la plate-forme Heroku est le système de déploiement. Cette partie incroyablement complexe de Heroku est ce qui prend votre code et le transforme en une version adaptée à la plate-forme pouvant être augmentée et réduite instantanément et à volonté. De plus, le système de déploiement modifie également votre application pour l'adapter à la plateforme, en injectant divers composants et configurations pour vous rendre la vie, en tant que développeur, beaucoup plus facile et plus simple.
Tous les déploiements Heroku sont effectués via l'utilisation du système de contrôle de source Git. En poussant votre code vers Heroku, vous demandez à la plateforme de déployer votre code.
Ainsi, pour commencer, Heroku détient une copie du dépôt Git pour chaque application de la plateforme. Lorsque vous poussez dans la branche principale, vous lancez un déploiement et Heroku commencera à préparer votre dépôt pour le déploiement. Vous pouvez pousser dans d'autres branches si vous le souhaitez, mais celles-ci ne seront stockées que sur Heroku et ne seront pas déployées, car la plate-forme ne déploiera jamais que la branche principale. Cependant, il est possible de pousser depuis une branche de fonctionnalité distante telle que la staging vers le master de Heroku.
Lorsque Heroku reçoit votre code via un push, plusieurs choses se produisent. Heroku prend votre code et l'identifie (par exemple, en tant qu'application Ruby on Rails, Django, Java,...). Une fois identifié, il exécute le code via un buildpack. Les Buildpacks sont des programmes spéciaux comprenant la structure de votre application et ses conventions appropriées. En comprenant la structure de votre application, ces buildpacks sont capables d'apporter les modifications nécessaires au bon fonctionnement de votre application sur la plate-forme. Cela peut inclure une variété de modifications telles que la vérification des paramètres de configuration, l'injection de plugiciels de structure d'application ou l'écrasement des fichiers de configuration tels que les configurations de base de données.
Les Buildpacks sont fournis par l'équipe des opérations Heroku, ainsi que par d'autres développeurs open source. N'importe qui peut écrire son propre buildpack pour ses propres moyens.
Une fois votre application préparée, elle est entreposée dans un Slug. Ce Slug est entreposé dans un magasin de fichiers en attente d'une demande de déploiement, comme mentionné précédemment. Dans la plupart des cas, le Slug est immédiatement déployé sur de nouveaux Dynos, remplaçant ceux que vous avez déjà en cours d'exécution.
La plupart des cas d'utilisation ont déjà un buildpack prédéfini par l'équipe des opérations Heroku. Par exemple, si vous deviez pousser une application Django vers Heroku, le dur travail de compilation de Slug est fait pour vous, et vous n'avez rien de plus à faire. Si vous souhaitez pousser quelque chose un peu hors des sentiers battus ou si vous avez besoin de personnaliser la façon dont vos déploiements d'applications sont gérés, vous pouvez désormais écrire vos propres buildpacks personnalisés et demander à la plate-forme de les utiliser au lieu de la valeur par défaut.